Database Explorer
Explorerは、データベースを扱うための直感的で効率的な方法を提供します。テーブル間のリレーションやクエリの最適化を自動的に処理するため、アプリケーションに集中できます。設定なしですぐに機能します。SQLクエリを完全に制御する必要がある場合は、SQLアクセス を利用できます。
- データの操作は自然で理解しやすい
- 必要なデータのみを読み込む最適化されたSQLクエリを生成
- JOINクエリを記述することなく、関連データに簡単にアクセス可能
- 設定やエンティティの生成なしで即座に機能
Explorerの使用は、Nette\Database\Explorer
オブジェクトの table()
メソッドを呼び出すことから始めます(接続の詳細については、接続と設定
の章を参照してください):
$books = $explorer->table('book'); // 'book' はテーブル名
このメソッドは、SQLクエリを表す Selection
オブジェクトを返します。このオブジェクトにさらにメソッドを連鎖させて、結果をフィルタリングおよびソートできます。クエリは、データを要求し始めたときにのみ構築および実行されます。たとえば、foreach
ループで反復処理する場合です。各行は ActiveRow
オブジェクトによって表されます:
foreach ($books as $book) {
echo $book->title; // 'title' カラムの出力
echo $book->author_id; // 'author_id' カラムの出力
}
Explorerは、テーブル間のリレーション の操作を大幅に簡素化します。次の例は、関連するテーブル(書籍とその著者)からデータを簡単に表示する方法を示しています。JOINクエリを記述する必要がないことに注意してください。Netteがそれらを自動的に作成します:
$books = $explorer->table('book');
foreach ($books as $book) {
echo '書籍: ' . $book->title;
echo '著者: ' . $book->author->name; // 'author' テーブルへのJOINを作成
}
Nette Database Explorerは、クエリを可能な限り効率的に最適化します。上記の例では、処理する書籍が10冊であろうと10,000冊であろうと、2つのSELECTクエリのみを実行します。
さらに、Explorerはコード内で使用されているカラムを追跡し、データベースからそれらのみを読み込むことで、さらなるパフォーマンスを節約します。この動作は完全に自動的で適応的です。後でコードを変更して追加のカラムを使用し始めると、Explorerは自動的にクエリを調整します。何も設定する必要はなく、どのカラムが必要になるかを考える必要もありません – それはNetteに任せてください。
フィルタリングとソート
Selection
クラスは、データ選択のフィルタリングとソートのためのメソッドを提供します。
where($condition, ...$params) |
WHERE条件を追加します。複数の条件はAND演算子で結合されます |
whereOr(array $conditions) |
OR演算子で結合されたWHERE条件のグループを追加します |
wherePrimary($value) |
主キーに基づいてWHERE条件を追加します |
order($columns, ...$params) |
ORDER BYソートを設定します |
select($columns, ...$params) |
読み込むカラムを指定します |
limit($limit, $offset = null) |
行数を制限し(LIMIT)、オプションでOFFSETを設定します |
page($page, $itemsPerPage, &$total = null) |
ページネーションを設定します |
group($columns, ...$params) |
行をグループ化します(GROUP BY) |
having($condition, ...$params) |
グループ化された行をフィルタリングするためのHAVING条件を追加します |
メソッドは連鎖させることができます(いわゆる fluent
interface):$table->where(...)->order(...)->limit(...)。
これらのメソッドでは、関連テーブルのデータ にアクセスするための特別な表記法を使用することもできます。
エスケープと識別子
メソッドはパラメータを自動的にエスケープし、識別子(テーブル名とカラム名)を引用符で囲むことで、SQLインジェクションを防ぎます。正しく機能させるためには、いくつかのルールに従う必要があります:
- キーワード、関数名、プロシージャ名などは 大文字 で記述します。
- カラム名とテーブル名は 小文字 で記述します。
- 文字列は常に パラメータ を介して代入します。
where('name = ' . $name); // 致命的な脆弱性: SQLインジェクション
where('name LIKE "%search%"'); // 悪い例: 自動引用符付けを複雑にする
where('name LIKE ?', '%search%'); // 正しい例: パラメータ経由で値が代入される
where('name like ?', $name); // 悪い例: `name` `like` ? を生成
where('name LIKE ?', $name); // 正しい例: `name` LIKE ? を生成
where('LOWER(name) = ?', $value);// 正しい例: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
WHERE条件を使用して結果をフィルタリングします。その強力な点は、さまざまなタイプの値をインテリジェントに処理し、SQL演算子を自動的に選択することです。
基本的な使用法:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
適切な演算子の自動検出のおかげで、さまざまな特殊なケースに対処する必要はありません。Netteがそれらを処理します:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// 演算子なしのプレースホルダー疑問符も使用できます:
$table->where('id ?', 1); // WHERE `id` = 1
メソッドは、否定条件や空の配列も正しく処理します:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- 何も見つからない
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- すべて見つかる
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- すべて見つかる
// $table->where('NOT id ?', $ids); 注意 - この構文はサポートされていません
別のテーブルからの結果をパラメータとして渡すこともできます – サブクエリが作成されます:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
条件を配列として渡すこともでき、その要素はANDで結合されます:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
配列では、キー ⇒ 値のペアを使用でき、Netteは再び正しい演算子を自動的に選択します:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
配列では、プレースホルダー疑問符と複数のパラメータを持つSQL式を組み合わせることができます。これは、正確に定義された演算子を持つ複雑な条件に適しています:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // 2つのパラメータを配列として渡します
]);
where() の複数回の呼び出しは、条件を自動的にANDで結合します。
whereOr (array $parameters): static
where() と同様に条件を追加しますが、ORで結合する点が異なります:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
ここでも、より複雑な式を使用できます:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
テーブルの主キーの条件を追加します:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
テーブルに複合主キー(例:foo_id,
bar_id)がある場合は、配列として渡します:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
行が返される順序を指定します。1つまたは複数のカラム、昇順または降順、またはカスタム式でソートできます:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
データベースから返すカラムを指定します。デフォルトでは、Nette Database
Explorerはコードで実際に使用されるカラムのみを返します。select()
メソッドは、特定の式を返す必要がある場合に使用します:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
AS
で定義されたエイリアスは、ActiveRowオブジェクトのプロパティとして利用できます:
foreach ($table as $row) {
echo $row->formatted_date; // エイリアスへのアクセス
}
limit (?int $limit, ?int $offset = null): static
返される行数を制限し(LIMIT)、オプションでオフセットを設定できます:
$table->limit(10); // LIMIT 10 (最初の10行を返す)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
ページネーションには、page() メソッドを使用する方が適しています。
page (int $page, int $itemsPerPage, &$numOfPages = null): static
結果のページネーションを容易にします。ページ番号(1から数える)とページあたりの項目数を受け取ります。オプションで、合計ページ数が格納される変数への参照を渡すことができます:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "合計ページ数: $numOfPages";
group (string $columns, …$parameters): static
指定されたカラムに基づいて行をグループ化します(GROUP BY)。通常、集計関数と組み合わせて使用されます:
// 各カテゴリの製品数をカウント
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
グループ化された行をフィルタリングするための条件(HAVING)を設定します。group()
メソッドと集計関数と組み合わせて使用できます:
// 100以上の製品を持つカテゴリを検索
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
データの読み取り
データベースからデータを読み取るために、いくつかの便利なメソッドが利用可能です:
foreach ($table as $key => $row) |
全行を反復処理します。$keyは主キーの値、$rowはActiveRowオブジェクトです |
$row = $table->get($key) |
主キーに基づいて1行を返します |
$row = $table->fetch() |
現在の行を返し、ポインタを次に進めます |
$array = $table->fetchPairs() |
結果から連想配列を作成します |
$array = $table->fetchAll() |
全行を配列として返します |
count($table) |
Selectionオブジェクト内の行数を返します |
ActiveRow オブジェクトは読み取り専用です。つまり、そのプロパティの値を変更することはできません。この制限により、データの整合性が保証され、予期しない副作用が防止されます。データはデータベースから読み込まれ、変更は明示的かつ制御された方法で行われるべきです。
foreach – 全行の反復処理
クエリを実行して行を取得する最も簡単な方法は、foreach
ループで反復処理することです。SQLクエリを自動的に実行します。
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $keyは主キーの値、$bookはActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
SQLクエリを実行し、主キーに基づいて行を返します。存在しない場合は
null を返します。
$book = $explorer->table('book')->get(123); // ID 123のActiveRowまたはnullを返します
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
行を返し、内部ポインタを次に進めます。これ以上行がない場合は null
を返します。
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
結果を連想配列として返します。最初の引数は配列のキーとして使用されるカラム名を指定し、2番目の引数は値として使用されるカラム名を指定します:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
最初のパラメータのみを指定した場合、値は行全体、つまり ActiveRow
オブジェクトになります:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
キーが重複する場合、最後の行の値が使用されます。キーとして null
を使用すると、配列はゼロから始まる数値インデックスになります(この場合、衝突は発生しません):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
あるいは、パラメータとしてコールバックを指定することもできます。これは、各行に対して値自体、またはキーと値のペアのいずれかを返します。
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['最初の本 (Jan Novák)', ...]
// コールバックはキーと値のペアを持つ配列を返すこともできます:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['最初の本' => 'Jan Novák', ...]
fetchAll(): array
すべての行を ActiveRow
オブジェクトの連想配列として返します。キーは主キーの値です。
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
パラメータなしの count() メソッドは、Selection
オブジェクト内の行数を返します:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // 代替
注意:パラメータ付きの count()
は、データベースで集計関数COUNTを実行します。下記参照。
ActiveRow::toArray(): array
ActiveRow
オブジェクトを連想配列に変換します。キーはカラム名、値は対応するデータです。
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray は ['id' => 1, 'title' => '...', 'author_id' => ..., ...] になります
集計
Selection
クラスは、集計関数(COUNT、SUM、MIN、MAX、AVGなど)を簡単に実行するためのメソッドを提供します。
count($expr) |
行数をカウントします |
min($expr) |
カラム内の最小値を返します |
max($expr) |
カラム内の最大値を返します |
sum($expr) |
カラム内の値の合計を返します |
aggregation($function) |
任意の集計関数を実行できます。例: AVG(), GROUP_CONCAT() |
count (string $expr): int
COUNT関数を使用してSQLクエリを実行し、結果を返します。このメソッドは、特定の条件に一致する行数を調べるために使用されます:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
注意:パラメータなしの count() は、Selection
オブジェクト内の行数を返すだけです。
min (string $expr) a max(string $expr)
min() および max()
メソッドは、指定されたカラムまたは式の最小値と最大値を返します:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
指定されたカラムまたは式の値の合計を返します:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
任意の集計関数を実行できます。
// カテゴリ内の製品の平均価格
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// 製品のタグを1つの文字列に結合します
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
既に何らかの集計関数とグループ化から生じた結果(例:グループ化された行に対する
SUM(値))を集計する必要がある場合、2番目の引数として、これらの中間結果に適用する集計関数を指定します:
// 各カテゴリの在庫製品の合計価格を計算し、その後これらの価格を合計します。
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
この例では、まず各カテゴリの製品の合計価格(SUM(price * stock) AS category_total)を計算し、category_id
で結果をグループ化します。次に、aggregation('SUM(category_total)', 'SUM')
を使用して、これらの中間合計 category_total を合計します。2番目の引数 'SUM'
は、中間結果にSUM関数を適用することを示します。
Insert, Update & Delete
Nette Database
Explorerは、データの挿入、更新、削除を簡素化します。記載されているすべてのメソッドは、Nette\Database\DriverException
例外をスローします。
Selection::insert (iterable $data)
テーブルに新しいレコードを挿入します。
単一レコードの挿入:
新しいレコードを連想配列またはiterableオブジェクト(たとえば フォーム で使用されるArrayHash)として渡します。キーはテーブルのカラム名に対応します。
テーブルに主キーが定義されている場合、メソッドはデータベースから再読み込みされた
ActiveRow
オブジェクトを返します。これにより、データベースレベルで行われた変更(トリガー、カラムのデフォルト値、自動インクリメントカラムの計算)が反映されます。これにより、データの整合性が保証され、オブジェクトは常にデータベースからの最新データを含みます。一意の主キーがない場合は、渡されたデータを配列形式で返します。
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $rowはActiveRowのインスタンスであり、挿入された行の完全なデータを含みます。
// 自動生成されたIDやトリガーによって行われた変更も含みます
echo $row->id; // 新しく挿入されたユーザーのIDを出力します
echo $row->created_at; // トリガーによって設定されている場合、作成時間を出力します
複数のレコードを一度に挿入:
insert()
メソッドを使用すると、単一のSQLクエリで複数のレコードを挿入できます。この場合、挿入された行数を返します。
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows は 2 になります
パラメータとして、データ選択を持つ Selection
オブジェクトを渡すこともできます。
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
特殊な値の挿入:
値として、ファイル、DateTimeオブジェクト、またはSQLリテラルを渡すこともできます:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // データベース形式に変換します
'avatar' => fopen('image.jpg', 'rb'), // ファイルのバイナリコンテンツを挿入します
'uuid' => $explorer::literal('UUID()'), // UUID() 関数を呼び出します
]);
Selection::update (iterable $data): int
指定されたフィルタに従ってテーブル内の行を更新します。実際に変更された行数を返します。
変更するカラムを連想配列またはiterableオブジェクト(たとえば フォーム で使用されるArrayHash)として渡します。キーはテーブルのカラム名に対応します:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
数値の値を変更するには、+= および -= 演算子を使用できます:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // 'points' カラムの値を1増やします
'coins-=' => 1, // 'coins' カラムの値を1減らします
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
指定されたフィルタに従ってテーブルから行を削除します。削除された行数を返します。
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
update() および delete() を呼び出すときは、where()
を使用して変更/削除する行を指定することを忘れないでください。where()
を使用しない場合、操作はテーブル全体に対して実行されます!
ActiveRow::update (iterable $data): bool
ActiveRow
オブジェクトによって表されるデータベース行のデータを更新します。パラメータとして、更新するデータを含むiterable(キーはカラム名)を受け取ります。数値の値を変更するには、+=
および -= 演算子を使用できます:
更新を実行した後、ActiveRow
はデータベースから自動的に再読み込みされ、データベースレベルで行われた変更(例:トリガー)が反映されます。メソッドは、データが実際に変更された場合にのみtrueを返します。
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // 表示回数を増やします
]);
echo $article->views; // 現在の表示回数を出力します
このメソッドは、データベース内の特定の1行のみを更新します。複数の行を一括更新するには、Selection::update() メソッドを使用します。
ActiveRow::delete()
ActiveRow オブジェクトによって表されるデータベースから行を削除します。
$book = $explorer->table('book')->get(1);
$book->delete(); // ID 1の書籍を削除します
このメソッドは、データベース内の特定の1行のみを削除します。複数の行を一括削除するには、Selection::delete() メソッドを使用します。
テーブル間のリレーション
リレーショナルデータベースでは、データは複数のテーブルに分割され、外部キーを使用して相互にリンクされています。Nette Database Explorerは、これらのリレーションを操作するための革新的な方法を提供します – JOINクエリを記述したり、何かを設定したり生成したりする必要はありません。
リレーションの操作を説明するために、書籍データベースの例を使用します(GitHubで見つけることができます)。データベースには次のテーブルがあります:
author– 作家と翻訳者(カラムid,name,web,born)book– 書籍(カラムid,author_id,translator_id,title,sequel_id)tag– タグ(カラムid,name)book_tag– 書籍とタグ間の関連テーブル(カラムbook_id,tag_id)
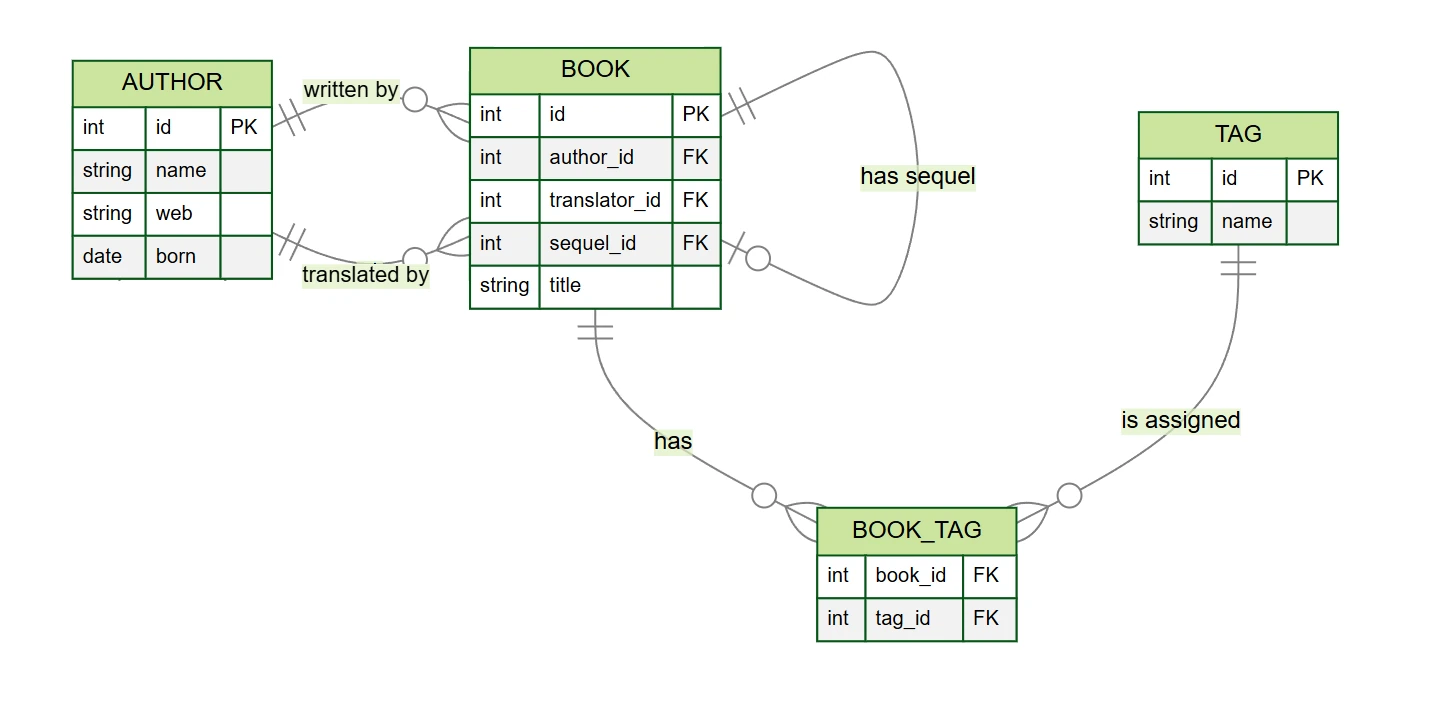
書籍データベースの例では、いくつかのタイプの関係が見つかります(モデルは現実よりも単純化されていますが):
- One-to-many 1:N – 各書籍には 1人の 著者がおり、著者は 複数の 書籍を書くことができます
- Zero-to-many 0:N – 書籍には翻訳者が いる場合があり、翻訳者は 複数の 書籍を翻訳できます
- Zero-to-one 0:1 – 書籍には続編が ある場合があります
- Many-to-many M:N – 書籍には 複数の タグがあり、タグは 複数の 書籍に割り当てることができます
これらの関係では、常に親テーブルと子テーブルが存在します。たとえば、著者と書籍の関係では、author
テーブルが親で、book テーブルが子です –
書籍は常に何らかの著者に「属している」と考えることができます。これはデータベースの構造にも反映されています:子テーブル
book には、親テーブル author を参照する外部キー author_id
が含まれています。
著者名を含む書籍をリストする必要がある場合、2つの選択肢があります。JOINを使用して単一のSQLクエリでデータを取得する:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
または、データを2段階で読み込む – まず書籍、次にその著者 – そしてPHPでそれらを組み立てる:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- 取得した書籍の著者ID
2番目のアプローチは、驚くべきかもしれませんが、実際にはより効率的です。データは一度だけ読み込まれ、キャッシュでより良く利用できます。Nette Database Explorerはこの方法で動作します – すべてを内部で処理し、エレガントなAPIを提供します:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'title: ' . $book->title;
echo 'written by: ' . $book->author->name; // $book->author は 'author' テーブルからのレコードです
echo 'translated by: ' . $book->translator?->name;
}
親テーブルへのアクセス
親テーブルへのアクセスは簡単です。これは 書籍には著者がいる または
書籍には翻訳者がいる場合がある
のような関係です。関連するレコードは、ActiveRowオブジェクトのプロパティを介して取得します –
その名前は、id を除いた外部キーのカラム名に対応します:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // author_id カラムに基づいて著者を見つけます
echo $book->translator?->name; // translator_id に基づいて翻訳者を見つけます
プロパティ $book->author にアクセスすると、Explorerは book テーブルで文字列
author を含むカラム(つまり
author_id)を探します。このカラムの値に基づいて、対応するレコードを author
テーブルから読み込み、ActiveRow として返します。同様に、$book->translator
も機能し、translator_id カラムを使用します。translator_id カラムは null
を含む可能性があるため、コードで ?-> 演算子を使用します。
代替の方法として、ref()
メソッドがあります。これは、ターゲットテーブルの名前と結合カラムの名前の2つの引数を受け取り、ActiveRow
インスタンスまたは null を返します:
echo $book->ref('author', 'author_id')->name; // 著者へのリレーション
echo $book->ref('author', 'translator_id')->name; // 翻訳者へのリレーション
ref() メソッドは、テーブルに同じ名前のカラム(つまり
author)が含まれているためにプロパティアクセスを使用できない場合に便利です。その他の場合、読みやすいプロパティアクセスを使用することをお勧めします。
Explorerはデータベースクエリを自動的に最適化します。ループで書籍を反復処理し、それらの関連レコード(著者、翻訳者)にアクセスする場合、Explorerは各書籍に対して個別にクエリを生成しません。代わりに、各リレーションタイプに対して1つのSELECTのみを実行し、データベースの負荷を大幅に削減します。たとえば:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
このコードは、データベースに対してこれら3つの高速なクエリのみを呼び出します:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- 選択された書籍の author_id カラムからのID
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- 選択された書籍の translator_id カラムからのID
結合カラムの検索ロジックは、Conventions の実装によって決定されます。DiscoveredConventions の使用をお勧めします。これは外部キーを分析し、テーブル間の既存のリレーションを簡単に操作できます。
子テーブルへのアクセス
子テーブルへのアクセスは逆方向に機能します。今度は この著者が書いた書籍は何か
または この翻訳者が翻訳した書籍は何か
を尋ねます。このタイプのクエリには、関連レコードを持つ Selection を返す
related() メソッドを使用します。例を見てみましょう:
$author = $explorer->table('author')->get(1);
// 著者のすべての書籍を出力します
foreach ($author->related('book.author_id') as $book) {
echo "執筆: $book->title";
}
// 著者が翻訳したすべての書籍を出力します
foreach ($author->related('book.translator_id') as $book) {
echo "翻訳: $book->title";
}
related()
メソッドは、ドット表記の単一引数として、または2つの個別の引数として結合の説明を受け入れます:
$author->related('book.translator_id'); // 1つの引数
$author->related('book', 'translator_id'); // 2つの引数
Explorerは、親テーブルの名前に基づいて正しい結合カラムを自動的に検出できます。この場合、ソーステーブルの名前が
author であるため、book.author_id カラムを介して結合されます:
$author->related('book'); // book.author_id を使用します
複数の可能な結合が存在する場合、Explorerは AmbiguousReferenceKeyException 例外をスローします。
related()
メソッドは、もちろん、ループで複数のレコードを反復処理する場合にも使用でき、Explorerはこの場合でもクエリを自動的に最適化します:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' 執筆:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
このコードは、2つの高速なSQLクエリのみを生成します:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- 選択された著者のID
多対多リレーション
多対多(M:N)リレーションには、2つの外部キーカラム(book_id、tag_id)を含む関連テーブル(この場合は
book_tag)が必要です。これらのカラムのそれぞれは、リンクされたテーブルの1つの主キーを参照します。関連データを取得するには、まず
related('book_tag')
を使用して関連テーブルからレコードを取得し、次にターゲットデータに進みます:
$book = $explorer->table('book')->get(1);
// 書籍に割り当てられたタグの名前を出力します
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // 関連テーブルを介してタグの名前を出力します
}
$tag = $explorer->table('tag')->get(1);
// または逆: このタグでマークされた書籍の名前を出力します
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // 書籍の名前を出力します
}
Explorerは再びSQLクエリを効率的な形式に最適化します:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- 選択された書籍のID
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- book_tagで見つかったタグのID
関連テーブルを介したクエリ
where()、select()、order()、group()
メソッドでは、他のテーブルのカラムにアクセスするための特別な表記法を使用できます。Explorerは必要なJOINを自動的に作成します。
ドット表記 (親テーブル.カラム)
は、子テーブルの観点からの1:N関係に使用されます:
$books = $explorer->table('book');
// 著者の名前が 'Jon' で始まる書籍を見つけます
$books->where('author.name LIKE ?', 'Jon%');
// 著者の名前で書籍を降順にソートします
$books->order('author.name DESC');
// 書籍のタイトルと著者の名前を出力します
$books->select('book.title, author.name');
コロン表記 (:子テーブル.カラム)
は、親テーブルの観点からの1:N関係に使用されます:
$authors = $explorer->table('author');
// タイトルに 'PHP' を含む書籍を書いた著者を見つけます
$authors->where(':book.title LIKE ?', '%PHP%');
// 各著者の書籍数をカウントします
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
上記のコロン表記(:book.title)の例では、外部キーのカラムが指定されていません。Explorerは、親テーブルの名前に基づいて正しいカラムを自動的に検出します。この場合、ソーステーブルの名前が
author であるため、book.author_id
カラムを介して結合されます。複数の可能な結合が存在する場合、Explorerは AmbiguousReferenceKeyException
例外をスローします。
結合カラムは括弧内に明示的に指定できます:
// タイトルに 'PHP' を含む書籍を翻訳した著者を見つけます
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
表記法は、複数のテーブルを介してアクセスするために連鎖させることができます:
// 'PHP' タグでマークされた書籍の著者を見つけます
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
JOIN条件の拡張
joinWhere() メソッドは、SQLでテーブルを結合する際に ON
キーワードの後に指定される条件を拡張します。
特定の翻訳者によって翻訳された書籍を見つけたいとしましょう:
// 'David' という名前の翻訳者によって翻訳された書籍を見つけます
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
joinWhere() 条件では、where() メソッドと同じ構文を使用できます –
演算子、プレースホルダー疑問符、値の配列、またはSQL式。
複数のJOINを持つより複雑なクエリの場合、テーブルエイリアスを定義できます:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
where() メソッドが WHERE 句に条件を追加するのに対し、joinWhere()
メソッドはテーブルを結合する際の ON
句の条件を拡張することに注意してください。