Database Explorer
Explorer offre un moyen intuitif et efficace de travailler avec votre base de données. Il gère automatiquement les relations entre les tables et l'optimisation des requêtes, vous permettant de vous concentrer sur votre application. Il fonctionne immédiatement sans aucune configuration. Si vous avez besoin d'un contrôle total sur vos requêtes SQL, vous pouvez utiliser l'approche SQL.
- Le travail avec les données est naturel et facile à comprendre
- Génère des requêtes SQL optimisées qui ne chargent que les données nécessaires
- Permet un accès facile aux données liées sans avoir à écrire de requêtes JOIN
- Fonctionne immédiatement sans aucune configuration ni génération d'entités
Vous commencez avec Explorer en appelant la méthode table() sur l'objet Nette\Database\Explorer (les détails sur la
connexion se trouvent dans le chapitre Connexion
et configuration) :
$books = $explorer->table('book'); // 'book' est le nom de la table
La méthode renvoie un objet Selection,
qui représente une requête SQL. Vous pouvez enchaîner d'autres méthodes sur cet objet pour filtrer et trier les résultats. La
requête est construite et exécutée seulement au moment où vous commencez à demander des données, par exemple, en parcourant
une boucle foreach. Chaque ligne est représentée par un objet ActiveRow :
foreach ($books as $book) {
echo $book->title; // Affiche la colonne 'title'
echo $book->author_id; // Affiche la colonne 'author_id'
}
Explorer facilite considérablement le travail avec les relations entre les tables. L'exemple suivant montre avec quelle facilité vous pouvez afficher les données de tables liées (livres et leurs auteurs). Notez que vous n'avez pas besoin d'écrire de requêtes JOIN ; Nette les crée pour vous :
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Livre : ' . $book->title;
echo 'Auteur : ' . $book->author->name; // Crée un JOIN sur la table 'author'
}
Nette Database Explorer optimise les requêtes pour qu'elles soient aussi efficaces que possible. L'exemple ci-dessus n'exécute que deux requêtes SELECT, que vous traitiez 10 ou 10 000 livres.
De plus, Explorer surveille les colonnes utilisées dans votre code et ne charge que celles-ci depuis la base de données, économisant ainsi des ressources. Ce comportement est entièrement automatique et adaptatif. Si vous modifiez ultérieurement votre code et commencez à utiliser d'autres colonnes, Explorer ajuste automatiquement les requêtes. Vous n'avez rien à configurer ni à vous soucier des colonnes dont vous aurez besoin – laissez Nette s'en charger.
Filtrage et tri
La classe Selection fournit des méthodes pour filtrer et trier la sélection de données.
where($condition, ...$params) |
Ajoute une condition WHERE. Plusieurs conditions sont liées par l'opérateur AND |
whereOr(array $conditions) |
Ajoute un groupe de conditions WHERE liées par l'opérateur OR |
wherePrimary($value) |
Ajoute une condition WHERE basée sur la clé primaire |
order($columns, ...$params) |
Définit le tri ORDER BY |
select($columns, ...$params) |
Spécifie les colonnes à charger |
limit($limit, $offset = null) |
Limite le nombre de lignes (LIMIT) et définit éventuellement OFFSET |
page($page, $itemsPerPage, &$total = null) |
Définit la pagination |
group($columns, ...$params) |
Regroupe les lignes (GROUP BY) |
having($condition, ...$params) |
Ajoute une condition HAVING pour filtrer les lignes groupées |
Les méthodes peuvent être enchaînées (ce qu'on appelle une interface fluide) :
$table->where(...)->order(...)->limit(...).
Dans ces méthodes, vous pouvez également utiliser une notation spéciale pour accéder aux données des tables liées.
Échappement et identifiants
Les méthodes échappent automatiquement les paramètres et protègent les identifiants (noms de tables et de colonnes), prévenant ainsi les injections SQL. Pour un fonctionnement correct, il est nécessaire de respecter quelques règles :
- Écrivez les mots-clés SQL, noms de fonctions, procédures, etc. en MAJUSCULES.
- Écrivez les noms de colonnes et de tables en minuscules.
- Insérez toujours les chaînes de caractères via des paramètres.
where('name = ' . $name); // ⚠️ VULNÉRABILITÉ CRITIQUE : injection SQL
where('name LIKE "%search%"'); // ❌ MAUVAIS : complique la protection automatique des identifiants
where('name LIKE ?', '%search%'); // ✅ CORRECT : valeur insérée via un paramètre
where('name like ?', $name); // ❌ MAUVAIS : génère : `name` `like` ? (mot-clé en minuscule)
where('name LIKE ?', $name); // ✅ CORRECT : génère : `name` LIKE ?
where('LOWER(name) = ?', $value);// ✅ CORRECT : génère : LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtre les résultats à l'aide de conditions WHERE. Sa force réside dans sa gestion intelligente des différents types de valeurs et dans le choix automatique des opérateurs SQL appropriés.
Utilisation de base :
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Grâce à la détection automatique des opérateurs appropriés, vous n'avez pas besoin de gérer différents cas spéciaux. Nette s'en charge pour vous :
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// Vous pouvez aussi utiliser un placeholder (?) sans opérateur :
$table->where('id ?', 1); // WHERE `id` = 1
La méthode gère correctement également les conditions négatives et les tableaux vides :
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- ne trouve rien
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- trouve tout
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- trouve tout
// $table->where('NOT id ?', $ids); Attention - cette syntaxe n'est pas supportée
Comme paramètre, vous pouvez également passer le résultat d'une autre table (Selection) – une sous-requête
sera créée :
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Vous pouvez également passer les conditions sous forme de tableau associatif, dont les éléments seront liés par l'opérateur AND :
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
Dans le tableau, vous pouvez utiliser des paires clé => valeur, et Nette choisira à nouveau automatiquement
les opérateurs corrects :
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
Dans le tableau, vous pouvez combiner des expressions SQL avec des placeholders (?) et plusieurs paramètres.
C'est utile pour des conditions complexes avec des opérateurs définis précisément :
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // Deux paramètres passés comme tableau
]);
Les appels multiples à where() lient automatiquement les conditions avec l'opérateur AND.
whereOr (array $parameters): static
Similaire à where(), cette méthode ajoute des conditions, mais les lie avec l'opérateur OR :
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Ici aussi, vous pouvez utiliser des expressions plus complexes :
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Ajoute une condition pour la clé primaire de la table.
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Si la table a une clé primaire composite (par ex. foo_id, bar_id), passez-la comme un tableau
associatif :
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Détermine l'ordre dans lequel les lignes seront retournées. Nous pouvons trier par une ou plusieurs colonnes, par ordre décroissant ou croissant, ou selon une expression personnalisée :
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Spécifie les colonnes à retourner de la base de données. Par défaut, Nette Database Explorer ne retourne que les colonnes
réellement utilisées dans le code. Nous utilisons donc la méthode select() dans les cas où nous avons besoin de
retourner des expressions spécifiques :
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Les alias définis à l'aide de AS sont alors accessibles comme propriétés de l'objet
ActiveRow :
foreach ($table as $row) {
echo $row->formatted_date; // accès à l'alias
}
limit (?int $limit, ?int $offset = null): static
Limite le nombre de lignes retournées (LIMIT) et permet éventuellement de définir un offset :
$table->limit(10); // LIMIT 10 (retourne les 10 premières lignes)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Pour la pagination, il est préférable d'utiliser la méthode page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Facilite la pagination des résultats. Accepte le numéro de page (compté à partir de 1) et le nombre d'éléments par page. Il est possible de passer en option une référence à une variable dans laquelle sera stocké le nombre total de pages :
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Nombre total de pages : $numOfPages";
group (string $columns, …$parameters): static
Regroupe les lignes selon les colonnes spécifiées (GROUP BY). Est généralement utilisé en conjonction avec des fonctions d'agrégation :
// Compte le nombre de produits dans chaque catégorie
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Définit une condition pour filtrer les lignes groupées (HAVING). Peut être utilisé en conjonction avec la méthode
group() et les fonctions d'agrégation :
// Trouve les catégories qui ont plus de 100 produits
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Lecture des données
Pour lire les données de la base de données, vous disposez de plusieurs méthodes utiles :
foreach ($table as $key => $row) |
Itère sur toutes les lignes. $key est la valeur de la clé primaire, $row est l'objet
ActiveRow. |
$row = $table->get($key) |
Retourne une seule ligne identifiée par sa clé primaire. |
$row = $table->fetch() |
Retourne la ligne suivante du résultat. |
$array = $table->fetchPairs($key = null, $value = null) |
Crée un tableau associatif à partir des résultats. |
$array = $table->fetchAll() |
Retourne toutes les lignes sous forme de tableau d'objets ActiveRow. |
count($table) |
Retourne le nombre de lignes dans l'objet Selection (si déjà chargées) ou exécute COUNT(*) si
non chargées. |
L'objet ActiveRow est conçu pour la
lecture seule. Cela signifie que vous ne pouvez pas modifier directement les valeurs de ses propriétés. Cette restriction
garantit la cohérence des données et empêche les effets secondaires inattendus. Les données sont chargées depuis la base de
données, et toute modification doit être effectuée explicitement (par exemple via la méthode update()).
foreach – itération sur toutes les lignes
La manière la plus simple d'exécuter une requête et d'obtenir les lignes est d'itérer sur l'objet Selection
avec une boucle foreach. Cela déclenche automatiquement l'exécution de la requête SQL.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key contient la valeur de la clé primaire, $book est un objet ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Exécute la requête SQL pour récupérer une seule ligne par sa clé primaire et la retourne sous forme d'objet
ActiveRow, ou null si la ligne n'existe pas.
$book = $explorer->table('book')->get(123); // Retourne ActiveRow avec l'ID 123 ou null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Retourne la ligne suivante du jeu de résultats sous forme d'objet ActiveRow et déplace le pointeur interne sur
la suivante. S'il n'y a plus de lignes, retourne null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Retourne les résultats sous forme de tableau associatif. Le premier argument $key spécifie le nom de la colonne
à utiliser comme clé dans le tableau. Le second argument $value spécifie le nom de la colonne à utiliser comme
valeur :
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Si vous ne spécifiez que le premier paramètre $key, la valeur de chaque élément du tableau sera la ligne
entière (objet ActiveRow) :
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
En cas de clés dupliquées, la valeur de la dernière ligne écrasera les précédentes. Si vous utilisez null
comme $key, le tableau sera indexé numériquement à partir de zéro (évitant ainsi les collisions) :
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternativement, vous pouvez passer un callback comme unique paramètre. Ce callback sera appelé pour chaque ligne et devra
retourner soit la valeur à ajouter au tableau, soit une paire [clé, valeur].
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Premier livre (Jan Novák)', ...]
// Le callback peut aussi retourner un tableau [clé, valeur] :
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Premier livre' => 'Jan Novák', ...]
fetchAll(): array
Retourne toutes les lignes du résultat sous forme de tableau d'objets ActiveRow. Les clés du tableau sont les
valeurs des clés primaires des lignes.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
La méthode count() sans argument retourne le nombre de lignes dans l'objet Selection (si les
données ont déjà été chargées) ou exécute une requête SELECT COUNT(*) pour obtenir le nombre total de lignes
correspondant aux conditions définies :
$selection = $explorer->table('book')->where('available', true);
$count = $selection->count();
$count = count($selection); // Alternative, même comportement
Attention, count() avec un argument exécute une fonction d'agrégation COUNT() dans la base de
données.
ActiveRow::toArray(): array
Convertit l'objet ActiveRow en tableau associatif PHP standard, où les clés sont les noms des colonnes et les
valeurs sont les données correspondantes.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray sera ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Agrégation
La classe Selection fournit des méthodes pour effectuer facilement des fonctions d'agrégation SQL (COUNT, SUM,
MIN, MAX, AVG, etc.).
count($expr) |
Compte le nombre de lignes correspondant à l'expression. |
min($expr) |
Retourne la valeur minimale de la colonne/expression. |
max($expr) |
Retourne la valeur maximale de la colonne/expression. |
sum($expr) |
Retourne la somme des valeurs de la colonne/expression. |
aggregation($function, $groupFunction = null) |
Permet d'effectuer une fonction d'agrégation SQL arbitraire (ex: AVG(), GROUP_CONCAT()). |
count (string $expr): int
Exécute une requête SQL avec la fonction COUNT et retourne le résultat. La méthode est utilisée pour compter
le nombre de lignes correspondant à une condition ou une expression :
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Attention, count() sans argument retourne le nombre de lignes dans l'objet Selection (si
déjà chargé) ou exécute COUNT(*) si les données ne sont pas chargées.
min (string $expr) et max(string $expr)
Les méthodes min() et max() retournent la valeur minimale et maximale dans la colonne ou
l'expression spécifiée pour les lignes sélectionnées :
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Retourne la somme des valeurs dans la colonne ou l'expression spécifiée pour les lignes sélectionnées :
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Permet d'exécuter n'importe quelle fonction d'agrégation SQL.
// prix moyen des produits dans la catégorie
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// concatène les étiquettes du produit en une seule chaîne
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Si vous avez besoin d'agréger des résultats qui proviennent déjà eux-mêmes d'une fonction d'agrégation et d'un
regroupement (par ex., calculer la somme de SUM(valeur) sur des lignes groupées), spécifiez comme deuxième
argument $groupFunction la fonction d'agrégation à appliquer à ces résultats intermédiaires :
// Calcule le prix total des produits en stock pour chaque catégorie, puis additionne ces prix.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
Dans cet exemple, nous calculons d'abord le prix total des produits dans chaque catégorie
(SUM(price * stock) AS category_total) et regroupons les résultats par category_id. Ensuite, nous
utilisons aggregation('SUM(category_total)', 'SUM') pour additionner ces sous-totaux category_total. Le
deuxième argument 'SUM' indique que la fonction SUM doit être appliquée aux résultats
intermédiaires (category_total).
Insertion, Mise à jour & Suppression
Nette Database Explorer simplifie l'insertion, la mise à jour et la suppression de données. Toutes les méthodes mentionnées
lèvent une exception Nette\Database\DriverException en cas d'erreur de base de données.
Selection::insert (iterable $data)
Insère un ou plusieurs nouveaux enregistrements dans la table.
Insertion d'un seul enregistrement :
Passez le nouvel enregistrement sous forme de tableau associatif ou d'objet itérable (par exemple,
Nette\Utils\ArrayHash utilisé par les formulaires), où les clés
correspondent aux noms des colonnes de la table.
Si la table a une clé primaire définie, la méthode retourne un objet ActiveRow représentant la ligne
insérée. Cet objet est rechargé depuis la base de données pour refléter les éventuelles modifications effectuées au niveau
de la base de données (triggers, valeurs par défaut, auto-incrément). Cela garantit la cohérence des données. Si la table n'a
pas de clé primaire unique, la méthode retourne les données transmises sous forme de tableau.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row est une instance de ActiveRow et contient les données complètes de la ligne insérée,
// y compris l'ID généré automatiquement (si applicable) et les éventuelles modifications par triggers.
echo $row->id; // Affiche l'ID de l'utilisateur nouvellement inséré
echo $row->created_at; // Affiche l'heure de création, si définie par un trigger ou une valeur par défaut
Insertion de plusieurs enregistrements à la fois :
Passez un tableau de tableaux associatifs ou d'objets itérables. La méthode insert() exécute alors une seule
requête SQL pour insérer toutes les lignes. Dans ce cas, elle retourne le nombre de lignes insérées.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows sera 2
Comme paramètre, on peut également passer un objet Selection avec une sélection de données.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Insertion de valeurs spéciales :
Comme valeurs, nous pouvons également passer des fichiers, des objets DateTime ou des littéraux SQL :
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // Converti au format de base de données
'avatar' => fopen('image.jpg', 'rb'), // Insère le contenu binaire du fichier
'uuid' => $explorer::literal('UUID()'), // Appelle la fonction SQL UUID()
]);
Selection::update (iterable $data): int
Met à jour les lignes de la table correspondant au filtre défini précédemment (par where()). Retourne le
nombre de lignes réellement modifiées.
Passez les colonnes à modifier sous forme de tableau associatif ou d'objet itérable (par exemple, ArrayHash des
formulaires), où les clés correspondent aux noms des colonnes :
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Pour incrémenter ou décrémenter des valeurs numériques, vous pouvez utiliser les opérateurs += et
-= dans les clés du tableau :
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // augmente la valeur de la colonne 'points' de 1
'coins-=' => 1, // diminue la valeur de la colonne 'coins' de 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Supprime les lignes de la table selon le filtre spécifié. Retourne le nombre de lignes supprimées.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Lors de l'appel de update() et delete(), n'oubliez pas de spécifier les lignes à
modifier/supprimer à l'aide de where(). Si vous n'utilisez pas where(), l'opération s'effectuera sur
toute la table !
ActiveRow::update (iterable $data): bool
Met à jour les données de la ligne de base de données représentée par l'objet ActiveRow. Accepte comme
paramètre un itérable (tableau associatif ou objet) avec les données à mettre à jour (les clés sont les noms des colonnes).
Pour incrémenter/décrémenter des valeurs numériques, utilisez les opérateurs += et -= :
Après l'exécution de la mise à jour, les propriétés de l'objet ActiveRow sont automatiquement mises à jour
avec les nouvelles valeurs (elles sont rechargées depuis la base de données pour refléter d'éventuels triggers). La méthode
retourne true si une modification a réellement eu lieu, false sinon.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // augmentons le nombre de vues
]);
echo $article->views; // Affiche le nombre actuel de vues
Cette méthode met à jour uniquement la ligne spécifique représentée par l'objet ActiveRow. Pour une mise à
jour en masse de plusieurs lignes, utilisez la méthode `Selection::update()`.
ActiveRow::delete()
Supprime la ligne de la base de données représentée par l'objet ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Supprime le livre avec l'ID 1
Cette méthode supprime uniquement la ligne spécifique représentée par l'objet ActiveRow. Pour une suppression
en masse de plusieurs lignes, utilisez la méthode `Selection::delete()`.
Relations entre les tables
Dans les bases de données relationnelles, les données sont réparties dans plusieurs tables et reliées entre elles par des clés étrangères. Nette Database Explorer apporte une manière révolutionnaire de travailler avec ces relations – sans écrire de requêtes JOIN et sans avoir besoin de configurer ou de générer quoi que ce soit.
Pour illustrer le travail avec les relations, nous utiliserons l'exemple d'une base de données de livres (vous le trouverez sur GitHub). Dans la base de données, nous avons les tables :
author– écrivains et traducteurs (colonnesid,name,web,born)book– livres (colonnesid,author_id,translator_id,title,sequel_id)tag– étiquettes (colonnesid,name)book_tag– table de liaison entre les livres et les étiquettes (colonnesbook_id,tag_id)
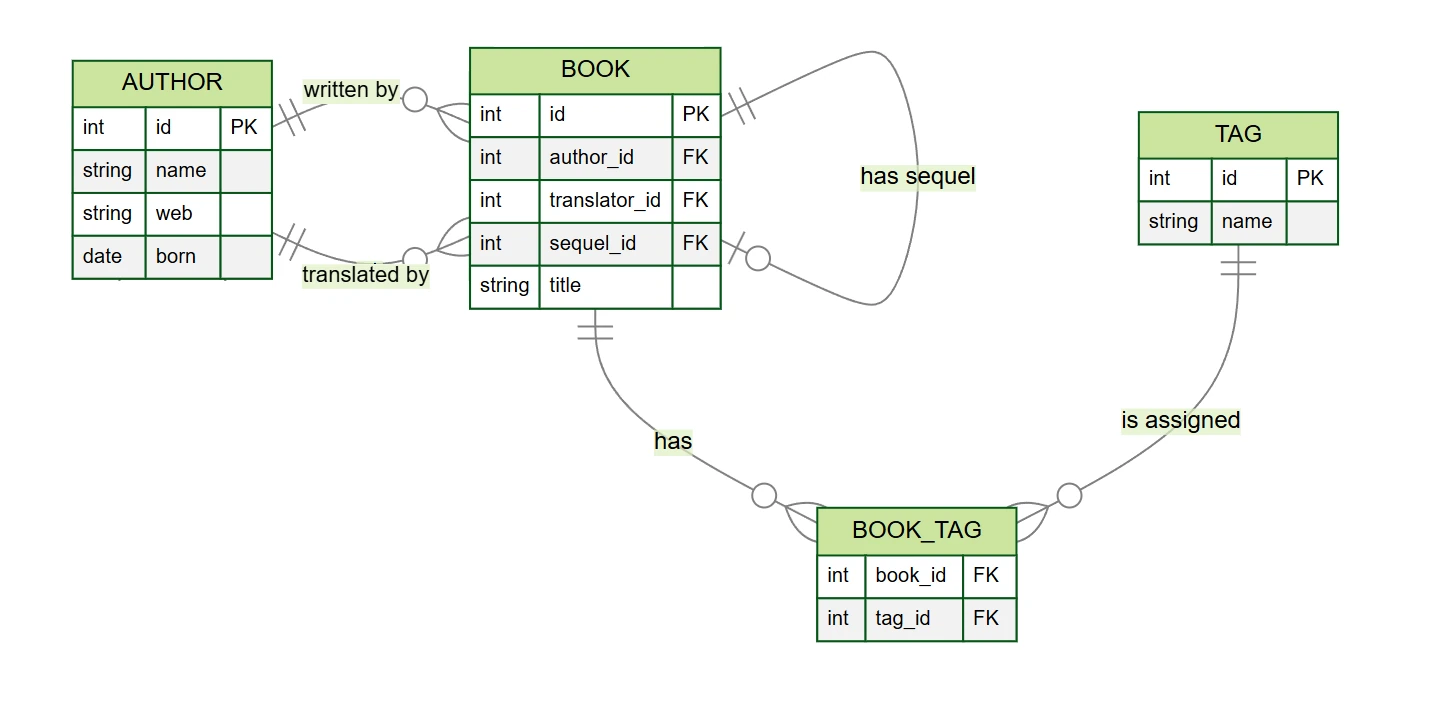
Dans notre exemple de base de données de livres, nous trouvons plusieurs types de relations (bien que le modèle soit simplifié par rapport à la réalité) :
- Un-à-plusieurs 1:N – chaque livre a un auteur, un auteur peut écrire plusieurs livres
- Zéro-à-plusieurs 0:N – un livre peut avoir un traducteur, un traducteur peut traduire plusieurs livres
- Zéro-à-un 0:1 – un livre peut avoir un tome suivant
- Plusieurs-à-plusieurs M:N – un livre peut avoir plusieurs étiquettes et une étiquette peut être attribuée à plusieurs livres
Dans ces relations, il existe toujours une table parente et une table enfant. Par exemple, dans la relation entre l'auteur et
le livre, la table author est parente et book est enfant – on peut imaginer que le livre
“appartient” toujours à un auteur. Cela se reflète également dans la structure de la base de données : la table enfant
book contient une clé étrangère author_id, qui référence la table parente author.
Si nous avons besoin d'afficher les livres y compris les noms de leurs auteurs, nous avons deux options. Soit nous obtenons les données avec une seule requête SQL à l'aide de JOIN :
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Soit nous chargeons les données en deux étapes – d'abord les livres, puis leurs auteurs – et ensuite nous les assemblons en PHP :
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- ids des auteurs des livres obtenus
La deuxième approche est en fait plus efficace, même si cela peut être surprenant. Les données sont chargées une seule fois et peuvent être mieux utilisées dans le cache. C'est précisément de cette manière que fonctionne Nette Database Explorer – tout est géré en arrière-plan et vous offre une API élégante :
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'titre : ' . $book->title;
echo 'écrit par : ' . $book->author->name; // $book->author est l'enregistrement de la table 'author'
echo 'traduit par : ' . $book->translator?->name;
}
Accès à la table parente (Relation N:1)
Accéder à la table parente (la table référencée par une clé étrangère) est très simple. Cela correspond aux relations
comme “un livre a un auteur” ou “un livre peut avoir un traducteur”. Vous obtenez l'enregistrement lié via une
propriété dynamique de l'objet ActiveRow. Le nom de cette propriété correspond au nom de la colonne contenant la
clé étrangère, sans le suffixe _id (par convention) :
$book = $explorer->table('book')->get(1);
echo $book->author->name; // trouve l'auteur selon la colonne author_id
echo $book->translator?->name; // trouve le traducteur selon translator_id
Lorsque vous accédez à la propriété $book->author, Explorer recherche dans la table book une
colonne dont le nom est dérivé de author (généralement author_id). Il utilise la valeur de cette
colonne pour charger l'enregistrement correspondant dans la table author et le retourne sous forme d'objet
ActiveRow. Le même mécanisme s'applique pour $book->translator via la colonne
translator_id. Comme la colonne translator_id peut contenir null, nous utilisons
l'opérateur ?-> dans le code.
Une alternative est la méthode ref(), qui prend deux arguments : le nom de la table cible et (optionnellement) le
nom de la colonne de liaison. Elle retourne l'instance ActiveRow ou null :
echo $book->ref('author', 'author_id')->name; // liaison à l'auteur
echo $book->ref('author', 'translator_id')->name; // liaison au traducteur
La méthode ref() est utile si le nom de la propriété dynamique entre en conflit avec un nom de colonne existant
dans la table (author dans cet exemple). Sinon, l'accès via la propriété est généralement plus lisible et
recommandé.
Explorer optimise automatiquement les requêtes. Lorsque vous parcourez des livres dans une boucle et accédez à leurs enregistrements liés (auteurs, traducteurs), Explorer ne génère pas une requête distincte pour chaque livre. Au lieu de cela, il effectue une seule requête SELECT par type de relation pour récupérer tous les enregistrements liés nécessaires en une seule fois (technique connue sous le nom de “eager loading” implicite), réduisant considérablement la charge de la base de données :
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Ce code n'exécutera que trois requêtes rapides, quel que soit le nombre de livres :
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id de la colonne author_id des livres sélectionnés
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id de la colonne translator_id des livres sélectionnés
La logique de détection de la colonne de liaison est gérée par l'implémentation des Conventions. Nous recommandons l'utilisation de DiscoveredConventions, qui analyse les clés étrangères définies dans votre base de données et permet de travailler facilement avec les relations existantes.
Accès à la table enfant
L'accès à la table enfant fonctionne dans le sens inverse. Nous demandons maintenant quels livres cet auteur a-t-il
écrits ou traduits. Pour ce type de requête, nous utilisons la méthode related(), qui retourne une
Selection avec les enregistrements liés. Regardons un exemple :
$author = $explorer->table('author')->get(1);
// Affiche tous les livres de l'auteur
foreach ($author->related('book.author_id') as $book) {
echo "A écrit : $book->title";
}
// Affiche tous les livres que l'auteur a traduits
foreach ($author->related('book.translator_id') as $book) {
echo "A traduit : $book->title";
}
La méthode related() accepte la description de la liaison comme un seul argument avec la notation par points ou
comme deux arguments séparés :
$author->related('book.translator_id'); // un argument
$author->related('book', 'translator_id'); // deux arguments
Explorer peut détecter automatiquement la colonne de liaison correcte en fonction du nom de la table parente. Dans ce cas, la
liaison se fait via la colonne book.author_id, car le nom de la table source est author :
$author->related('book'); // utilise book.author_id
S'il existait plusieurs liaisons possibles, Explorer lèverait une exception AmbiguousReferenceKeyException.
Nous pouvons bien sûr utiliser la méthode related() également lors du parcours de plusieurs enregistrements
dans une boucle, et Explorer optimise également automatiquement les requêtes dans ce cas :
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' a écrit :';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Ce code ne génère que deux requêtes SQL rapides :
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id des auteurs sélectionnés
Relation Plusieurs-à-plusieurs
Pour une relation plusieurs-à-plusieurs (M:N), l'existence d'une table de liaison est nécessaire (dans notre cas
book_tag), qui contient deux colonnes avec des clés étrangères (book_id, tag_id).
Chacune de ces colonnes référence la clé primaire de l'une des tables liées. Pour obtenir les données liées, nous obtenons
d'abord les enregistrements de la table de liaison à l'aide de related('book_tag') et continuons ensuite vers les
données cibles :
$book = $explorer->table('book')->get(1);
// affiche les noms des étiquettes attribuées au livre
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // affiche le nom de l'étiquette via la table de liaison
}
$tag = $explorer->table('tag')->get(1);
// ou inversement : affiche les noms des livres marqués avec cette étiquette
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // affiche le nom du livre
}
Explorer optimise à nouveau les requêtes SQL en une forme efficace :
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id des livres sélectionnés
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id des étiquettes trouvées dans book_tag
Interrogation via les tables liées
Dans les méthodes where(), select(), order() et group(), nous pouvons
utiliser des notations spéciales pour accéder aux colonnes d'autres tables. Explorer crée automatiquement les JOIN
nécessaires.
Notation par points (table_parente.colonne) est utilisée pour la relation 1:N du point de vue de la table
enfant :
$books = $explorer->table('book');
// Trouve les livres dont l'auteur a un nom commençant par 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Trie les livres par nom d'auteur décroissant
$books->order('author.name DESC');
// Affiche le titre du livre et le nom de l'auteur
$books->select('book.title, author.name');
Notation par deux-points (:table_enfant.colonne) est utilisée pour la relation 1:N du point de vue de la
table parente :
$authors = $explorer->table('author');
// Trouve les auteurs qui ont écrit un livre avec 'PHP' dans le titre
$authors->where(':book.title LIKE ?', '%PHP%');
// Compte le nombre de livres pour chaque auteur
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
Dans l'exemple ci-dessus avec la notation par deux-points (:book.title), la colonne avec la clé étrangère n'est
pas spécifiée. Explorer détecte automatiquement la colonne correcte en fonction du nom de la table parente. Dans ce cas, la
liaison se fait via la colonne book.author_id, car le nom de la table source est author. S'il existait
plusieurs liaisons possibles, Explorer lèverait une exception AmbiguousReferenceKeyException.
La colonne de liaison peut être explicitement indiquée entre parenthèses :
// Trouve les auteurs qui ont traduit un livre avec 'PHP' dans le titre
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Les notations peuvent être enchaînées pour accéder via plusieurs tables :
// Trouve les auteurs de livres marqués avec l'étiquette 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Extension des conditions pour JOIN
La méthode joinWhere() étend les conditions qui sont spécifiées lors de la liaison des tables en SQL après le
mot-clé ON.
Supposons que nous voulions trouver les livres traduits par un traducteur spécifique :
// Trouve les livres traduits par le traducteur nommé 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
Dans la condition joinWhere(), nous pouvons utiliser les mêmes constructions que dans la méthode
where() – opérateurs, points d'interrogation, tableaux de valeurs ou expressions SQL.
Pour des requêtes plus complexes avec plusieurs JOIN, nous pouvons définir des alias de tables :
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Notez que tandis que la méthode where() ajoute des conditions à la clause WHERE, la méthode
joinWhere() étend les conditions dans la clause ON lors de la liaison des tables.