Database Explorer
Explorer nabízí intuitivní a efektivní způsob práce s databází. Stará se automaticky o vazby mezi tabulkami a optimalizaci dotazů, takže se můžete soustředit na svou aplikaci. Funguje ihned bez nastavování. Pokud potřebujete plnou kontrolu nad SQL dotazy, můžete využít SQL přístup.
- Práce s daty je přirozená a snadno pochopitelná
- Generuje optimalizované SQL dotazy, které načítají pouze potřebná data
- Umožňuje snadný přístup k souvisejícím datům bez nutnosti psát JOIN dotazy
- Funguje okamžitě bez jakékoliv konfigurace či generování entit
S Explorerem začnete voláním metody table() objektu Nette\Database\Explorer (detaily k připojení
najdete v kapitole Připojení a
konfigurace):
$books = $explorer->table('book'); // 'book' je jméno tabulky
Metoda vrací objekt Selection, který
představuje SQL dotaz. Na tento objekt můžeme navazovat další metody pro filtrování a řazení výsledků. Dotaz se
sestaví a spustí až ve chvíli, kdy začneme požadovat data. Například procházením cyklem foreach. Každý
řádek je reprezentován objektem ActiveRow:
foreach ($books as $book) {
echo $book->title; // výpis sloupce 'title'
echo $book->author_id; // výpis sloupce 'author_id'
}
Explorer zásadním způsobem usnadňuje práci s vazbami mezi tabulkami. Následující příklad ukazuje, jak snadno můžeme vypsat data z provázaných tabulek (knihy a jejich autoři). Všimněte si, že nemusíme psát žádné JOIN dotazy, Nette je vytvoří za nás:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Kniha: ' . $book->title;
echo 'Autor: ' . $book->author->name; // vytvoří JOIN na tabulku 'author'
}
Nette Database Explorer optimalizuje dotazy, aby byly co nejefektivnější. Výše uvedený příklad provede pouze dva SELECT dotazy, bez ohledu na to, jestli zpracováváme 10 nebo 10 000 knih.
Navíc Explorer sleduje, které sloupce se v kódu používají, a načítá z databáze pouze ty, čímž šetří další výkon. Toto chování je plně automatické a adaptivní. Pokud později upravíte kód a začnete používat další sloupce, Explorer automaticky upraví dotazy. Nemusíte nic nastavovat, ani přemýšlet nad tím, které sloupce budete potřebovat – nechte to na Nette.
Filtrování a řazení
Třída Selection poskytuje metody pro filtrování a řazení výběru dat.
where($condition, ...$params) |
Přidá podmínku WHERE. Více podmínek je spojeno operátorem AND |
whereOr(array $conditions) |
Přidá skupinu podmínek WHERE spojených operátorem OR |
wherePrimary($value) |
Přidá podmínku WHERE podle primárního klíče |
order($columns, ...$params) |
Nastaví řazení ORDER BY |
select($columns, ...$params) |
Specifikuje sloupce, které se mají načíst |
limit($limit, $offset = null) |
Omezí počet řádků (LIMIT) a volitelně nastaví OFFSET |
page($page, $itemsPerPage, &$numOfPages = null) |
Nastaví stránkování |
group($columns, ...$params) |
Seskupí řádky (GROUP BY) |
having($condition, ...$params) |
Přidá podmínku HAVING pro filtrování seskupených řádků |
Metody lze řetězit (tzv. fluent interface):
$table->where(...)->order(...)->limit(...).
V těchto metodách můžete také používat speciální notaci pro přístup k datům ze souvisejících tabulek.
Escapování a identifikátory
Metody automaticky escapují parametry a uvozují identifikátory (názvy tabulek a sloupců), čímž zabraňuje SQL injection. Pro správné fungování je nutné dodržovat několik pravidel:
- Klíčová slova, názvy funkcí, procedur apod. pište velkými písmeny.
- Názvy sloupců a tabulek pište malými písmeny.
- Řetězce vždy dosazujte přes parametry.
where('name = ' . $name); // KRITICKÁ ZRANITELNOST: SQL injection
where('name LIKE "%search%"'); // ŠPATNĚ: komplikuje automatické uvozování
where('name LIKE ?', '%search%'); // SPRÁVNĚ: hodnota dosazená přes parametr
where('name like ?', $name); // ŠPATNĚ: vygeneruje: `name` `like` ?
where('name LIKE ?', $name); // SPRÁVNĚ: vygeneruje: `name` LIKE ?
where('LOWER(name) = ?', $value);// SPRÁVNĚ: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtruje výsledky pomocí podmínek WHERE. Její silnou stránkou je inteligentní práce s různými typy hodnot a automatická volba SQL operátorů.
Základní použití:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Díky automatické detekci vhodných operátorů nemusíme řešit různé speciální případy. Nette je vyřeší za nás:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// lze použít i zástupný otazník bez operátoru:
$table->where('id ?', 1); // WHERE `id` = 1
Metoda správně zpracovává i záporné podmínky a prázdné pole:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- nic nenalezne
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- nalezne vše
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- nalezne vše
// $table->where('NOT id ?', $ids); Pozor - tato syntaxe není podporovaná
Jako parametr můžeme předat také výsledek z jiné tabulky – vytvoří se poddotaz:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Podmínky můžeme předat také jako pole, jehož položky se spojí pomocí AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
V poli můžeme použít dvojice klíč ⇒ hodnota a Nette opět automaticky zvolí správné operátory:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
V poli můžeme kombinovat SQL výrazy se zástupnými otazníky a více parametry. To je vhodné pro komplexní podmínky s přesně definovanými operátory:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // dva parametry předáme jako pole
]);
Vícenásobné volání where() podmínky automaticky spojuje pomocí AND.
whereOr (array $parameters): static
Podobně jako where() přidává podmínky, ale s tím rozdílem, že je spojuje pomocí OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
I zde můžeme použít komplexnější výrazy:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Přidá podmínku pro primární klíč tabulky:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Pokud má tabulka kompozitní primární klíč (např. foo_id, bar_id), předáme jej
jako pole:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Určuje pořadí, v jakém budou řádky vráceny. Můžeme řadit podle jednoho či více sloupců, v sestupném či vzestupném pořadí, nebo podle vlastního výrazu:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Specifikuje sloupce, které se mají vrátit z databáze. Ve výchozím stavu Nette Database Explorer vrací pouze ty sloupce,
které se reálně použijí v kódu. Metodu select() tak používáme v případech, kdy potřebujeme vrátit
specifické výrazy:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Aliasy definované pomocí AS jsou pak dostupné jako vlastnosti objektu ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // přístup k aliasu
}
limit (?int $limit, ?int $offset = null): static
Omezuje počet vrácených řádků (LIMIT) a volitelně umožňuje nastavit offset:
$table->limit(10); // LIMIT 10 (vrátí prvních 10 řádků)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Pro stránkování je vhodnější použít metodu page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Usnadňuje stránkování výsledků. Přijímá číslo stránky (počítané od 1) a počet položek na stránku. Volitelně lze předat referenci na proměnnou, do které se uloží celkový počet stránek:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, numOfPages: $numOfPages);
echo "Celkem stránek: $numOfPages";
group (string $columns, …$parameters): static
Seskupuje řádky podle zadaných sloupců (GROUP BY). Používá se obvykle ve spojení s agregačními funkcemi:
// Spočítá počet produktů v každé kategorii
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Nastavuje podmínku pro filtrování seskupených řádků (HAVING). Lze ji použít ve spojení s metodou
group() a agregačními funkcemi:
// Nalezne kategorie, které mají více než 100 produktů
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Čtení dat
Pro čtení dat z databáze máme k dispozici několik užitečných metod:
foreach ($table as $key => $row) |
Iteruje přes všechny řádky, $key je hodnota primárního klíče, $row je objekt ActiveRow |
$row = $table->get($key) |
Vrátí jeden řádek podle primárního klíče |
$row = $table->fetch() |
Vrátí aktuální řádek a posune ukazatel na další |
$array = $table->fetchPairs() |
Vytvoří asociativní pole z výsledků |
$array = $table->fetchAll() |
Vrátí všechny řádky jako pole |
count($table) |
Vrátí počet řádků v objektu Selection |
Objekt ActiveRow je určen pouze pro čtení. To znamená, že nelze měnit hodnoty jeho properties. Toto omezení zajišťuje konzistenci dat a zabraňuje neočekávaným vedlejším efektům. Data se načítají z databáze a jakákoliv změna by měla být provedena explicitně a kontrolovaně.
foreach – iterace přes všechny řádky
Nejsnazší způsob, jak vykonat dotaz a získat řádky, je iterováním v cyklu foreach. Automaticky spouští
SQL dotaz.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key je hodnota primárního klíče, $book je ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Vykoná SQL dotaz a vrátí řádek podle primárního klíče, nebo null, pokud neexistuje.
$book = $explorer->table('book')->get(123); // vrátí ActiveRow s ID 123 nebo null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Vrací řádek a posune interní ukazatel na další. Pokud už neexistují další řádky, vrací null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Vrátí výsledky jako asociativní pole. První argument určuje název sloupce, který se použije jako klíč v poli, druhý argument určuje název sloupce, který se použije jako hodnota:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Pokud uvedeme pouze první parametr, bude hodnotou celý řádek, tedy objekt ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
V případě duplicitních klíčů se použije hodnota z posledního řádku. Při použití null jako klíče
bude pole indexováno numericky od nuly (pak ke kolizím nedochází):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternativně můžete jako parametr uvést callback, který bude pro každý řádek vracet buď samotnou hodnotu, nebo dvojici klíč-hodnota.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['První kniha (Jan Novák)', ...]
// Callback může také vracet pole s dvojicí klíč & hodnota:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['První kniha' => 'Jan Novák', ...]
fetchAll(): array
Vrátí všechny řádky jako asociativní pole objektů ActiveRow, kde klíče jsou hodnoty
primárních klíčů.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Metoda count() bez parametru vrací počet řádků v objektu Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // alternativa
Pozor, count() s parametrem provádí agregační funkci COUNT v databázi, viz níže.
ActiveRow::toArray(): array
Převede objekt ActiveRow na asociativní pole, kde klíče jsou názvy sloupců a hodnoty jsou
odpovídající data.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray bude ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Agregace
Třída Selection poskytuje metody pro snadné provádění agregačních funkcí (COUNT, SUM, MIN, MAX,
AVG atd.).
count($expr) |
Spočítá počet řádků |
min($expr) |
Vrátí minimální hodnotu ve sloupci |
max($expr) |
Vrátí maximální hodnotu ve sloupci |
sum($expr) |
Vrátí součet hodnot ve sloupci |
aggregation($function) |
Umožňuje provést libovolnou agregační funkci. Např. AVG(), GROUP_CONCAT() |
count (string $expr): int
Provede SQL dotaz s funkcí COUNT a vrátí výsledek. Metoda se používá k zjištění, kolik řádků odpovídá určité podmínce:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Pozor, count() bez parametru pouze vrací počet řádků v objektu Selection.
min (string $expr) a max(string $expr)
Metody min() a max() vrací minimální a maximální hodnotu ve specifikovaném sloupci nebo
výrazu:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr): mixed
Vrací součet hodnot ve specifikovaném sloupci nebo výrazu:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null): mixed
Umožňuje provést libovolnou agregační funkci.
// průměrná cena produktů v kategorii
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// spojí štítky produktu do jednoho řetězce
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Pokud potřebujeme agregovat výsledky, které už samy o sobě vzešly z nějaké agregační funkce a seskupení (např.
SUM(hodnota) přes seskupené řádky), jako druhý argument uvedeme agregační funkci, která se má na tyto
mezivýsledky aplikovat:
// Vypočítá celkovou cenu produktů na skladě pro jednotlivé kategorie a poté sečte tyto ceny dohromady.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
V tomto příkladu nejprve vypočítáme celkovou cenu produktů v každé kategorii
(SUM(price * stock) AS category_total) a seskupíme výsledky podle category_id. Poté použijeme
aggregation('SUM(category_total)', 'SUM') k sečtení těchto mezisoučtů category_total. Druhý
argument 'SUM' říká, že se má na mezivýsledky aplikovat funkce SUM.
Insert, Update & Delete
Nette Database Explorer zjednodušuje vkládání, aktualizaci a mazání dat. Všechny uvedené metody v případě vyhodí
výjimku Nette\Database\DriverException.
Selection::insert (iterable $data)
Vloží nové záznamy do tabulky.
Vkládání jednoho záznamu:
Nový záznam předáme jako asociativní pole nebo iterable objekt (například ArrayHash používaný ve formulářích), kde klíče odpovídají názvům sloupců v tabulce.
Pokud má tabulka definovaný primární klíč, metoda vrací objekt ActiveRow, který se znovunačte
z databáze, aby se zohlednily případné změny provedené na úrovni databáze (triggery, výchozí hodnoty sloupců,
výpočty auto-increment sloupců). Tím je zajištěna konzistence dat a objekt vždy obsahuje aktuální data z databáze.
Pokud tabulka nemá primární klíč, neexistuje identifikovatelný řádek a metoda vrací null.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row je instance ActiveRow a obsahuje kompletní data vloženého řádku,
// včetně automaticky generovaného ID a případných změn provedených triggery
echo $row->id; // Vypíše ID nově vloženého uživatele
echo $row->created_at; // Vypíše čas vytvoření, pokud je nastaven triggerem
Vkládání více záznamů najednou:
Metoda insert() umožňuje vložit více záznamů pomocí jednoho SQL dotazu. V tomto případě vrací počet
vložených řádků.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows bude 2
Jako parametr lze také předat objekt Selection s výběrem dat.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Vkládání speciálních hodnot:
Jako hodnoty můžeme předávat i soubory, objekty DateTime nebo SQL literály:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // převede na databázový formát
'avatar' => fopen('image.jpg', 'rb'), // vloží binární obsah souboru
'uuid' => $explorer::literal('UUID()'), // zavolá funkci UUID()
]);
Selection::update (iterable $data): int
Aktualizuje řádky v tabulce podle zadaného filtru. Vrací počet skutečně změněných řádků.
Měněné sloupce předáme jako asociativní pole nebo iterable objekt (například ArrayHash používaný ve formulářích), kde klíče odpovídají názvům sloupců v tabulce:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Pro změnu číselných hodnot můžeme použít operátory += a -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // zvýší hodnotu sloupce 'points' o 1
'coins-=' => 1, // sníží hodnotu sloupce 'coins' o 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Maže řádky z tabulky podle zadaného filtru. Vrací počet smazaných řádků.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Při volání update() a delete() nezapomeňte pomocí where()
specifikovat řádky, které se mají upravit/smazat. Pokud where() nepoužijete, operace se provede na celé
tabulce!
ActiveRow::update (iterable $data): bool
Aktualizuje data v databázovém řádku reprezentovaném objektem ActiveRow. Jako parametr přijímá iterable
s daty, která se mají aktualizovat (klíče jsou názvy sloupců). Pro změnu číselných hodnot můžeme použít operátory
+= a -=:
Po provedení aktualizace se ActiveRow automaticky znovu načte z databáze, aby se zohlednily případné změny
provedené na úrovni databáze (např. triggery). Metoda vrací true pouze pokud došlo ke skutečné změně dat.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // zvýšíme počet zobrazení
]);
echo $article->views; // Vypíše aktuální počet zobrazení
Tato metoda aktualizuje pouze jeden konkrétní řádek v databázi. Pro hromadnou aktualizaci více řádků použijte metodu Selection::update().
ActiveRow::delete(): int
Smaže řádek z databáze, který je reprezentován objektem ActiveRow. Vrací počet smazaných řádků, což
by mělo být 1.
$book = $explorer->table('book')->get(1);
$book->delete(); // Smaže knihu s ID 1
Tato metoda maže pouze jeden konkrétní řádek v databázi. Pro hromadné smazání více řádků použijte metodu Selection::delete().
Vazby mezi tabulkami
V relačních databázích jsou data rozdělena do více tabulek a navzájem propojená pomocí cizích klíčů. Nette Database Explorer přináší revoluční způsob, jak s těmito vazbami pracovat – bez psaní JOIN dotazů a nutnosti cokoliv konfigurovat nebo generovat.
Pro ilustraci práce s vazbami použijeme příklad databáze knih (najdete jej na GitHubu). V databázi máme tabulky:
author– spisovatelé a překladatelé (sloupceid,name,web,born)book– knihy (sloupceid,author_id,translator_id,title,sequel_id)tag– štítky (sloupceid,name)book_tag– vazební tabulka mezi knihami a štítky (sloupcebook_id,tag_id)
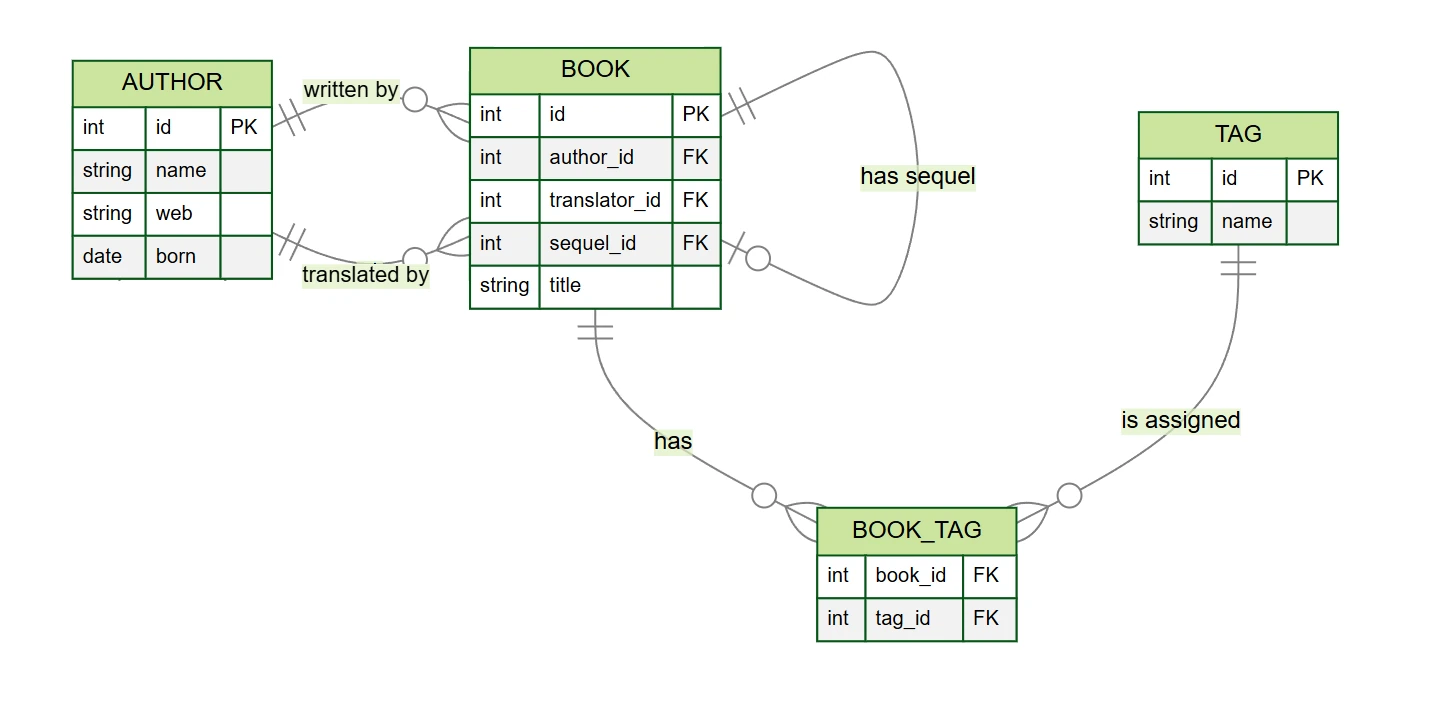
V našem příkladu databáze knih najdeme několik typů vztahů (byť model je zjednodušený oproti realitě):
- One-to-many (1:N) – každá kniha má jednoho autora, autor může napsat několik knih
- Zero-to-many (0:N) – kniha může mít překladatele, překladatel může přeložit několik knih
- Zero-to-one (0:1) – kniha může mít další díl
- Many-to-many (M:N) – kniha může mít několik tagů a tag může být přiřazen několika knihám
V těchto vztazích vždy existuje tabulka nadřazená a podřízená. Například ve vztahu mezi autorem a knihou je tabulka
author nadřazená a book podřízená – můžeme si to představit tak, že kniha vždy
„patří“ nějakému autorovi. To se projevuje i ve struktuře databáze: podřízená tabulka book obsahuje
cizí klíč author_id, který odkazuje na nadřazenou tabulku author.
Potřebujeme-li vypsat knihy včetně jmen jejich autorů, máme dvě možnosti. Buď data získáme jediným SQL dotazem pomocí JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Nebo načteme data ve dvou krocích – nejprve knihy a pak jejich autory – a potom je v PHP poskládáme:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- ids autorů získaných knih
Druhý přístup je ve skutečnosti efektivnější, i když to může být překvapivé. Data jsou načtena pouze jednou a mohou být lépe využita v cache. Právě tímto způsobem pracuje Nette Database Explorer – vše řeší pod povrchem a vám nabízí elegantní API:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'title: ' . $book->title;
echo 'written by: ' . $book->author->name; // $book->author je záznam z tabulky 'author'
echo 'translated by: ' . $book->translator?->name;
}
Přístup k nadřazené tabulce
Přístup k nadřazené tabulce je přímočarý. Jde o vztahy jako kniha má autora nebo kniha může mít
překladatele. Související záznam získáme přes property objektu ActiveRow – její název odpovídá názvu sloupce
s cizím klíčem bez id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // najde autora podle sloupce author_id
echo $book->translator?->name; // najde překladatele podle translator_id
Když přistoupíme k property $book->author, Explorer v tabulce book hledá sloupec, jehož
název obsahuje řetězec author (tedy author_id). Podle hodnoty v tomto sloupci načte odpovídající
záznam z tabulky author a vrátí jej jako ActiveRow. Podobně funguje i
$book->translator, který využije sloupec translator_id. Protože sloupec translator_id
může obsahovat null, použijeme v kódu operátor ?->.
Alternativní cestu nabízí metoda ref(), která přijímá dva argumenty, název cílové tabulky a název
spojovacího sloupce, a vrací instanci ActiveRow nebo null:
echo $book->ref('author', 'author_id')->name; // vazba na autora
echo $book->ref('author', 'translator_id')->name; // vazba na překladatele
Metoda ref() se hodí, pokud nelze použít přístup přes property, protože tabulka obsahuje sloupec se
stejným názvem (tj. author). V ostatních případech je doporučeno používat přístup přes property, který
je čitelnější.
Explorer automaticky optimalizuje databázové dotazy. Když procházíme knihy v cyklu a přistupujeme k jejich souvisejícím záznamům (autorům, překladatelům), Explorer negeneruje dotaz pro každou knihu zvlášť. Místo toho provede pouze jeden SELECT pro každý typ vazby, čímž výrazně snižuje zátěž databáze. Například:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Tento kód zavolá pouze tyto tři bleskové dotazy do databáze:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id ze sloupce author_id vybraných knih
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id ze sloupce translator_id vybraných knih
Logika dohledávání spojovacího sloupce je dána implementací Conventions. Doporučujeme použití DiscoveredConventions, které analyzuje cizí klíče a umožňuje jednoduše pracovat s existujícími vztahy mezi tabulkami.
Přístup k podřízené tabulce
Přístup k podřízené tabulce funguje v opačném směru. Nyní se ptáme jaké knihy napsal tento autor nebo
přeložil tento překladatel. Pro tento typ dotazu používáme metodu related(), která vrátí
Selection se souvisejícími záznamy. Podívejme se na příklad:
$author = $explorer->table('author')->get(1);
// Vypíše všechny knihy od autora
foreach ($author->related('book.author_id') as $book) {
echo "Napsal: $book->title";
}
// Vypíše všechny knihy, které autor přeložil
foreach ($author->related('book.translator_id') as $book) {
echo "Přeložil: $book->title";
}
Metoda related() přijímá popis spojení jako jeden argument s tečkovou notací nebo jako dva samostatné
argumenty:
$author->related('book.translator_id'); // jeden argument
$author->related('book', 'translator_id'); // dva argumenty
Explorer dokáže automaticky detekovat správný spojovací sloupec na základě názvu nadřazené tabulky. V tomto
případě se spojuje přes sloupec book.author_id, protože název zdrojové tabulky je author:
$author->related('book'); // použije book.author_id
Pokud by existovalo více možných spojení, Explorer vyhodí výjimku AmbiguousReferenceKeyException.
Metodu related() můžeme samozřejmě použít i při procházení více záznamů v cyklu a Explorer
i v tomto případě automaticky optimalizuje dotazy:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' napsal:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Tento kód vygeneruje pouze dva bleskové SQL dotazy:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id vybraných autorů
Vazba Many-to-many
Pro vazbu many-to-many (M:N) je potřeba existence vazební tabulky (v našem případě book_tag), která
obsahuje dva sloupce s cizími klíči (book_id, tag_id). Každý z těchto sloupců odkazuje na
primární klíč jedné z propojovaných tabulek. Pro získání souvisejících dat nejprve získáme záznamy z vazební
tabulky pomocí related('book_tag') a dále pokračujeme k cílovým datům:
$book = $explorer->table('book')->get(1);
// vypíše názvy tagů přiřazených ke knize
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // vypíše název tagu přes vazební tabulku
}
$tag = $explorer->table('tag')->get(1);
// nebo opačně: vypíše názvy knih označených tímto tagem
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // vypíše název knihy
}
Explorer opět optimalizuje SQL dotazy do efektivní podoby:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id vybraných knih
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id tagů nalezených v book_tag
Dotazování přes související tabulky
V metodách where(), select(), order() a group() můžeme používat
speciální notace pro přístup k sloupcům z jiných tabulek. Explorer automaticky vytvoří potřebné JOINy.
Tečková notace (nadřazená_tabulka.sloupec) se používá pro vztah 1:N z pohledu podřízené
tabulky:
$books = $explorer->table('book');
// Najde knihy, jejichž autor má jméno začínající na 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Seřadí knihy podle jména autora sestupně
$books->order('author.name DESC');
// Vypíše název knihy a jméno autora
$books->select('book.title, author.name');
Dvojtečková notace (:podřízená_tabulka.sloupec) se používá pro vztah 1:N z pohledu nadřazené
tabulky:
$authors = $explorer->table('author');
// Najde autory, kteří napsali knihu s 'PHP' v názvu
$authors->where(':book.title LIKE ?', '%PHP%');
// Spočítá počet knih pro každého autora
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
Ve výše uvedeném příkladu s dvojtečkovou notací (:book.title) není specifikován sloupec s cizím
klíčem. Explorer automaticky detekuje správný sloupec na základě názvu nadřazené tabulky. V tomto případě se spojuje
přes sloupec book.author_id, protože název zdrojové tabulky je author. Pokud by existovalo více
možných spojení, Explorer vyhodí výjimku AmbiguousReferenceKeyException.
Spojovací sloupec lze explicitně uvést v závorce:
// Najde autory, kteří přeložili knihu s 'PHP' v názvu
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Notace lze řetězit pro přístup přes více tabulek:
// Najde autory knih označených tagem 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Rozšíření podmínek pro JOIN
Metoda joinWhere() rozšiřuje podmínky, které se uvádějí při propojování tabulek v SQL za klíčovým
slovem ON.
Dejme tomu, že chceme najít knihy přeložené konkrétním překladatelem:
// Najde knihy přeložené překladatelem jménem 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
V podmínce joinWhere() můžeme používat stejné konstrukce jako v metodě where() –
operátory, zástupné otazníky, pole hodnot či SQL výrazy.
Pro složitější dotazy s více JOINy můžeme definovat aliasy tabulek:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Všimněte si, že zatímco metoda where() přidává podmínky do klauzule WHERE, metoda
joinWhere() rozšiřuje podmínky v klauzuli ON při spojování tabulek.