Database Explorer
Explorer предлагает интуитивно понятный и эффективный способ работы с базой данных. Он автоматически заботится о связях между таблицами и оптимизации запросов, так что вы можете сосредоточиться на своем приложении. Работает сразу без настройки. Если вам нужен полный контроль над SQL-запросами, вы можете использовать SQL-подход.
- Работа с данными естественна и легко понятна
- Генерирует оптимизированные SQL-запросы, которые загружают только необходимые данные
- Обеспечивает легкий доступ к связанным данным без необходимости писать JOIN-запросы
- Работает мгновенно без какой-либо конфигурации или генерации сущностей
С Explorer вы начинаете с вызова метода table() объекта Nette\Database\Explorer (подробности о
подключении см. в главе Подключение и
конфигурация):
$books = $explorer->table('book'); // 'book' - имя таблицы
Метод возвращает объект Selection, который
представляет SQL-запрос. К этому объекту можно добавлять другие методы
для фильтрации и сортировки результатов. Запрос составляется и
выполняется только в тот момент, когда мы начинаем запрашивать данные.
Например, при прохождении циклом foreach. Каждая строка
представлена объектом ActiveRow:
foreach ($books as $book) {
echo $book->title; // вывод столбца 'title'
echo $book->author_id; // вывод столбца 'author_id'
}
Explorer существенно упрощает работу со связями между таблицами. Следующий пример показывает, как легко можно вывести данные из связанных таблиц (книги и их авторы). Обратите внимание, что нам не нужно писать никаких JOIN-запросов, Nette создаст их за нас:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Книга: ' . $book->title;
echo 'Автор: ' . $book->author->name; // создаст JOIN к таблице 'author'
}
Nette Database Explorer оптимизирует запросы, чтобы они были максимально эффективными. Вышеуказанный пример выполнит только два SELECT-запроса, независимо от того, обрабатываем ли мы 10 или 10 000 книг.
Кроме того, Explorer отслеживает, какие столбцы используются в коде, и загружает из базы данных только их, тем самым экономя дополнительную производительность. Это поведение полностью автоматическое и адаптивное. Если вы позже измените код и начнете использовать другие столбцы, Explorer автоматически изменит запросы. Вам не нужно ничего настраивать или думать о том, какие столбцы вам понадобятся – оставьте это Nette.
Фильтрация и сортировка
Класс Selection предоставляет методы для фильтрации и сортировки
выборки данных.
where($condition, ...$params) |
Добавляет условие WHERE. Несколько условий соединяются оператором AND |
whereOr(array $conditions) |
Добавляет группу условий WHERE, соединенных оператором OR |
wherePrimary($value) |
Добавляет условие WHERE по первичному ключу |
order($columns, ...$params) |
Устанавливает сортировку ORDER BY |
select($columns, ...$params) |
Указывает столбцы, которые должны быть загружены |
limit($limit, $offset = null) |
Ограничивает количество строк (LIMIT) и опционально устанавливает OFFSET |
page($page, $itemsPerPage, &$total = null) |
Устанавливает пагинацию |
group($columns, ...$params) |
Группирует строки (GROUP BY) |
having($condition, ...$params) |
Добавляет условие HAVING для фильтрации сгруппированных строк |
Методы можно вызывать цепочкой (так называемый fluent
interface): $table->where(...)->order(...)->limit(...).
В этих методах вы также можете использовать специальную нотацию для доступа к данным из связанных таблиц.
Экранирование и идентификаторы
Методы автоматически экранируют параметры и заключают идентификаторы (имена таблиц и столбцов) в кавычки, тем самым предотвращая SQL-инъекции. Для правильной работы необходимо соблюдать несколько правил:
- Ключевые слова, имена функций, процедур и т.д. пишите заглавными буквами.
- Имена столбцов и таблиц пишите строчными буквами.
- Строки всегда передавайте через параметры.
where('name = ' . $name); // КРИТИЧЕСКАЯ УЯЗВИМОСТЬ: SQL-инъекция
where('name LIKE "%search%"'); // НЕПРАВИЛЬНО: усложняет автоматическое заключение в кавычки
where('name LIKE ?', '%search%'); // ПРАВИЛЬНО: значение передано через параметр
where('name like ?', $name); // НЕПРАВИЛЬНО: сгенерирует: `name` `like` ?
where('name LIKE ?', $name); // ПРАВИЛЬНО: сгенерирует: `name` LIKE ?
where('LOWER(name) = ?', $value);// ПРАВИЛЬНО: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Фильтрует результаты с помощью условий WHERE. Ее сильной стороной является интеллектуальная работа с различными типами значений и автоматический выбор SQL-операторов.
Основное использование:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Благодаря автоматическому определению подходящих операторов нам не нужно решать различные специальные случаи. Nette решит их за нас:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// можно использовать и заполнитель в виде вопросительного знака без оператора:
$table->where('id ?', 1); // WHERE `id` = 1
Метод правильно обрабатывает и отрицательные условия, и пустые массивы:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- ничего не найдет
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- найдет все
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- найдет все
// $table->where('NOT id ?', $ids); Внимание - этот синтаксис не поддерживается
В качестве параметра можно передать также результат из другой таблицы – создастся подзапрос:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Условия можно передать также в виде массива, элементы которого соединяются с помощью AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
В массиве можно использовать пары ключ ⇒ значение, и Nette снова автоматически выберет правильные операторы:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
В массиве можно комбинировать SQL-выражения с заполнителями в виде вопросительных знаков и несколькими параметрами. Это подходит для сложных условий с точно определенными операторами:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // два параметра передаем как массив
]);
Множественные вызовы where() автоматически соединяют условия с
помощью AND.
whereOr (array $parameters): static
Подобно where() добавляет условия, но с тем отличием, что
соединяет их с помощью OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Здесь также можно использовать более сложные выражения:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Добавляет условие для первичного ключа таблицы:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Если таблица имеет составной первичный ключ (например, foo_id,
bar_id), передаем его как массив:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Определяет порядок, в котором будут возвращены строки. Можно сортировать по одному или нескольким столбцам, в убывающем или возрастающем порядке, или по собственному выражению:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Указывает столбцы, которые должны быть возвращены из базы данных. По
умолчанию Nette Database Explorer возвращает только те столбцы, которые реально
используются в коде. Метод select() мы используем в случаях, когда
нужно вернуть специфические выражения:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Псевдонимы, определенные с помощью AS, затем доступны как
свойства объекта ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // доступ к псевдониму
}
limit (?int $limit, ?int $offset = null): static
Ограничивает количество возвращаемых строк (LIMIT) и опционально позволяет установить смещение:
$table->limit(10); // LIMIT 10 (вернет первые 10 строк)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Для пагинации удобнее использовать метод page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Упрощает пагинацию результатов. Принимает номер страницы (считая от 1) и количество элементов на страницу. Опционально можно передать ссылку на переменную, в которую будет сохранено общее количество страниц:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Всего страниц: $numOfPages";
group (string $columns, …$parameters): static
Группирует строки по указанным столбцам (GROUP BY). Обычно используется в сочетании с агрегатными функциями:
// Подсчитывает количество продуктов в каждой категории
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Устанавливает условие для фильтрации сгруппированных строк (HAVING).
Можно использовать в сочетании с методом group() и агрегатными
функциями:
// Находит категории, в которых более 100 продуктов
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Чтение данных
Для чтения данных из базы данных у нас есть несколько полезных методов:
foreach ($table as $key => $row) |
Итерирует по всем строкам, $key – значение первичного ключа,
$row – объект ActiveRow |
$row = $table->get($key) |
Возвращает одну строку по первичному ключу |
$row = $table->fetch() |
Возвращает текущую строку и перемещает указатель на следующую |
$array = $table->fetchPairs() |
Создает ассоциативный массив из результатов |
$array = $table->fetchAll() |
Возвращает все строки как массив |
count($table) |
Возвращает количество строк в объекте Selection |
Объект ActiveRow предназначен только для чтения. Это означает, что нельзя изменять значения его свойств. Это ограничение обеспечивает консистентность данных и предотвращает неожиданные побочные эффекты. Данные загружаются из базы данных, и любое изменение должно быть выполнено явно и контролируемо.
foreach – итерация по всем строкам
Самый простой способ выполнить запрос и получить строки — это
итерация в цикле foreach. Автоматически запускает SQL-запрос.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key - значение первичного ключа, $book - ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Выполняет SQL-запрос и возвращает строку по первичному ключу, или
null, если она не существует.
$book = $explorer->table('book')->get(123); // вернет ActiveRow с ID 123 или null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Возвращает строку и перемещает внутренний указатель на следующую.
Если больше нет строк, возвращает null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Возвращает результаты как ассоциативный массив. Первый аргумент указывает имя столбца, который будет использоваться как ключ в массиве, второй аргумент указывает имя столбца, который будет использоваться как значение:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Если указать только первый параметр, значением будет вся строка, то
есть объект ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
В случае дублирующихся ключей используется значение из последней
строки. При использовании null в качестве ключа массив будет
индексирован численно с нуля (тогда коллизий не происходит):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Альтернативно, вы можете указать в качестве параметра callback, который для каждой строки будет возвращать либо само значение, либо пару ключ-значение.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Первая книга (Ян Новак)', ...]
// Callback может также возвращать массив с парой ключ & значение:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Первая книга' => 'Ян Новак', ...]
fetchAll(): array
Возвращает все строки как ассоциативный массив объектов
ActiveRow, где ключами являются значения первичных ключей.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Метод count() без параметра возвращает количество строк в
объекте Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // альтернатива
Внимание, count() с параметром выполняет агрегатную функцию COUNT в
базе данных, см. ниже.
ActiveRow::toArray(): array
Преобразует объект ActiveRow в ассоциативный массив, где ключами
являются имена столбцов, а значениями — соответствующие данные.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray будет ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Агрегация
Класс Selection предоставляет методы для легкого выполнения
агрегатных функций (COUNT, SUM, MIN, MAX, AVG и т.д.).
count($expr) |
Подсчитывает количество строк |
min($expr) |
Возвращает минимальное значение в столбце |
max($expr) |
Возвращает максимальное значение в столбце |
sum($expr) |
Возвращает сумму значений в столбце |
aggregation($function) |
Позволяет выполнить любую агрегатную функцию. Напр.
AVG(), GROUP_CONCAT() |
count (string $expr): int
Выполняет SQL-запрос с функцией COUNT и возвращает результат. Метод используется для определения, сколько строк соответствует определенному условию:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Внимание, count() без параметра только возвращает
количество строк в объекте Selection.
min (string $expr) и max(string $expr)
Методы min() и max() возвращают минимальное и максимальное
значение в указанном столбце или выражении:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Возвращает сумму значений в указанном столбце или выражении:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Позволяет выполнить любую агрегатную функцию.
// средняя цена продуктов в категории
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// соединяет теги продукта в одну строку
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Если нам нужно агрегировать результаты, которые уже сами по себе
получены из какой-либо агрегатной функции и группировки (например,
SUM(значение) по сгруппированным строкам), в качестве второго
аргумента указываем агрегатную функцию, которая должна быть применена
к этим промежуточным результатам:
// Вычисляет общую цену продуктов на складе для отдельных категорий, а затем суммирует эти цены.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
В этом примере мы сначала вычисляем общую цену продуктов в каждой
категории (SUM(price * stock) AS category_total) и группируем результаты по
category_id. Затем используем aggregation('SUM(category_total)', 'SUM') для
суммирования этих промежуточных сумм category_total. Второй аргумент
'SUM' говорит, что к промежуточным результатам должна быть
применена функция SUM.
Insert, Update & Delete
Nette Database Explorer упрощает вставку, обновление и удаление данных. Все
указанные методы в случае ошибки выбрасывают исключение
Nette\Database\DriverException.
Selection::insert (iterable $data)
Вставляет новые записи в таблицу.
Вставка одной записи:
Новую запись передаем как ассоциативный массив или итерируемый объект (например, ArrayHash, используемый в формах), где ключи соответствуют именам столбцов в таблице.
Если в таблице определен первичный ключ, метод возвращает объект
ActiveRow, который перезагружается из базы данных, чтобы учесть
возможные изменения, выполненные на уровне базы данных (триггеры,
значения по умолчанию столбцов, вычисления автоинкрементных
столбцов). Этим обеспечивается консистентность данных, и объект всегда
содержит актуальные данные из базы данных. Если однозначного
первичного ключа нет, возвращает переданные данные в виде массива.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row - экземпляр ActiveRow и содержит полные данные вставленной строки,
// включая автоматически сгенерированный ID и возможные изменения, выполненные триггерами
echo $row->id; // Выведет ID нового вставленного пользователя
echo $row->created_at; // Выведет время создания, если оно установлено триггером
Вставка нескольких записей одновременно:
Метод insert() позволяет вставить несколько записей с помощью
одного SQL-запроса. В этом случае возвращает количество
вставленных строк.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows будет 2
В качестве параметра можно также передать объект Selection с
выборкой данных.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Вставка специальных значений:
В качестве значений можно передавать и файлы, объекты DateTime или SQL-литералы:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // преобразует в формат базы данных
'avatar' => fopen('image.jpg', 'rb'), // вставит бинарное содержимое файла
'uuid' => $explorer::literal('UUID()'), // вызовет функцию UUID()
]);
Selection::update (iterable $data): int
Обновляет строки в таблице согласно указанному фильтру. Возвращает количество действительно измененных строк.
Изменяемые столбцы передаем как ассоциативный массив или итерируемый объект (например, ArrayHash, используемый в формах), где ключи соответствуют именам столбцов в таблице:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Для изменения числовых значений можно использовать операторы
+= и -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // увеличит значение столбца 'points' на 1
'coins-=' => 1, // уменьшит значение столбца 'coins' на 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Удаляет строки из таблицы согласно указанному фильтру. Возвращает количество удаленных строк.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
При вызове update() и delete() не забудьте с помощью
where() указать строки, которые нужно изменить/удалить. Если
where() не использовать, операция будет выполнена над всей
таблицей!
ActiveRow::update (iterable $data): bool
Обновляет данные в строке базы данных, представленной объектом
ActiveRow. В качестве параметра принимает итерируемый объект с
данными, которые нужно обновить (ключи — имена столбцов). Для
изменения числовых значений можно использовать операторы += и
-=:
После выполнения обновления ActiveRow автоматически
перезагружается из базы данных, чтобы учесть возможные изменения,
выполненные на уровне базы данных (например, триггеры). Метод
возвращает true только если произошло действительное изменение
данных.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // увеличим количество просмотров
]);
echo $article->views; // Выведет текущее количество просмотров
Этот метод обновляет только одну конкретную строку в базе данных. Для массового обновления нескольких строк используйте метод Selection::update().
ActiveRow::delete()
Удаляет строку из базы данных, которая представлена объектом
ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Удалит книгу с ID 1
Этот метод удаляет только одну конкретную строку в базе данных. Для массового удаления нескольких строк используйте метод Selection::delete().
Связи между таблицами
В реляционных базах данных данные разделены на несколько таблиц и взаимосвязаны с помощью внешних ключей. Nette Database Explorer предлагает революционный способ работы с этими связями – без написания JOIN-запросов и необходимости что-либо конфигурировать или генерировать.
Для иллюстрации работы со связями используем пример базы данных книг (найдете его на GitHub). В базе данных у нас есть таблицы:
author– писатели и переводчики (столбцыid,name,web,born)book– книги (столбцыid,author_id,translator_id,title,sequel_id)tag– теги (столбцыid,name)book_tag– связующая таблица между книгами и тегами (столбцыbook_id,tag_id)
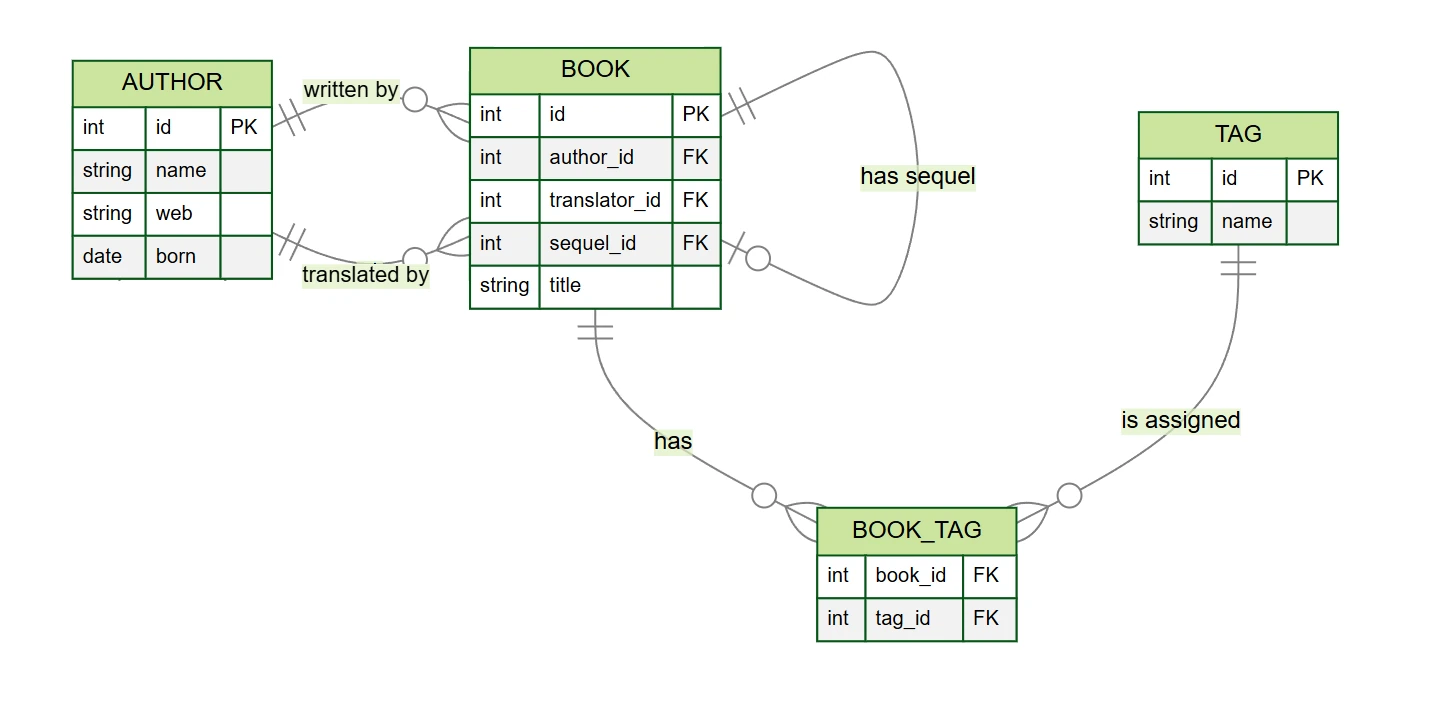
В нашем примере базы данных книг мы находим несколько типов отношений (хотя модель упрощена по сравнению с реальностью):
- Один-ко-многим 1:N – каждая книга имеет одного автора, автор может написать несколько книг
- Ноль-ко-многим 0:N – книга может иметь переводчика, переводчик может перевести несколько книг
- Ноль-к-одному 0:1 – книга может иметь продолжение
- Многие-ко-многим M:N – книга может иметь несколько тегов, и тег может быть присвоен нескольким книгам
В этих отношениях всегда существует родительская и дочерняя таблица.
Например, в отношении между автором и книгой таблица author
является родительской, а book — дочерней – можно представить
это так, что книга всегда “принадлежит” какому-то автору. Это
проявляется и в структуре базы данных: дочерняя таблица book
содержит внешний ключ author_id, который ссылается на родительскую
таблицу author.
Если нам нужно вывести книги, включая имена их авторов, у нас есть два варианта. Либо получить данные одним SQL-запросом с помощью JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Либо загрузить данные в два этапа – сначала книги, а затем их авторов – и потом собрать их в PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- id авторов полученных книг
Второй подход на самом деле более эффективен, хотя это может показаться удивительным. Данные загружаются только один раз и могут быть лучше использованы в кеше. Именно таким образом работает Nette Database Explorer – все решает под капотом и предлагает вам элегантный API:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'название: ' . $book->title;
echo 'написано: ' . $book->author->name; // $book->author - запись из таблицы 'author'
echo 'переведено: ' . $book->translator?->name;
}
Доступ к родительской таблице
Доступ к родительской таблице прост. Речь идет об отношениях типа
книга имеет автора или книга может иметь переводчика.
Связанную запись получаем через свойство объекта ActiveRow – его имя
соответствует имени столбца с внешним ключом без суффикса _id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // найдет автора по столбцу author_id
echo $book->translator?->name; // найдет переводчика по translator_id
Когда мы обращаемся к свойству $book->author, Explorer ищет в таблице
book столбец, имя которого соответствует author (т.е.
author_id). По значению в этом столбце он загружает соответствующую
запись из таблицы author и возвращает ее как ActiveRow.
Аналогично работает и $book->translator, который использует столбец
translator_id. Поскольку столбец translator_id может содержать
null, мы используем в коде nullsafe оператор ?->.
Альтернативный путь предлагает метод ref(), который принимает
два аргумента: имя целевой таблицы и имя связующего столбца, и
возвращает экземпляр ActiveRow или null:
echo $book->ref('author', 'author_id')->name; // связь с автором
echo $book->ref('author', 'translator_id')->name; // связь с переводчиком
Метод ref() удобен, если нельзя использовать доступ через
свойство, потому что таблица содержит столбец с таким же именем (т.е.
author). В остальных случаях рекомендуется использовать доступ
через свойство, который более читабелен.
Explorer автоматически оптимизирует запросы к базе данных. Когда мы проходим по книгам в цикле и обращаемся к их связанным записям (авторам, переводчикам), Explorer не генерирует запрос для каждой книги отдельно. Вместо этого он выполняет только один SELECT для каждого типа связи, тем самым значительно снижая нагрузку на базу данных. Например:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Этот код вызовет только эти три молниеносных запроса к базе данных:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id из столбца author_id выбранных книг
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id из столбца translator_id выбранных книг
Логика поиска связующего столбца задана реализацией Conventions. Рекомендуем использовать DiscoveredConventions, которые анализируют внешние ключи и позволяют легко работать с существующими отношениями между таблицами.
Доступ к дочерней таблице
Доступ к дочерней таблице работает в обратном направлении. Теперь мы
спрашиваем, какие книги написал этот автор или перевел этот
переводчик. Для этого типа запроса мы используем метод related(),
который возвращает Selection со связанными записями. Посмотрим на
пример:
$author = $explorer->table('author')->get(1);
// Выведет все книги автора
foreach ($author->related('book.author_id') as $book) {
echo "Написал: $book->title";
}
// Выведет все книги, которые автор перевел
foreach ($author->related('book.translator_id') as $book) {
echo "Перевел: $book->title";
}
Метод related() принимает описание соединения как один аргумент с
точечной нотацией или как два отдельных аргумента:
$author->related('book.translator_id'); // один аргумент
$author->related('book', 'translator_id'); // два аргумента
Explorer может автоматически определить правильный связующий столбец на
основе имени родительской таблицы. В данном случае соединение
происходит через столбец book.author_id, поскольку имя исходной
таблицы — author:
$author->related('book'); // использует book.author_id
Если бы существовало несколько возможных соединений, Explorer выбросил бы исключение AmbiguousReferenceKeyException.
Метод related() можно, конечно, использовать и при прохождении
нескольких записей в цикле, и Explorer и в этом случае автоматически
оптимизирует запросы:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' написал:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Этот код сгенерирует только два молниеносных SQL-запроса:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id выбранных авторов
Связь Many-to-many
Для связи многие-ко-многим (M:N) необходимо наличие связующей таблицы
(в нашем случае book_tag), которая содержит два столбца с внешними
ключами (book_id, tag_id). Каждый из этих столбцов ссылается на
первичный ключ одной из связываемых таблиц. Для получения связанных
данных сначала получаем записи из связующей таблицы с помощью
related('book_tag'), а затем переходим к целевым данным:
$book = $explorer->table('book')->get(1);
// выведет названия тегов, присвоенных книге
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // выведет название тега через связующую таблицу
}
$tag = $explorer->table('tag')->get(1);
// или наоборот: выведет названия книг, отмеченных этим тегом
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // выведет название книги
}
Explorer снова оптимизирует SQL-запросы до эффективной формы:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id выбранных книг
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id тегов, найденных в book_tag
Запросы через связанные таблицы
В методах where(), select(), order() и group() мы можем
использовать специальные нотации для доступа к столбцам из других
таблиц. Explorer автоматически создаст необходимые JOIN'ы.
Точечная нотация (родительская_таблица.столбец)
используется для отношения 1:N с точки зрения дочерней таблицы:
$books = $explorer->table('book');
// Находит книги, автор которых имеет имя, начинающееся на 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Сортирует книги по имени автора по убыванию
$books->order('author.name DESC');
// Выводит название книги и имя автора
$books->select('book.title, author.name');
Двоеточная нотация (:дочерняя_таблица.столбец)
используется для отношения 1:N с точки зрения родительской таблицы:
$authors = $explorer->table('author');
// Находит авторов, которые написали книгу с 'PHP' в названии
$authors->where(':book.title LIKE ?', '%PHP%');
// Подсчитывает количество книг для каждого автора
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
В вышеприведенном примере с двоеточной нотацией (:book.title) не
указан столбец с внешним ключом. Explorer автоматически определяет
правильный столбец на основе имени родительской таблицы. В данном
случае соединение происходит через столбец book.author_id, поскольку
имя исходной таблицы — author. Если бы существовало несколько
возможных соединений, Explorer выбросил бы исключение AmbiguousReferenceKeyException.
Связующий столбец можно явно указать в скобках:
// Находит авторов, которые перевели книгу с 'PHP' в названии
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Нотации можно объединять в цепочку для доступа через несколько таблиц:
// Находит авторов книг, отмеченных тегом 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Расширение условий для JOIN
Метод joinWhere() расширяет условия, которые указываются при
соединении таблиц в SQL за ключевым словом ON.
Допустим, мы хотим найти книги, переведенные конкретным переводчиком:
// Находит книги, переведенные переводчиком по имени 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
В условии joinWhere() мы можем использовать те же конструкции, что и
в методе where() – операторы, заполнители в виде вопросительных
знаков, массивы значений или SQL-выражения.
Для более сложных запросов с несколькими JOIN'ами мы можем определить псевдонимы таблиц:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Обратите внимание, что в то время как метод where() добавляет
условия в клаузулу WHERE, метод joinWhere() расширяет условия в
клаузуле ON при соединении таблиц.