Database Explorer
Der Explorer bietet eine intuitive und effiziente Methode zur Arbeit mit der Datenbank. Er kümmert sich automatisch um Beziehungen zwischen Tabellen und die Optimierung von Abfragen, sodass Sie sich auf Ihre Anwendung konzentrieren können. Er funktioniert sofort ohne Konfiguration. Wenn Sie die volle Kontrolle über SQL-Abfragen benötigen, können Sie den SQL-Zugriff nutzen.
- Die Arbeit mit Daten ist natürlich und leicht verständlich
- Generiert optimierte SQL-Abfragen, die nur die benötigten Daten laden
- Ermöglicht einfachen Zugriff auf verwandte Daten ohne die Notwendigkeit, JOIN-Abfragen zu schreiben
- Funktioniert sofort ohne jegliche Konfiguration oder Generierung von Entitäten
Mit dem Explorer beginnen Sie, indem Sie die Methode table() des Objekts Nette\Database\Explorer aufrufen (Details zur
Verbindung finden Sie im Kapitel Verbindung und
Konfiguration):
$books = $explorer->table('book'); // 'book' ist der Tabellenname
Die Methode gibt ein Objekt Selection
zurück, das eine SQL-Abfrage repräsentiert. An dieses Objekt können weitere Methoden zur Filterung und Sortierung der
Ergebnisse angehängt werden. Die Abfrage wird erst zusammengestellt und ausgeführt, wenn Sie Daten anfordern, beispielsweise
durch Iteration mit einer foreach-Schleife. Jede Zeile wird durch ein Objekt ActiveRow repräsentiert:
foreach ($books as $book) {
echo $book->title; // Ausgabe der Spalte 'title'
echo $book->author_id; // Ausgabe der Spalte 'author_id'
}
Der Explorer erleichtert die Arbeit mit Beziehungen zwischen Tabellen erheblich. Das folgende Beispiel zeigt, wie einfach Sie Daten aus verknüpften Tabellen (Bücher und ihre Autoren) ausgeben können. Beachten Sie, dass Sie keine JOIN-Abfragen schreiben müssen; Nette erstellt sie für Sie:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Buch: ' . $book->title;
echo 'Autor: ' . $book->author->name; // erstellt JOIN zur Tabelle 'author'
}
Nette Database Explorer optimiert Abfragen, um sie so effizient wie möglich zu gestalten. Das obige Beispiel führt nur zwei SELECT-Abfragen aus, unabhängig davon, ob Sie 10 oder 10.000 Bücher verarbeiten.
Zusätzlich verfolgt der Explorer, welche Spalten im Code verwendet werden, und lädt nur diese aus der Datenbank, wodurch weitere Leistung eingespart wird. Dieses Verhalten ist vollständig automatisch und adaptiv. Wenn Sie später den Code ändern und weitere Spalten verwenden, passt der Explorer die Abfragen automatisch an. Sie müssen nichts einstellen oder darüber nachdenken, welche Spalten Sie benötigen werden – überlassen Sie das Nette.
Filterung und Sortierung
Die Klasse Selection bietet Methoden zur Filterung und Sortierung der Datenauswahl.
where($condition, ...$params) |
Fügt eine WHERE-Bedingung hinzu. Mehrere Bedingungen werden mit dem AND-Operator verknüpft |
whereOr(array $conditions) |
Fügt eine Gruppe von WHERE-Bedingungen hinzu, die mit dem OR-Operator verknüpft sind |
wherePrimary($value) |
Fügt eine WHERE-Bedingung nach dem Primärschlüssel hinzu |
order($columns, ...$params) |
Legt die ORDER BY-Sortierung fest |
select($columns, ...$params) |
Spezifiziert die Spalten, die geladen werden sollen |
limit($limit, $offset = null) |
Begrenzt die Anzahl der Zeilen (LIMIT) und setzt optional den OFFSET |
page($page, $itemsPerPage, &$total = null) |
Legt die Paginierung fest |
group($columns, ...$params) |
Gruppiert Zeilen (GROUP BY) |
having($condition, ...$params) |
Fügt eine HAVING-Bedingung zur Filterung gruppierter Zeilen hinzu |
Methoden können verkettet werden (sog. Fluent Interface):
$table->where(...)->order(...)->limit(...).
In diesen Methoden können Sie auch spezielle Notationen für den Zugriff auf Daten aus verwandten Tabellen verwenden.
Escaping und Bezeichner
Methoden escapen automatisch Parameter und setzen Bezeichner (Tabellen- und Spaltennamen) in Anführungszeichen, wodurch SQL-Injection verhindert wird. Für die korrekte Funktion müssen einige Regeln beachtet werden:
- Schlüsselwörter, Funktionsnamen, Prozedurnamen usw. großschreiben.
- Spalten- und Tabellennamen kleinschreiben.
- Zeichenketten immer über Parameter einfügen.
where('name = ' . $name); // KRITISCHE SCHWACHSTELLE: SQL-Injection
where('name LIKE "%search%"'); // FALSCH: erschwert das automatische Setzen von Anführungszeichen
where('name LIKE ?', '%search%'); // RICHTIG: Wert über Parameter eingefügt
where('name like ?', $name); // FALSCH: generiert: `name` `like` ?
where('name LIKE ?', $name); // RICHTIG: generiert: `name` LIKE ?
where('LOWER(name) = ?', $value);// RICHTIG: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtert Ergebnisse anhand von WHERE-Bedingungen. Ihre Stärke liegt in der intelligenten Verarbeitung verschiedener Wertetypen und der automatischen Wahl von SQL-Operatoren.
Grundlegende Verwendung:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Dank der automatischen Erkennung geeigneter Operatoren müssen Sie sich nicht um verschiedene Sonderfälle kümmern. Nette löst sie für Sie:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// Es kann auch ein Fragezeichen-Platzhalter ohne Operator verwendet werden:
$table->where('id ?', 1); // WHERE `id` = 1
Die Methode verarbeitet auch negative Bedingungen und leere Arrays korrekt:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- findet nichts
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- findet alles
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- findet alles
// $table->where('NOT id ?', $ids); Achtung - diese Syntax wird nicht unterstützt
Als Parameter können Sie auch das Ergebnis aus einer anderen Tabelle übergeben – es wird eine Unterabfrage erstellt:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Bedingungen können Sie auch als Array übergeben, dessen Elemente mit AND verknüpft werden:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
Im Array können Sie Schlüssel-Wert-Paare verwenden, und Nette wählt wieder automatisch die richtigen Operatoren:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
Im Array können Sie SQL-Ausdrücke mit Fragezeichen-Platzhaltern und mehreren Parametern kombinieren. Dies ist geeignet für komplexe Bedingungen mit genau definierten Operatoren:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // zwei Parameter als Array übergeben
]);
Mehrfache Aufrufe von where() verknüpfen Bedingungen automatisch mit AND.
whereOr (array $parameters): static
Fügt ähnlich wie where() Bedingungen hinzu, jedoch mit dem Unterschied, dass sie mit OR verknüpft werden:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Auch hier können Sie komplexere Ausdrücke verwenden:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Fügt eine Bedingung für den Primärschlüssel der Tabelle hinzu:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Wenn die Tabelle einen zusammengesetzten Primärschlüssel hat (z. B. foo_id, bar_id), übergeben Sie
ihn als Array:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Bestimmt die Reihenfolge, in der die Zeilen zurückgegeben werden. Sie können nach einer oder mehreren Spalten sortieren, in aufsteigender oder absteigender Reihenfolge oder nach einem eigenen Ausdruck:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Spezifiziert die Spalten, die aus der Datenbank zurückgegeben werden sollen. Standardmäßig gibt Nette Database Explorer nur
die Spalten zurück, die tatsächlich im Code verwendet werden. Die Methode select() verwenden Sie daher in Fällen,
in denen Sie spezifische Ausdrücke zurückgeben müssen:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Aliase, die mit AS definiert wurden, sind dann als Eigenschaften des ActiveRow-Objekts verfügbar:
foreach ($table as $row) {
echo $row->formatted_date; // Zugriff auf den Alias
}
limit (?int $limit, ?int $offset = null): static
Begrenzt die Anzahl der zurückgegebenen Zeilen (LIMIT) und ermöglicht optional die Einstellung eines Offsets:
$table->limit(10); // LIMIT 10 (gibt die ersten 10 Zeilen zurück)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Für die Paginierung ist es besser, die Methode page() zu verwenden.
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Erleichtert die Paginierung von Ergebnissen. Akzeptiert die Seitennummer (beginnend bei 1) und die Anzahl der Elemente pro Seite. Optional kann eine Referenz auf eine Variable übergeben werden, in der die Gesamtzahl der Seiten gespeichert wird:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Gesamtzahl der Seiten: $numOfPages";
group (string $columns, …$parameters): static
Gruppiert Zeilen nach den angegebenen Spalten (GROUP BY). Wird normalerweise in Verbindung mit Aggregationsfunktionen verwendet:
// Zählt die Anzahl der Produkte in jeder Kategorie
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Legt eine Bedingung zur Filterung gruppierter Zeilen fest (HAVING). Kann in Verbindung mit der Methode group() und
Aggregationsfunktionen verwendet werden:
// Findet Kategorien mit mehr als 100 Produkten
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Daten lesen
Zum Lesen von Daten aus der Datenbank stehen Ihnen mehrere nützliche Methoden zur Verfügung:
foreach ($table as $key => $row) |
Iteriert über alle Zeilen, $key ist der Wert des Primärschlüssels, $row ist ein
ActiveRow-Objekt |
$row = $table->get($key) |
Gibt eine Zeile nach dem Primärschlüssel zurück |
$row = $table->fetch() |
Gibt die aktuelle Zeile zurück und bewegt den Zeiger zur nächsten |
$array = $table->fetchPairs() |
Erstellt ein assoziatives Array aus den Ergebnissen |
$array = $table->fetchAll() |
Gibt alle Zeilen als Array zurück |
count($table) |
Gibt die Anzahl der Zeilen im Selection-Objekt zurück |
Das Objekt ActiveRow ist nur zum Lesen bestimmt. Das bedeutet, dass die Werte seiner Eigenschaften nicht geändert werden können. Diese Einschränkung gewährleistet die Datenkonsistenz und verhindert unerwartete Nebeneffekte. Daten werden aus der Datenbank geladen, und jede Änderung sollte explizit und kontrolliert erfolgen.
foreach – Iteration über alle Zeilen
Der einfachste Weg, eine Abfrage auszuführen und Zeilen zu erhalten, ist die Iteration in einer foreach-Schleife.
Sie startet automatisch die SQL-Abfrage.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key ist der Wert des Primärschlüssels, $book ist ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Führt eine SQL-Abfrage aus und gibt eine Zeile nach dem Primärschlüssel zurück, oder null, wenn sie nicht
existiert.
$book = $explorer->table('book')->get(123); // gibt ActiveRow mit ID 123 oder null zurück
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Gibt eine Zeile zurück und bewegt den internen Zeiger zur nächsten. Wenn keine weiteren Zeilen mehr existieren, gibt sie
null zurück.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Gibt Ergebnisse als assoziatives Array zurück. Das erste Argument bestimmt den Namen der Spalte, die als Schlüssel im Array verwendet wird, das zweite Argument bestimmt den Namen der Spalte, die als Wert verwendet wird:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Wenn nur der erste Parameter angegeben wird, ist der Wert die gesamte Zeile, also das ActiveRow-Objekt:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
Bei doppelten Schlüsseln wird der Wert aus der letzten Zeile verwendet. Bei Verwendung von null als Schlüssel
wird das Array numerisch von Null indiziert (dann treten keine Kollisionen auf):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternativ können Sie als Parameter einen Callback angeben, der für jede Zeile entweder den Wert selbst oder ein Schlüssel-Wert-Paar zurückgibt.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Erstes Buch (Jan Novák)', ...]
// Der Callback kann auch ein Array mit einem Schlüssel-Wert-Paar zurückgeben:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Erstes Buch' => 'Jan Novák', ...]
fetchAll(): array
Gibt alle Zeilen als assoziatives Array von ActiveRow-Objekten zurück, wobei die Schlüssel die Werte der
Primärschlüssel sind.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Die Methode count() ohne Parameter gibt die Anzahl der Zeilen im Selection-Objekt zurück:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // Alternative
Achtung: count() mit einem Parameter führt eine Aggregationsfunktion COUNT() in der Datenbank aus,
siehe unten.
ActiveRow::toArray(): array
Konvertiert das ActiveRow-Objekt in ein assoziatives Array, wobei die Schlüssel die Spaltennamen und die Werte
die entsprechenden Daten sind.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray wird sein: ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Aggregation
Die Klasse Selection bietet Methoden zur einfachen Durchführung von Aggregationsfunktionen (COUNT, SUM, MIN, MAX,
AVG usw.).
count($expr) |
Zählt die Anzahl der Zeilen |
min($expr) |
Gibt den Minimalwert in der Spalte zurück |
max($expr) |
Gibt den Maximalwert in der Spalte zurück |
sum($expr) |
Gibt die Summe der Werte in der Spalte zurück |
aggregation($function) |
Ermöglicht die Durchführung einer beliebigen Aggregationsfunktion. Z. B.
AVG(), GROUP_CONCAT() |
count (string $expr): int
Führt eine SQL-Abfrage mit der COUNT-Funktion aus und gibt das Ergebnis zurück. Die Methode wird verwendet, um
festzustellen, wie viele Zeilen einer bestimmten Bedingung entsprechen:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Achtung: count() ohne Parameter gibt nur die Anzahl der Zeilen im Selection-Objekt
zurück.
min (string $expr) und max(string $expr)
Die Methoden min() und max() geben den minimalen bzw. maximalen Wert in der angegebenen Spalte oder
dem Ausdruck zurück:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Gibt die Summe der Werte in der angegebenen Spalte oder dem Ausdruck zurück:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Ermöglicht die Durchführung einer beliebigen Aggregationsfunktion.
// Durchschnittlicher Preis der Produkte in einer Kategorie
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// Verbindet Produkt-Tags zu einer Zeichenkette
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Wenn wir Ergebnisse aggregieren müssen, die bereits selbst aus einer Aggregationsfunktion und Gruppierung hervorgegangen sind
(z. B. SUM(wert) über gruppierte Zeilen), geben wir als zweites Argument die Aggregationsfunktion an, die auf diese
Zwischenergebnisse angewendet werden soll:
// Berechnet den Gesamtpreis der Produkte auf Lager für einzelne Kategorien und summiert dann diese Preise.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
In diesem Beispiel berechnen wir zuerst den Gesamtpreis der Produkte in jeder Kategorie
(SUM(price * stock) AS category_total) und gruppieren die Ergebnisse nach category_id. Dann verwenden
wir aggregation('SUM(category_total)', 'SUM'), um diese Zwischensummen category_total zu addieren. Das
zweite Argument 'SUM' gibt an, dass die SUM-Funktion auf die Zwischenergebnisse angewendet
werden soll.
Insert, Update & Delete
Nette Database Explorer vereinfacht das Einfügen, Aktualisieren und Löschen von Daten. Alle genannten Methoden werfen im
Fehlerfall eine Nette\Database\DriverException.
Selection::insert (iterable $data)
Fügt neue Datensätze in die Tabelle ein.
Einfügen eines einzelnen Datensatzes:
Den neuen Datensatz übergeben wir als assoziatives Array oder iterable Objekt (zum Beispiel ArrayHash, das in Formularen verwendet wird), wobei die Schlüssel den Spaltennamen in der Tabelle
entsprechen.
Wenn die Tabelle einen definierten Primärschlüssel hat, gibt die Methode ein ActiveRow-Objekt zurück, das aus
der Datenbank neu geladen wird, um eventuelle Änderungen auf Datenbankebene (Trigger, Standardwerte von Spalten, Berechnungen von
Auto-Increment-Spalten) zu berücksichtigen. Dadurch wird die Datenkonsistenz gewährleistet und das Objekt enthält immer die
aktuellen Daten aus der Datenbank. Wenn es keinen eindeutigen Primärschlüssel gibt, gibt sie die übergebenen Daten in Form
eines Arrays zurück.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row ist eine Instanz von ActiveRow und enthält die vollständigen Daten der eingefügten Zeile,
// einschließlich der automatisch generierten ID und eventueller durch Trigger vorgenommener Änderungen
echo $row->id; // Gibt die ID des neu eingefügten Benutzers aus
echo $row->created_at; // Gibt die Erstellungszeit aus, falls sie durch einen Trigger gesetzt wurde
Einfügen mehrerer Datensätze auf einmal:
Die Methode insert() ermöglicht das Einfügen mehrerer Datensätze mit einer einzigen SQL-Abfrage. In diesem Fall
gibt sie die Anzahl der eingefügten Zeilen zurück.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows wird 2 sein
Als Parameter kann auch ein Selection-Objekt mit einer Datenauswahl übergeben werden.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Einfügen spezieller Werte:
Als Werte können wir auch Dateien, DateTime-Objekte oder SQL-Literale übergeben:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // konvertiert in Datenbankformat
'avatar' => fopen('image.jpg', 'rb'), // fügt binären Inhalt der Datei ein
'uuid' => $explorer::literal('UUID()'), // ruft die Funktion UUID() auf
]);
Selection::update (iterable $data): int
Aktualisiert Zeilen in der Tabelle gemäß dem angegebenen Filter. Gibt die Anzahl der tatsächlich geänderten Zeilen zurück.
Die zu ändernden Spalten übergeben wir als assoziatives Array oder iterable Objekt (zum Beispiel ArrayHash, das
in Formularen verwendet wird), wobei die Schlüssel den Spaltennamen in der Tabelle
entsprechen:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Zur Änderung numerischer Werte können Sie die Operatoren += und -= verwenden:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // erhöht den Wert der Spalte 'points' um 1
'coins-=' => 1, // verringert den Wert der Spalte 'coins' um 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Löscht Zeilen aus der Tabelle gemäß dem angegebenen Filter. Gibt die Anzahl der gelöschten Zeilen zurück.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Vergessen Sie beim Aufrufen von update() und delete() nicht, mit where()
die Zeilen anzugeben, die geändert bzw. gelöscht werden sollen. Wenn Sie where() nicht verwenden, wird die
Operation auf die gesamte Tabelle angewendet!
ActiveRow::update (iterable $data): bool
Aktualisiert Daten in der Datenbankzeile, die durch das ActiveRow-Objekt repräsentiert wird. Als Parameter
akzeptiert es ein Iterable mit Daten, die aktualisiert werden sollen (Schlüssel sind Spaltennamen). Zur Änderung numerischer
Werte können Sie die Operatoren += und -= verwenden:
Nach der Durchführung der Aktualisierung wird ActiveRow automatisch aus der Datenbank neu geladen, um eventuelle
Änderungen auf Datenbankebene (z. B. Trigger) zu berücksichtigen. Die Methode gibt true zurück, nur wenn
tatsächlich Daten geändert wurden.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // erhöhen die Anzahl der Ansichten
]);
echo $article->views; // Gibt die aktuelle Anzahl der Ansichten aus
Diese Methode aktualisiert nur eine bestimmte Zeile in der Datenbank. Für die Massenaktualisierung mehrerer Zeilen verwenden Sie die Methode Selection::update().
ActiveRow::delete()
Löscht die Zeile aus der Datenbank, die durch das ActiveRow-Objekt repräsentiert wird.
$book = $explorer->table('book')->get(1);
$book->delete(); // Löscht das Buch mit der ID 1
Diese Methode löscht nur eine bestimmte Zeile in der Datenbank. Für das Massenlöschen mehrerer Zeilen verwenden Sie die Methode Selection::delete().
Beziehungen zwischen Tabellen
In relationalen Datenbanken sind Daten auf mehrere Tabellen verteilt und über Fremdschlüssel miteinander verbunden. Nette Database Explorer bietet eine revolutionäre Möglichkeit, mit diesen Beziehungen zu arbeiten – ohne JOIN-Abfragen zu schreiben und ohne die Notwendigkeit, etwas zu konfigurieren oder zu generieren.
Zur Veranschaulichung der Arbeit mit Beziehungen verwenden wir das Beispiel einer Buchdatenbank (finden Sie auf GitHub). In der Datenbank haben wir folgende Tabellen:
author– Schriftsteller und Übersetzer (Spaltenid,name,web,born)book– Bücher (Spaltenid,author_id,translator_id,title,sequel_id)tag– Schlagwörter (Spaltenid,name)book_tag– Verknüpfungstabelle zwischen Büchern und Schlagwörtern (Spaltenbook_id,tag_id)
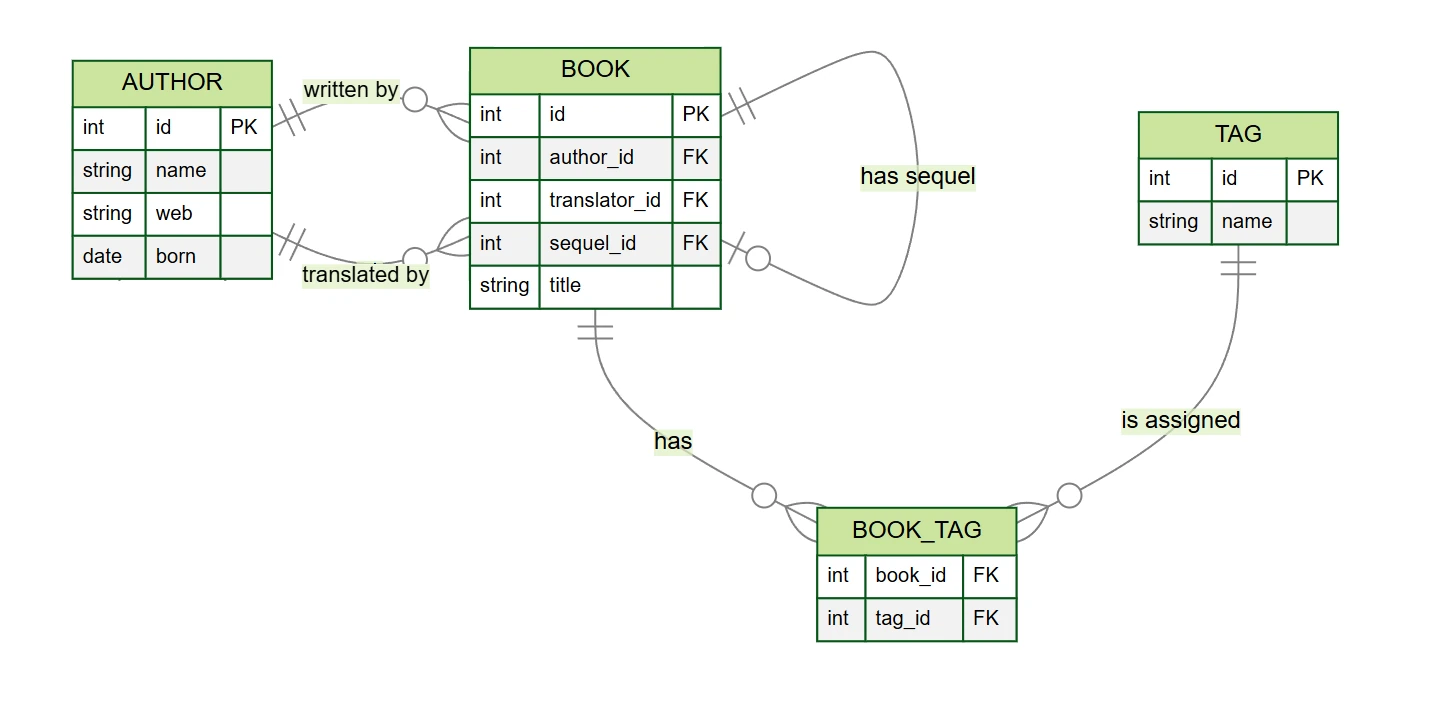
In unserem Beispiel der Buchdatenbank finden wir verschiedene Arten von Beziehungen (obwohl das Modell im Vergleich zur Realität vereinfacht ist):
- One-to-many 1:N – jedes Buch hat einen Autor, ein Autor kann mehrere Bücher schreiben
- Zero-to-many 0:N – ein Buch kann einen Übersetzer haben, ein Übersetzer kann mehrere Bücher übersetzen
- Zero-to-one 0:1 – ein Buch kann einen weiteren Teil haben
- Many-to-many M:N – ein Buch kann mehrere Schlagwörter haben und ein Schlagwort kann mehreren Büchern zugeordnet sein
In diesen Beziehungen gibt es immer eine übergeordnete und eine untergeordnete Tabelle. Zum Beispiel ist in der Beziehung
zwischen Autor und Buch die Tabelle author übergeordnet und book untergeordnet – man kann sich
vorstellen, dass ein Buch immer einem Autor “gehört”. Dies spiegelt sich auch in der Datenbankstruktur wider: Die
untergeordnete Tabelle book enthält den Fremdschlüssel author_id, der auf die übergeordnete Tabelle
author verweist.
Wenn wir Bücher einschließlich der Namen ihrer Autoren auflisten müssen, haben wir zwei Möglichkeiten. Entweder erhalten
wir die Daten mit einer einzigen SQL-Abfrage mittels LEFT JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Oder wir laden die Daten in zwei Schritten – zuerst die Bücher und dann ihre Autoren – und fügen sie dann in PHP zusammen:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- IDs der Autoren der abgerufenen Bücher
Der zweite Ansatz ist tatsächlich effizienter, auch wenn das überraschend sein mag. Die Daten werden nur einmal pro Tabelle geladen und können besser im Cache genutzt werden. Genau auf diese Weise arbeitet Nette Database Explorer – alles wird unter der Haube gelöst und Ihnen wird eine elegante API geboten:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Titel: ' . $book->title;
echo 'geschrieben von: ' . $book->author->name; // $book->author ist der Datensatz aus der Tabelle 'author'
echo 'übersetzt von: ' . $book->translator?->name;
}
Zugriff auf die übergeordnete Tabelle
Der Zugriff auf die übergeordnete Tabelle ist unkompliziert. Es handelt sich um Beziehungen wie ein Buch hat einen
Autor oder ein Buch kann einen Übersetzer haben. Den zugehörigen Datensatz erhalten wir über eine Eigenschaft des
ActiveRow-Objekts. Der Name der Eigenschaft entspricht dem Namen der Spalte mit dem Fremdschlüssel, jedoch ohne das
Suffix _id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // findet den Autor über die Spalte author_id
echo $book->translator?->name; // findet den Übersetzer über translator_id (nullsafe)
Wenn Sie auf die Eigenschaft $book->author zugreifen, sucht der Explorer in der Tabelle book nach
einer Spalte, deren Name auf author endet und auf _id endet (also author_id). Anhand des
Wertes in dieser Spalte lädt er den entsprechenden Datensatz aus der Tabelle author und gibt ihn als
ActiveRow zurück. Ähnlich funktioniert auch $book->translator, das die Spalte
translator_id verwendet. Da die Spalte translator_id NULL enthalten kann, verwenden wir im
Code den Nullsafe-Operator ?->.
Einen alternativen Weg bietet die Methode ref(), die zwei Argumente akzeptiert: den Namen der Zieltabelle und
optional den Namen der Verbindungspalte. Sie gibt eine Instanz von ActiveRow oder null zurück:
echo $book->ref('author', 'author_id')->name; // Beziehung zum Autor
echo $book->ref('author', 'translator_id')->name; // Beziehung zum Übersetzer
Die Methode ref() ist nützlich, wenn der Name der Beziehung nicht eindeutig aus dem Spaltennamen abgeleitet
werden kann oder wenn Sie eine explizite Steuerung bevorzugen.
Der Explorer optimiert Datenbankabfragen automatisch. Wenn Sie Bücher in einer Schleife durchlaufen und auf ihre zugehörigen
Datensätze (Autoren, Übersetzer) zugreifen, generiert der Explorer nicht für jedes Buch eine separate Abfrage. Stattdessen
führt er nur eine SELECT-Abfrage pro referenzierter Tabelle durch, was die Datenbanklast erheblich reduziert. Zum
Beispiel:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Dieser Code führt nur diese drei blitzschnellen Abfragen an die Datenbank aus:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id aus der Spalte author_id der ausgewählten Bücher
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id aus der Spalte translator_id der ausgewählten Bücher
Die Logik zur Erkennung der Beziehung basiert auf den Conventions. Wir empfehlen die Verwendung von DiscoveredConventions, die Fremdschlüssel analysiert und die einfache Arbeit mit bestehenden Beziehungen zwischen Tabellen ermöglicht.
Zugriff auf die untergeordnete Tabelle
Der Zugriff auf die untergeordnete Tabelle funktioniert in umgekehrter Richtung. Nun fragen wir welche Bücher hat dieser
Autor geschrieben oder welche Bücher hat dieser Übersetzer übersetzt. Für diesen Abfragetyp verwenden wir die
Methode related(), die eine Selection mit den zugehörigen Datensätzen zurückgibt. Sehen wir uns ein
Beispiel an:
$author = $explorer->table('author')->get(1);
// Gibt alle Bücher des Autors aus
foreach ($author->related('book.author_id') as $book) {
echo "Geschrieben: $book->title";
}
// Gibt alle Bücher aus, die der Autor übersetzt hat
foreach ($author->related('book.translator_id') as $book) {
echo "Übersetzt: $book->title";
}
Die Methode related() akzeptiert die Beschreibung der Beziehung als ein Argument mit Punktnotation
(Zieltabelle.Fremdschlüsselspalte) oder als zwei separate Argumente (Zieltabelle,
Fremdschlüsselspalte):
$author->related('book.translator_id'); // ein Argument
$author->related('book', 'translator_id'); // zwei Argumente
Der Explorer kann die korrekte Verbindungspalte oft automatisch erkennen, wenn sie den Konventionen folgt (z.B.
zieltabelle_id). In diesem Fall würde die Verbindung über die Spalte book.author_id erfolgen, da der
Name der Quelltabelle author ist und die Zieltabelle book heißt:
$author->related('book'); // verwendet book.author_id
Wenn mehrere mögliche Beziehungen bestehen oder die Spalte nicht den Konventionen entspricht, wirft der Explorer eine AmbiguousReferenceKeyException.
Die Methode related() können Sie natürlich auch beim Durchlaufen mehrerer Datensätze in einer Schleife
verwenden, und der Explorer optimiert auch in diesem Fall die Abfragen automatisch:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' hat geschrieben:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Dieser Code generiert nur zwei blitzschnelle SQL-Abfragen:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id der ausgewählten Autoren
Many-to-Many-Beziehung
Für eine Many-to-many-Beziehung (M:N) ist die Existenz einer Verknüpfungstabelle erforderlich (in unserem Fall
book_tag), die zwei Spalten mit Fremdschlüsseln (book_id, tag_id) enthält. Jede dieser
Spalten verweist auf den Primärschlüssel einer der verbundenen Tabellen. Um die zugehörigen Daten zu erhalten, holen wir zuerst
die Datensätze aus der Verknüpfungstabelle mit related('book_tag') und fahren dann mit den Zieldaten fort:
$book = $explorer->table('book')->get(1);
// gibt die Namen der dem Buch zugewiesenen Tags aus
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // gibt den Namen des Tags über die Verknüpfungstabelle aus
}
$tag = $explorer->table('tag')->get(1);
// oder umgekehrt: gibt die Namen der mit diesem Tag gekennzeichneten Bücher aus
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // gibt den Namen des Buches aus
}
Der Explorer optimiert die SQL-Abfragen wieder in eine effiziente Form:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id der ausgewählten Bücher
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id der in book_tag gefundenen Tags
Abfragen über verwandte Tabellen
In den Methoden where(), select(), order() und group() können Sie
spezielle Notationen verwenden, um auf Spalten aus verbundenen Tabellen zuzugreifen. Der Explorer erstellt automatisch die
erforderlichen JOINs.
Punktnotation (referenzierte_tabelle.spalte) wird für Many-to-One- oder One-to-One-Beziehungen verwendet
(Zugriff auf die übergeordnete Tabelle):
$books = $explorer->table('book');
// Findet Bücher, deren Autorname mit 'Jon' beginnt
$books->where('author.name LIKE ?', 'Jon%');
// Sortiert Bücher nach Autorennamen absteigend
$books->order('author.name DESC');
// Gibt den Buchtitel und den Autorennamen aus
$books->select('book.title, author.name');
Doppelpunktnotation (:untergeordnete_tabelle.spalte) wird für die 1:N-Beziehung aus Sicht der
übergeordneten Tabelle verwendet:
$authors = $explorer->table('author');
// Findet Autoren, die ein Buch mit 'PHP' im Titel geschrieben haben
$authors->where(':book.title LIKE ?', '%PHP%');
// Zählt die Anzahl der Bücher für jeden Autor
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
Im obigen Beispiel mit der Doppelpunktnotation (:book.title) ist die Spalte mit dem Fremdschlüssel nicht
angegeben. Der Explorer erkennt automatisch die richtige Spalte anhand des Namens der übergeordneten Tabelle. In diesem Fall wird
über die Spalte book.author_id verbunden, da der Name der Quelltabelle author ist. Wenn mehrere
mögliche Verbindungen bestehen, wirft der Explorer eine AmbiguousReferenceKeyException.
Die Verbindungspalte kann explizit in Klammern angegeben werden:
// Findet Autoren, die ein Buch mit 'PHP' im Titel übersetzt haben
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Notationen können für den Zugriff über mehrere Tabellen verkettet werden:
// Findet Autoren von Büchern, die mit dem Tag 'PHP' gekennzeichnet sind
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Erweiterung der Bedingungen für JOIN
Die Methode joinWhere() erweitert die Bedingungen, die in der ON-Klausel beim Verknüpfen von
Tabellen in SQL angegeben werden.
Nehmen wir an, wir möchten Bücher finden, die von einem bestimmten Übersetzer übersetzt wurden, und wir möchten die
Bedingung direkt in den JOIN einbauen:
// Findet Bücher, die vom Übersetzer namens 'David' übersetzt wurden
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
In der joinWhere()-Bedingung können wir dieselben Konstrukte wie in der where()-Methode
verwenden – Operatoren, Fragezeichen-Platzhalter, Wertearrays oder SQL-Ausdrücke.
Für komplexere Abfragen mit mehreren JOINs können wir Tabellenaliase definieren:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Beachten Sie den Unterschied: Während die where()-Methode Bedingungen zur WHERE-Klausel hinzufügt,
erweitert die joinWhere()-Methode die Bedingungen in der ON-Klausel beim Verknüpfen von Tabellen.