Database Explorer
Explorer offre un modo intuitivo ed efficiente di lavorare con il database. Si occupa automaticamente delle relazioni tra le tabelle e dell'ottimizzazione delle query, così potete concentrarvi sulla vostra applicazione. Funziona immediatamente senza alcuna impostazione. Se avete bisogno del pieno controllo sulle query SQL, potete utilizzare l'approccio SQL.
- Il lavoro con i dati è naturale e facile da capire
- Genera query SQL ottimizzate che caricano solo i dati necessari
- Permette un facile accesso ai dati correlati senza la necessità di scrivere query JOIN
- Funziona immediatamente senza alcuna configurazione o generazione di entità
Con Explorer iniziate chiamando il metodo table() dell'oggetto Nette\Database\Explorer (dettagli sulla connessione
li trovate nel capitolo Connessione e
configurazione):
$books = $explorer->table('book'); // 'book' è il nome della tabella
Il metodo restituisce un oggetto Selection, che rappresenta una query SQL.
A questo oggetto possiamo concatenare altri metodi per filtrare e ordinare i risultati. La query viene costruita ed eseguita
solo nel momento in cui iniziamo a richiedere i dati. Ad esempio, iterando con un ciclo foreach. Ogni riga è
rappresentata da un oggetto ActiveRow:
foreach ($books as $book) {
echo $book->title; // stampa della colonna 'title'
echo $book->author_id; // stampa della colonna 'author_id'
}
Explorer semplifica notevolmente il lavoro con le relazioni tra tabelle. L'esempio seguente mostra quanto sia facile visualizzare i dati da tabelle correlate (libri e i loro autori). Notate che non dobbiamo scrivere alcuna query JOIN, Nette le crea per noi:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Libro: ' . $book->title;
echo 'Autore: ' . $book->author->name; // crea un JOIN sulla tabella 'author'
}
Nette Database Explorer ottimizza le query affinché siano il più efficienti possibile. L'esempio sopra esegue solo due query SELECT, indipendentemente dal fatto che stiamo elaborando 10 o 10.000 libri.
Inoltre, Explorer tiene traccia di quali colonne vengono utilizzate nel codice e carica dal database solo quelle, risparmiando ulteriore performance. Questo comportamento è completamente automatico e adattivo. Se successivamente modificate il codice e iniziate a utilizzare altre colonne, Explorer adatterà automaticamente le query. Non dovete impostare nulla, né pensare a quali colonne vi serviranno – lasciate fare a Nette.
Filtraggio e ordinamento
La classe Selection fornisce metodi per filtrare e ordinare la selezione dei dati.
where($condition, ...$params) |
Aggiunge una condizione WHERE. Più condizioni sono unite dall'operatore AND |
whereOr(array $conditions) |
Aggiunge un gruppo di condizioni WHERE unite dall'operatore OR |
wherePrimary($value) |
Aggiunge una condizione WHERE in base alla chiave primaria |
order($columns, ...$params) |
Imposta l'ordinamento ORDER BY |
select($columns, ...$params) |
Specifica le colonne da caricare |
limit($limit, $offset = null) |
Limita il numero di righe (LIMIT) e opzionalmente imposta OFFSET |
page($page, $itemsPerPage, &$total = null) |
Imposta la paginazione |
group($columns, ...$params) |
Raggruppa le righe (GROUP BY) |
having($condition, ...$params) |
Aggiunge una condizione HAVING per filtrare le righe raggruppate |
I metodi possono essere concatenati (il cosiddetto fluent interface):
$table->where(...)->order(...)->limit(...).
In questi metodi potete anche utilizzare una notazione speciale per accedere ai dati da tabelle correlate.
Escaping e identificatori
I metodi eseguono automaticamente l'escaping dei parametri e racchiudono tra virgolette gli identificatori (nomi di tabelle e colonne), prevenendo così SQL injection. Per un corretto funzionamento è necessario rispettare alcune regole:
- Scrivete le parole chiave, i nomi di funzioni, procedure, ecc. in maiuscolo.
- Scrivete i nomi di colonne e tabelle in minuscolo.
- Inserite sempre le stringhe tramite parametri.
where('name = ' . $name); // VULNERABILITÀ CRITICA: SQL injection
where('name LIKE "%search%"'); // SBAGLIato: complica l'inserimento automatico delle virgolette
where('name LIKE ?', '%search%'); // CORRETTO: valore inserito tramite parametro
where('name like ?', $name); // SBAGLIATO: genera: `name` `like` ?
where('name LIKE ?', $name); // CORRETTO: genera: `name` LIKE ?
where('LOWER(name) = ?', $value);// CORRETTO: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtra i risultati tramite condizioni WHERE. Il suo punto di forza è il lavoro intelligente con diversi tipi di valori e la scelta automatica degli operatori SQL.
Uso base:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Grazie al rilevamento automatico degli operatori appropriati, non dobbiamo gestire diversi casi speciali. Nette li risolve per noi:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// è possibile utilizzare anche il placeholder punto interrogativo senza operatore:
$table->where('id ?', 1); // WHERE `id` = 1
Il metodo gestisce correttamente anche le condizioni negative e gli array vuoti:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- non trova nulla
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- trova tutto
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- trova tutto
// $table->where('NOT id ?', $ids); Attenzione - questa sintassi non è supportata
Come parametro possiamo passare anche il risultato di un'altra tabella – verrà creata una sottoquery:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Possiamo passare le condizioni anche come array, i cui elementi verranno uniti tramite AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
Nell'array possiamo utilizzare coppie chiave ⇒ valore e Nette sceglierà nuovamente automaticamente gli operatori corretti:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
Nell'array possiamo combinare espressioni SQL con placeholder punto interrogativo e più parametri. Questo è adatto per condizioni complesse con operatori definiti con precisione:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // passiamo due parametri come array
]);
Chiamate multiple a where() uniscono automaticamente le condizioni tramite AND.
whereOr (array $parameters): static
Simile a where(), aggiunge condizioni, ma con la differenza che le unisce tramite OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Anche qui possiamo utilizzare espressioni più complesse:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Aggiunge una condizione per la chiave primaria della tabella:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Se la tabella ha una chiave primaria composita (ad es. foo_id, bar_id), la passiamo come array:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Determina l'ordine in cui verranno restituite le righe. Possiamo ordinare per una o più colonne, in ordine ascendente o discendente, o secondo un'espressione personalizzata:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Specifica le colonne che devono essere restituite dal database. Per impostazione predefinita, Nette Database Explorer
restituisce solo le colonne che vengono effettivamente utilizzate nel codice. Il metodo select() viene quindi
utilizzato nei casi in cui è necessario restituire espressioni specifiche:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Gli alias definiti tramite AS sono quindi disponibili come proprietà dell'oggetto ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // accesso all'alias
}
limit (?int $limit, ?int $offset = null): static
Limita il numero di righe restituite (LIMIT) e opzionalmente consente di impostare un offset:
$table->limit(10); // LIMIT 10 (restituisce le prime 10 righe)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Per la paginazione è preferibile utilizzare il metodo page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Facilita la paginazione dei risultati. Accetta il numero di pagina (contato da 1) e il numero di elementi per pagina. Opzionalmente è possibile passare un riferimento a una variabile in cui verrà memorizzato il numero totale di pagine:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Pagine totali: $numOfPages";
group (string $columns, …$parameters): static
Raggruppa le righe in base alle colonne specificate (GROUP BY). Viene utilizzato solitamente in combinazione con funzioni di aggregazione:
// Conta il numero di prodotti in ogni categoria
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Imposta una condizione per filtrare le righe raggruppate (HAVING). Può essere utilizzata in combinazione con il metodo
group() e le funzioni di aggregazione:
// Trova le categorie che hanno più di 100 prodotti
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Lettura dei dati
Per leggere i dati dal database abbiamo a disposizione diversi metodi utili:
foreach ($table as $key => $row) |
Itera su tutte le righe, $key è il valore della chiave primaria, $row è l'oggetto ActiveRow |
$row = $table->get($key) |
Restituisce una riga in base alla chiave primaria |
$row = $table->fetch() |
Restituisce la riga corrente e sposta il puntatore alla successiva |
$array = $table->fetchPairs() |
Crea un array associativo dai risultati |
$array = $table->fetchAll() |
Restituisce tutte le righe come array |
count($table) |
Restituisce il numero di righe nell'oggetto Selection |
L'oggetto ActiveRow è destinato solo alla lettura. Ciò significa che non è possibile modificare i valori delle sue proprietà. Questa limitazione garantisce la coerenza dei dati e previene effetti collaterali imprevisti. I dati vengono caricati dal database e qualsiasi modifica dovrebbe essere eseguita esplicitamente e in modo controllato.
foreach – iterazione su tutte le righe
Il modo più semplice per eseguire una query e ottenere le righe è iterare in un ciclo foreach. Avvia
automaticamente la query SQL.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key è il valore della chiave primaria, $book è ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Esegue la query SQL e restituisce la riga in base alla chiave primaria, o null se non esiste.
$book = $explorer->table('book')->get(123); // restituisce ActiveRow con ID 123 o null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Restituisce una riga e sposta il puntatore interno alla successiva. Se non esistono più altre righe, restituisce
null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Restituisce i risultati come array associativo. Il primo argomento specifica il nome della colonna che verrà utilizzata come chiave nell'array, il secondo argomento specifica il nome della colonna che verrà utilizzata come valore:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Se specifichiamo solo il primo parametro, il valore sarà l'intera riga, ovvero l'oggetto ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
In caso di chiavi duplicate, verrà utilizzato il valore dell'ultima riga. Utilizzando null come chiave, l'array
sarà indicizzato numericamente da zero (quindi non si verificano collisioni):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
In alternativa, potete specificare come parametro un callback, che per ogni riga restituirà o il valore stesso, o una coppia chiave-valore.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Primo libro (Jan Novák)', ...]
// Il callback può anche restituire un array con una coppia chiave & valore:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Primo libro' => 'Jan Novák', ...]
fetchAll(): array
Restituisce tutte le righe come array associativo di oggetti ActiveRow, dove le chiavi sono i valori delle chiavi
primarie.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Il metodo count() senza parametro restituisce il numero di righe nell'oggetto Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // alternativa
Attenzione, count() con parametro esegue la funzione di aggregazione COUNT nel database, vedi sotto.
ActiveRow::toArray(): array
Converte l'oggetto ActiveRow in un array associativo, dove le chiavi sono i nomi delle colonne e i valori sono
i dati corrispondenti.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray sarà ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Aggregazione
La classe Selection fornisce metodi per eseguire facilmente funzioni di aggregazione (COUNT, SUM, MIN, MAX,
AVG ecc.).
count($expr) |
Conta il numero di righe |
min($expr) |
Restituisce il valore minimo nella colonna |
max($expr) |
Restituisce il valore massimo nella colonna |
sum($expr) |
Restituisce la somma dei valori nella colonna |
aggregation($function) |
Permette di eseguire qualsiasi funzione di aggregazione. Ad esempio, AVG(), GROUP_CONCAT() |
count (string $expr): int
Esegue una query SQL con la funzione COUNT e restituisce il risultato. Il metodo viene utilizzato per determinare quante righe corrispondono a una determinata condizione:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Attenzione, count() senza parametro restituisce solo il numero di righe nell'oggetto
Selection.
min (string $expr) e max(string $expr)
I metodi min() e max() restituiscono il valore minimo e massimo nella colonna o espressione
specificata:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Restituisce la somma dei valori nella colonna o espressione specificata:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Permette di eseguire qualsiasi funzione di aggregazione.
// prezzo medio dei prodotti nella categoria
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// unisce le etichette del prodotto in un'unica stringa
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Se abbiamo bisogno di aggregare risultati che sono già essi stessi derivati da qualche funzione di aggregazione e
raggruppamento (ad es. SUM(valore) su righe raggruppate), come secondo argomento specifichiamo la funzione di
aggregazione che deve essere applicata a questi risultati intermedi:
// Calcola il prezzo totale dei prodotti in magazzino per ogni categoria e poi somma questi prezzi insieme.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
In questo esempio, prima calcoliamo il prezzo totale dei prodotti in ogni categoria
(SUM(price * stock) AS category_total) e raggruppiamo i risultati per category_id. Poi utilizziamo
aggregation('SUM(category_total)', 'SUM') per sommare questi subtotali category_total. Il secondo
argomento 'SUM' dice che la funzione SUM deve essere applicata ai risultati intermedi.
Insert, Update & Delete
Nette Database Explorer semplifica l'inserimento, l'aggiornamento e l'eliminazione dei dati. Tutti i metodi menzionati
lanciano un'eccezione Nette\Database\DriverException in caso di errore.
Selection::insert (iterable $data)
Inserisce nuovi record nella tabella.
Inserimento di un singolo record:
Passiamo il nuovo record come array associativo o oggetto iterabile (ad esempio ArrayHash utilizzato nei moduli), dove le chiavi corrispondono ai nomi delle colonne nella tabella.
Se la tabella ha una chiave primaria definita, il metodo restituisce un oggetto ActiveRow, che viene ricaricato
dal database per tenere conto di eventuali modifiche apportate a livello di database (trigger, valori predefiniti delle colonne,
calcoli delle colonne auto-increment). Questo garantisce la coerenza dei dati e l'oggetto contiene sempre i dati attuali dal
database. Se non ha una chiave primaria univoca, restituisce i dati passati sotto forma di array.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row è un'istanza di ActiveRow e contiene i dati completi della riga inserita,
// incluso l'ID generato automaticamente e eventuali modifiche apportate dai trigger
echo $row->id; // Stampa l'ID dell'utente appena inserito
echo $row->created_at; // Stampa l'ora di creazione, se impostata da un trigger
Inserimento di più record contemporaneamente:
Il metodo insert() consente di inserire più record tramite un'unica query SQL. In questo caso, restituisce il
numero di righe inserite.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows sarà 2
Come parametro è possibile passare anche un oggetto Selection con una selezione di dati.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Inserimento di valori speciali:
Come valori possiamo passare anche file, oggetti DateTime o letterali SQL:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // converte nel formato del database
'avatar' => fopen('image.jpg', 'rb'), // inserisce il contenuto binario del file
'uuid' => $explorer::literal('UUID()'), // chiama la funzione UUID()
]);
Selection::update (iterable $data): int
Aggiorna le righe nella tabella secondo il filtro specificato. Restituisce il numero di righe effettivamente modificate.
Passiamo le colonne da modificare come array associativo o oggetto iterabile (ad esempio ArrayHash utilizzato nei moduli), dove le chiavi corrispondono ai nomi delle colonne nella tabella:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Per modificare i valori numerici possiamo utilizzare gli operatori += e -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // aumenta il valore della colonna 'points' di 1
'coins-=' => 1, // diminuisce il valore della colonna 'coins' di 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Elimina le righe dalla tabella secondo il filtro specificato. Restituisce il numero di righe eliminate.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Quando si chiamano update() e delete(), non dimenticate di specificare tramite
where() le righe che devono essere modificate/eliminate. Se non si utilizza where(), l'operazione verrà
eseguita sull'intera tabella!
ActiveRow::update (iterable $data): bool
Aggiorna i dati nella riga del database rappresentata dall'oggetto ActiveRow. Come parametro accetta un iterabile
con i dati da aggiornare (le chiavi sono i nomi delle colonne). Per modificare i valori numerici possiamo utilizzare gli
operatori += e -=:
Dopo l'esecuzione dell'aggiornamento, ActiveRow viene automaticamente ricaricato dal database per tenere conto di
eventuali modifiche apportate a livello di database (ad es. trigger). Il metodo restituisce true solo se si è verificata una
modifica effettiva dei dati.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // aumentiamo il numero di visualizzazioni
]);
echo $article->views; // Stampa il numero attuale di visualizzazioni
Questo metodo aggiorna solo una riga specifica nel database. Per l'aggiornamento massivo di più righe, utilizzate il metodo Selection::update().
ActiveRow::delete()
Elimina la riga dal database rappresentata dall'oggetto ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Elimina il libro con ID 1
Questo metodo elimina solo una riga specifica nel database. Per l'eliminazione massiva di più righe, utilizzate il metodo Selection::delete().
Relazioni tra tabelle
Nei database relazionali, i dati sono divisi in più tabelle e collegati tra loro tramite chiavi esterne. Nette Database Explorer introduce un modo rivoluzionario per lavorare con queste relazioni – senza scrivere query JOIN e senza la necessità di configurare o generare nulla.
Per illustrare il lavoro con le relazioni, utilizzeremo un esempio di database di libri (lo trovate su GitHub). Nel database abbiamo le tabelle:
author– scrittori e traduttori (colonneid,name,web,born)book– libri (colonneid,author_id,translator_id,title,sequel_id)tag– etichette (colonneid,name)book_tag– tabella di collegamento tra libri ed etichette (colonnebook_id,tag_id)
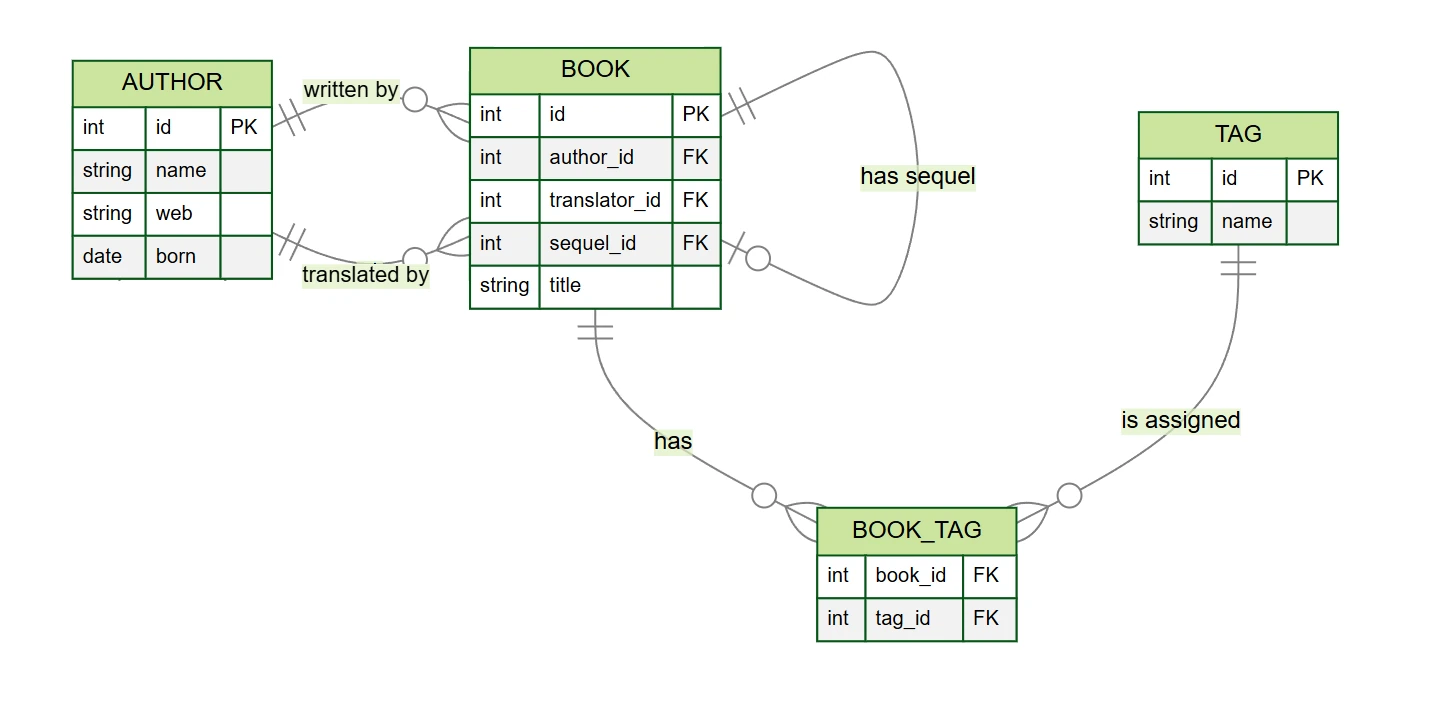
Nel nostro esempio di database di libri troviamo diversi tipi di relazioni (sebbene il modello sia semplificato rispetto alla realtà):
- One-to-many 1:N – ogni libro ha un autore, un autore può scrivere diversi libri
- Zero-to-many 0:N – un libro può avere un traduttore, un traduttore può tradurre diversi libri
- Zero-to-one 0:1 – un libro può avere un seguito
- Many-to-many M:N – un libro può avere diverse etichette e un'etichetta può essere assegnata a diversi libri
In queste relazioni esiste sempre una tabella padre e una figlia. Ad esempio, nella relazione tra autore e libro, la tabella
author è padre e book è figlia – possiamo immaginarlo come se il libro “appartenesse” sempre a
qualche autore. Questo si riflette anche nella struttura del database: la tabella figlia book contiene la chiave
esterna author_id, che fa riferimento alla tabella padre author.
Se abbiamo bisogno di visualizzare i libri inclusi i nomi dei loro autori, abbiamo due possibilità. O otteniamo i dati con un'unica query SQL tramite JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Oppure carichiamo i dati in due passaggi – prima i libri e poi i loro autori – e poi li assembliamo in PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- id degli autori dei libri ottenuti
Il secondo approccio è in realtà più efficiente, anche se può sorprendere. I dati vengono caricati solo una volta e possono essere utilizzati meglio nella cache. È proprio in questo modo che lavora Nette Database Explorer – risolve tutto sotto il cofano e vi offre un'API elegante:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'title: ' . $book->title;
echo 'written by: ' . $book->author->name; // $book->author è un record della tabella 'author'
echo 'translated by: ' . $book->translator?->name;
}
Accesso alla tabella padre
L'accesso alla tabella padre è diretto. Si tratta di relazioni come il libro ha un autore o il libro può avere
un traduttore. Otteniamo il record correlato tramite la proprietà dell'oggetto ActiveRow – il suo nome corrisponde al
nome della colonna con la chiave esterna senza id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // trova l'autore in base alla colonna author_id
echo $book->translator?->name; // trova il traduttore in base a translator_id
Quando accediamo alla proprietà $book->author, Explorer cerca nella tabella book una colonna il
cui nome contiene la stringa author (cioè author_id). In base al valore in questa colonna, carica il
record corrispondente dalla tabella author e lo restituisce come ActiveRow. Funziona in modo simile
anche $book->translator, che utilizza la colonna translator_id. Poiché la colonna
translator_id può contenere null, utilizziamo nel codice l'operatore ?->.
Un percorso alternativo è offerto dal metodo ref(), che accetta due argomenti, il nome della tabella di
destinazione e il nome della colonna di collegamento, e restituisce un'istanza di ActiveRow o null:
echo $book->ref('author', 'author_id')->name; // relazione con l'autore
echo $book->ref('author', 'translator_id')->name; // relazione con il traduttore
Il metodo ref() è utile se non è possibile utilizzare l'accesso tramite proprietà, perché la tabella contiene
una colonna con lo stesso nome (cioè author). Negli altri casi è consigliato utilizzare l'accesso tramite
proprietà, che è più leggibile.
Explorer ottimizza automaticamente le query al database. Quando iteriamo sui libri in un ciclo e accediamo ai loro record correlati (autori, traduttori), Explorer non genera una query per ogni libro separatamente. Invece, esegue solo un SELECT per ogni tipo di relazione, riducendo significativamente il carico sul database. Ad esempio:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Questo codice chiamerà solo queste tre velocissime query al database:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id dalla colonna author_id dei libri selezionati
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id dalla colonna translator_id dei libri selezionati
La logica di ricerca della colonna di collegamento è data dall'implementazione di Conventions. Consigliamo l'uso di DiscoveredConventions, che analizza le chiavi esterne e consente di lavorare semplicemente con le relazioni esistenti tra le tabelle.
Accesso alla tabella figlia
L'accesso alla tabella figlia funziona nella direzione opposta. Ora ci chiediamo quali libri ha scritto questo autore
o ha tradotto questo traduttore. Per questo tipo di query utilizziamo il metodo related(), che restituisce
una Selection con i record correlati. Vediamo un esempio:
$author = $explorer->table('author')->get(1);
// Stampa tutti i libri dell'autore
foreach ($author->related('book.author_id') as $book) {
echo "Ha scritto: $book->title";
}
// Stampa tutti i libri tradotti dall'autore
foreach ($author->related('book.translator_id') as $book) {
echo "Ha tradotto: $book->title";
}
Il metodo related() accetta la descrizione della connessione come un unico argomento con notazione a punti o come
due argomenti separati:
$author->related('book.translator_id'); // un argomento
$author->related('book', 'translator_id'); // due argomenti
Explorer è in grado di rilevare automaticamente la colonna di collegamento corretta in base al nome della tabella padre. In
questo caso, si collega tramite la colonna book.author_id, poiché il nome della tabella di origine è
author:
$author->related('book'); // usa book.author_id
Se esistessero più connessioni possibili, Explorer lancerebbe un'eccezione AmbiguousReferenceKeyException.
Il metodo related() può ovviamente essere utilizzato anche iterando su più record in un ciclo e Explorer anche
in questo caso ottimizza automaticamente le query:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' ha scritto:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Questo codice genererà solo due velocissime query SQL:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id degli autori selezionati
Relazione Many-to-many
Per la relazione many-to-many (M:N) è necessaria l'esistenza di una tabella di collegamento (nel nostro caso
book_tag), che contiene due colonne con chiavi esterne (book_id, tag_id). Ciascuna di
queste colonne fa riferimento alla chiave primaria di una delle tabelle collegate. Per ottenere i dati correlati, otteniamo prima
i record dalla tabella di collegamento tramite related('book_tag') e poi proseguiamo verso i dati di
destinazione:
$book = $explorer->table('book')->get(1);
// stampa i nomi dei tag assegnati al libro
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // stampa il nome del tag tramite la tabella di collegamento
}
$tag = $explorer->table('tag')->get(1);
// o viceversa: stampa i nomi dei libri contrassegnati da questo tag
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // stampa il titolo del libro
}
Explorer ottimizza nuovamente le query SQL in una forma efficiente:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id dei libri selezionati
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id dei tag trovati in book_tag
Interrogazione tramite tabelle correlate
Nei metodi where(), select(), order() e group() possiamo utilizzare
notazioni speciali per accedere alle colonne di altre tabelle. Explorer creerà automaticamente i JOIN necessari.
La notazione a punti (tabella_padre.colonna) viene utilizzata per la relazione 1:N dal punto di vista della
tabella figlia:
$books = $explorer->table('book');
// Trova i libri il cui autore ha un nome che inizia per 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Ordina i libri per nome dell'autore in ordine decrescente
$books->order('author.name DESC');
// Stampa il titolo del libro e il nome dell'autore
$books->select('book.title, author.name');
La notazione a due punti (:tabella_figlia.colonna) viene utilizzata per la relazione 1:N dal punto di vista
della tabella padre:
$authors = $explorer->table('author');
// Trova gli autori che hanno scritto un libro con 'PHP' nel titolo
$authors->where(':book.title LIKE ?', '%PHP%');
// Conta il numero di libri per ogni autore
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
Nell'esempio sopra con la notazione a due punti (:book.title), non è specificata la colonna con la chiave
esterna. Explorer rileva automaticamente la colonna corretta in base al nome della tabella padre. In questo caso, si collega
tramite la colonna book.author_id, poiché il nome della tabella di origine è author. Se esistessero
più connessioni possibili, Explorer lancerebbe un'eccezione AmbiguousReferenceKeyException.
La colonna di collegamento può essere specificata esplicitamente tra parentesi:
// Trova gli autori che hanno tradotto un libro con 'PHP' nel titolo
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Le notazioni possono essere concatenate per accedere tramite più tabelle:
// Trova gli autori dei libri contrassegnati con il tag 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Estensione delle condizioni per JOIN
Il metodo joinWhere() estende le condizioni che vengono specificate durante il collegamento delle tabelle in SQL
dopo la parola chiave ON.
Supponiamo di voler trovare i libri tradotti da un traduttore specifico:
// Trova i libri tradotti dal traduttore di nome 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
Nella condizione joinWhere() possiamo utilizzare le stesse costruzioni del metodo where() –
operatori, placeholder punto interrogativo, array di valori o espressioni SQL.
Per query più complesse con più JOIN, possiamo definire alias di tabelle:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Notate che mentre il metodo where() aggiunge condizioni alla clausola WHERE, il metodo
joinWhere() estende le condizioni nella clausola ON durante il collegamento delle tabelle.