Database Explorer
Explorer ofrece una forma intuitiva y eficiente de trabajar con la base de datos. Se encarga automáticamente de las relaciones entre tablas y la optimización de consultas, para que puedas concentrarte en tu aplicación. Funciona inmediatamente sin configuración. Si necesitas control total sobre las consultas SQL, puedes utilizar el acceso SQL.
- Trabajar con datos es natural y fácil de entender.
- Genera consultas SQL optimizadas que cargan solo los datos necesarios.
- Permite un fácil acceso a los datos relacionados sin necesidad de escribir consultas JOIN.
- Funciona instantáneamente sin ninguna configuración o generación de entidades.
Empiezas con Explorer llamando al método table() del objeto Nette\Database\Explorer (los detalles de la
conexión se pueden encontrar en el capítulo Conexión y configuración):
$books = $explorer->table('book'); // 'book' es el nombre de la tabla
El método devuelve un objeto Selection, que representa una consulta SQL.
A este objeto podemos encadenar otros métodos para filtrar y ordenar los resultados. La consulta se construye y ejecuta solo
cuando empezamos a solicitar datos. Por ejemplo, iterando con un bucle foreach. Cada fila está representada por un
objeto ActiveRow:
foreach ($books as $book) {
echo $book->title; // Salida de la columna 'title'
echo $book->author_id; // Salida de la columna 'author_id'
}
Explorer facilita fundamentalmente el trabajo con relaciones entre tablas. El siguiente ejemplo muestra lo fácil que es mostrar datos de tablas relacionadas (libros y sus autores). Ten en cuenta que no necesitamos escribir ninguna consulta JOIN, Nette las crea por nosotros:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Libro: ' . $book->title;
echo 'Autor: ' . $book->author->name; // Crea un JOIN a la tabla 'author'
}
Nette Database Explorer optimiza las consultas para que sean lo más eficientes posible. El ejemplo anterior ejecuta solo dos consultas SELECT, independientemente de si procesamos 10 o 10,000 libros.
Además, Explorer rastrea qué columnas se utilizan en el código y carga solo esas desde la base de datos, ahorrando así rendimiento adicional. Este comportamiento es completamente automático y adaptativo. Si más tarde modificas el código y comienzas a usar columnas adicionales, Explorer ajustará automáticamente las consultas. No necesitas configurar nada, ni pensar qué columnas necesitarás – déjaselo a Nette.
Filtrado y ordenación
La clase Selection proporciona métodos para filtrar y ordenar la selección de datos.
where($condition, ...$params) |
Añade una condición WHERE. Múltiples condiciones se unen con el operador AND |
whereOr(array $conditions) |
Añade un grupo de condiciones WHERE unidas por el operador OR |
wherePrimary($value) |
Añade una condición WHERE por clave primaria |
order($columns, ...$params) |
Establece el orden ORDER BY |
select($columns, ...$params) |
Especifica las columnas que se deben cargar |
limit($limit, $offset = null) |
Limita el número de filas (LIMIT) y opcionalmente establece OFFSET |
page($page, $itemsPerPage, &$total = null) |
Establece la paginación |
group($columns, ...$params) |
Agrupa las filas (GROUP BY) |
having($condition, ...$params) |
Añade una condición HAVING para filtrar filas agrupadas |
Los métodos se pueden encadenar (la llamada interfaz fluida):
$table->where(...)->order(...)->limit(...).
En estos métodos también puedes usar notación especial para acceder a datos de tablas relacionadas.
Escape e identificadores
Los métodos escapan automáticamente los parámetros y entrecomillan los identificadores (nombres de tablas y columnas), previniendo así la inyección SQL. Para un funcionamiento correcto, es necesario seguir algunas reglas:
- Escribe las palabras clave, nombres de funciones, procedimientos, etc., en MAYÚSCULAS.
- Escribe los nombres de columnas y tablas en minúsculas.
- Siempre inserta cadenas a través de parámetros.
where('name = ' . $name); // VULNERABILIDAD CRÍTICA: Inyección SQL
where('name LIKE "%search%"'); // MAL: complica el entrecomillado automático
where('name LIKE ?', '%search%'); // CORRECTO: valor insertado mediante parámetro
where('name like ?', $name); // MAL: genera: `name` `like` ?
where('name LIKE ?', $name); // CORRECTO: genera: `name` LIKE ?
where('LOWER(name) = ?', $value);// CORRECTO: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtra los resultados usando condiciones WHERE. Su punto fuerte es el manejo inteligente de diferentes tipos de valores y la elección automática de operadores SQL.
Uso básico:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Gracias a la detección automática de operadores apropiados, no tenemos que lidiar con varios casos especiales. Nette los resuelve por nosotros:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// También se puede usar un signo de interrogación de marcador de posición sin operador:
$table->where('id ?', 1); // WHERE `id` = 1
El método también maneja correctamente condiciones negativas y arrays vacíos:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- No encontrará nada
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- Encontrará todo
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- Encontrará todo
// $table->where('NOT id ?', $ids); Atención - esta sintaxis no es compatible
También podemos pasar el resultado de otra tabla como parámetro – se creará una subconsulta:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
También podemos pasar las condiciones como un array, cuyos elementos se unirán usando AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
En el array podemos usar pares clave ⇒ valor y Nette elegirá automáticamente los operadores correctos de nuevo:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
En el array podemos combinar expresiones SQL con marcadores de posición de signo de interrogación y múltiples parámetros. Esto es adecuado para condiciones complejas con operadores definidos con precisión:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // Pasamos dos parámetros como un array
]);
Múltiples llamadas a where() unen automáticamente las condiciones usando AND.
whereOr (array $parameters): static
Similar a where(), añade condiciones, pero con la diferencia de que las une usando OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Aquí también podemos usar expresiones más complejas:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Añade una condición para la clave primaria de la tabla:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Si la tabla tiene una clave primaria compuesta (por ejemplo, foo_id, bar_id), la pasamos como
un array:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Especifica el orden en que se devolverán las filas. Podemos ordenar por una o más columnas, en orden descendente o ascendente, o por una expresión personalizada:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Especifica las columnas que deben devolverse de la base de datos. Por defecto, Nette Database Explorer devuelve solo aquellas
columnas que se utilizan realmente en el código. Por lo tanto, usamos el método select() en casos donde necesitamos
devolver expresiones específicas:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Los alias definidos usando AS están entonces disponibles como propiedades del objeto ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // Acceso al alias
}
limit (?int $limit, ?int $offset = null): static
Limita el número de filas devueltas (LIMIT) y opcionalmente permite establecer un offset:
$table->limit(10); // LIMIT 10 (Devuelve las primeras 10 filas)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Para la paginación, es más adecuado usar el método page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Facilita la paginación de resultados. Acepta el número de página (contando desde 1) y el número de elementos por página. Opcionalmente, se puede pasar una referencia a una variable donde se almacenará el número total de páginas:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Total de páginas: $numOfPages";
group (string $columns, …$parameters): static
Agrupa las filas por las columnas especificadas (GROUP BY). Se utiliza generalmente junto con funciones de agregación:
// Calcula el número de productos en cada categoría
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Establece la condición para filtrar filas agrupadas (HAVING). Se puede usar junto con el método group() y
funciones de agregación:
// Encuentra categorías que tienen más de 100 productos
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Lectura de datos
Para leer datos de la base de datos, tenemos varios métodos útiles disponibles:
foreach ($table as $key => $row) |
Itera sobre todas las filas, $key es el valor de la clave primaria, $row es un objeto ActiveRow |
$row = $table->get($key) |
Devuelve una fila por clave primaria |
$row = $table->fetch() |
Devuelve la fila actual y mueve el puntero a la siguiente |
$array = $table->fetchPairs() |
Crea un array asociativo a partir de los resultados |
$array = $table->fetchAll() |
Devuelve todas las filas como un array |
count($table) |
Devuelve el número de filas en el objeto Selection |
El objeto ActiveRow está destinado solo para lectura. Esto significa que no se pueden cambiar los valores de sus propiedades. Esta restricción asegura la consistencia de los datos y previene efectos secundarios inesperados. Los datos se cargan desde la base de datos y cualquier cambio debe realizarse de forma explícita y controlada.
foreach – iteración sobre todas las filas
La forma más fácil de ejecutar una consulta y obtener filas es iterando en un bucle foreach. Ejecuta
automáticamente la consulta SQL.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key es el valor de la clave primaria, $book es ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Ejecuta la consulta SQL y devuelve la fila por clave primaria, o null si no existe.
$book = $explorer->table('book')->get(123); // Devuelve ActiveRow con ID 123 o null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Devuelve una fila y mueve el puntero interno a la siguiente. Si no existen más filas, devuelve null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Devuelve los resultados como un array asociativo. El primer argumento especifica el nombre de la columna que se usará como clave en el array, el segundo argumento especifica el nombre de la columna que se usará como valor:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Si solo especificamos el primer parámetro, el valor será la fila completa, es decir, el objeto ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
En caso de claves duplicadas, se utiliza el valor de la última fila. Al usar null como clave, el array se
indexará numéricamente desde cero (entonces no ocurren colisiones):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternativamente, puedes pasar un callback como parámetro, que devolverá el valor en sí, o un par clave-valor para cada fila.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Primer libro (Jan Novák)', ...]
// El callback también puede devolver un array con un par clave & valor:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Primer libro' => 'Jan Novák', ...]
fetchAll(): array
Devuelve todas las filas como un array asociativo de objetos ActiveRow, donde las claves son los valores de las
claves primarias.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
El método count() sin parámetro devuelve el número de filas en el objeto Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // Alternativa
Atención, count() con un parámetro realiza la función de agregación COUNT en la base de datos,
ver más abajo.
ActiveRow::toArray(): array
Convierte el objeto ActiveRow en un array asociativo, donde las claves son los nombres de las columnas y los
valores son los datos correspondientes.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray será ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Agregación
La clase Selection proporciona métodos para realizar fácilmente funciones de agregación (COUNT, SUM, MIN, MAX,
AVG, etc.).
count($expr) |
Cuenta el número de filas |
min($expr) |
Devuelve el valor mínimo en la columna |
max($expr) |
Devuelve el valor máximo en la columna |
sum($expr) |
Devuelve la suma de los valores en la columna |
aggregation($function) |
Permite ejecutar cualquier función de agregación. Por ejemplo, AVG(), GROUP_CONCAT() |
count (string $expr): int
Ejecuta una consulta SQL con la función COUNT y devuelve el resultado. El método se utiliza para determinar
cuántas filas coinciden con una condición específica:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Atención, count() sin parámetro solo devuelve el número de filas en el objeto
Selection.
min (string $expr) y max(string $expr)
Los métodos min() y max() devuelven el valor mínimo y máximo en la columna o expresión
especificada:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Devuelve la suma de los valores en la columna o expresión especificada:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Permite ejecutar cualquier función de agregación.
// Precio promedio de los productos en la categoría
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// Concatena las etiquetas del producto en una sola cadena
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Si necesitamos agregar resultados que ya provienen de alguna función de agregación y agrupación (por ejemplo,
SUM(valor) sobre filas agrupadas), especificamos la función de agregación que se aplicará a estos resultados
intermedios como segundo argumento:
// Calcula el precio total de los productos en stock para cada categoría y luego suma estos precios.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
En este ejemplo, primero calculamos el precio total de los productos en cada categoría
(SUM(price * stock) AS category_total) y agrupamos los resultados por category_id. Luego usamos
aggregation('SUM(category_total)', 'SUM') para sumar estos subtotales category_total. El segundo
argumento 'SUM' indica que la función SUM debe aplicarse a los resultados intermedios.
Insertar, Actualizar y Eliminar
Nette Database Explorer simplifica la inserción, actualización y eliminación de datos. Todos los métodos mencionados
lanzarán una excepción Nette\Database\DriverException en caso de error.
Selection::insert (iterable $data)
Inserta nuevos registros en la tabla.
Insertar un solo registro:
Pasamos el nuevo registro como un array asociativo o un objeto iterable (por ejemplo, ArrayHash usado en formularios), donde las claves corresponden a los nombres de las columnas en
la tabla.
Si la tabla tiene una clave primaria definida, el método devuelve un objeto ActiveRow, que se recarga desde la
base de datos para reflejar cualquier cambio realizado a nivel de base de datos (disparadores, valores de columna predeterminados,
cálculos de columnas autoincrementales). Esto asegura la consistencia de los datos y el objeto siempre contiene los datos
actuales de la base de datos. Si no tiene una clave primaria única, devuelve los datos pasados en forma de array.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row es una instancia de ActiveRow y contiene los datos completos de la fila insertada,
// incluyendo el ID generado automáticamente y cualquier cambio realizado por disparadores
echo $row->id; // Imprime el ID del usuario recién insertado
echo $row->created_at; // Imprime la hora de creación si está establecida por un disparador
Insertar múltiples registros a la vez:
El método insert() permite insertar múltiples registros usando una sola consulta SQL. En este caso, devuelve el
número de filas insertadas.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows será 2
También se puede pasar un objeto Selection con una selección de datos como parámetro.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Insertar valores especiales:
También podemos pasar archivos, objetos DateTime o literales SQL como valores:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // Convierte al formato de base de datos
'avatar' => fopen('image.jpg', 'rb'), // Inserta el contenido binario del archivo
'uuid' => $explorer::literal('UUID()'), // Llama a la función UUID()
]);
Selection::update (iterable $data): int
Actualiza las filas en la tabla según el filtro especificado. Devuelve el número de filas realmente cambiadas.
Pasamos las columnas a cambiar como un array asociativo o un objeto iterable (por ejemplo, ArrayHash usado en formularios), donde las claves corresponden a los nombres de las columnas en
la tabla:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Para cambiar valores numéricos, podemos usar los operadores += y -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // Incrementa el valor de la columna 'points' en 1
'coins-=' => 1, // Decrementa el valor de la columna 'coins' en 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Elimina filas de la tabla según el filtro especificado. Devuelve el número de filas eliminadas.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Al llamar a update() y delete(), no olvides especificar las filas a
modificar/eliminar usando where(). Si no usas where(), ¡la operación se realizará en toda
la tabla!
ActiveRow::update (iterable $data): bool
Actualiza los datos en la fila de la base de datos representada por el objeto ActiveRow. Acepta un iterable con
los datos a actualizar como parámetro (las claves son los nombres de las columnas). Para cambiar valores numéricos, podemos usar
los operadores += y -=:
Después de realizar la actualización, ActiveRow se recarga automáticamente desde la base de datos para reflejar
cualquier cambio realizado a nivel de base de datos (por ejemplo, disparadores). El método devuelve true solo si los
datos realmente cambiaron.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // Incrementamos el número de vistas
]);
echo $article->views; // Imprime el número actual de vistas
Este método actualiza solo una fila específica en la base de datos. Para la actualización masiva de múltiples filas, usa el método Selection::update().
ActiveRow::delete()
Elimina la fila de la base de datos representada por el objeto ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Elimina el libro con ID 1
Este método elimina solo una fila específica en la base de datos. Para la eliminación masiva de múltiples filas, usa el método Selection::delete().
Relaciones entre tablas
En las bases de datos relacionales, los datos se dividen en múltiples tablas y se interconectan mediante claves foráneas. Nette Database Explorer introduce una forma revolucionaria de trabajar con estas relaciones, sin escribir consultas JOIN y sin necesidad de configurar o generar nada.
Para ilustrar el trabajo con relaciones, usaremos un ejemplo de base de datos de libros (puedes encontrarlo en GitHub). En la base de datos tenemos tablas:
author– escritores y traductores (columnasid,name,web,born)book– libros (columnasid,author_id,translator_id,title,sequel_id)tag– etiquetas (columnasid,name)book_tag– tabla de unión entre libros y etiquetas (columnasbook_id,tag_id)
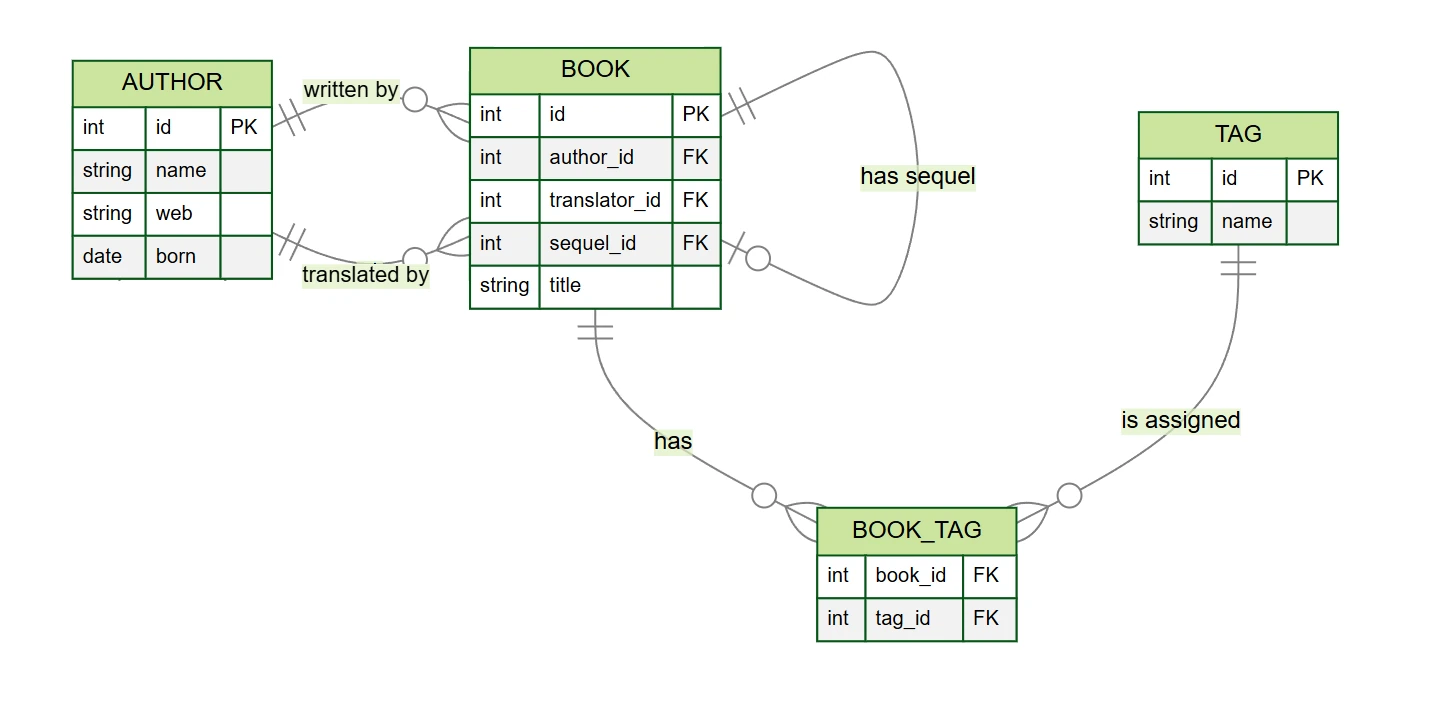
En nuestro ejemplo de base de datos de libros, encontramos varios tipos de relaciones (aunque el modelo está simplificado en comparación con la realidad):
- Uno a muchos (1:N) – cada libro tiene un autor, un autor puede escribir varios libros.
- Cero a muchos (0:N) – un libro puede tener un traductor, un traductor puede traducir varios libros.
- Cero a uno (0:1) – un libro puede tener una secuela.
- Muchos a muchos (M:N) – un libro puede tener varias etiquetas y una etiqueta puede asignarse a varios libros.
En estas relaciones, siempre hay una tabla padre y una tabla hija. Por ejemplo, en la relación entre autor y libro, la tabla
author es la padre y book es la hija – podemos imaginarlo como que un libro siempre “pertenece” a
algún autor. Esto también se refleja en la estructura de la base de datos: la tabla hija book contiene la clave
foránea author_id, que hace referencia a la tabla padre author.
Si necesitamos listar libros incluyendo los nombres de sus autores, tenemos dos opciones. O bien obtenemos los datos con una única consulta SQL usando JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
O cargamos los datos en dos pasos – primero los libros y luego sus autores – y luego los ensamblamos en PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- IDs de los autores de los libros obtenidos
El segundo enfoque es en realidad más eficiente, aunque pueda sorprender. Los datos se cargan solo una vez y pueden utilizarse mejor en la caché. Así es exactamente como funciona Nette Database Explorer: resuelve todo bajo el capó y te ofrece una API elegante:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'título: ' . $book->title;
echo 'escrito por: ' . $book->author->name; // $book->author es un registro de la tabla 'author'
echo 'traducido por: ' . $book->translator?->name;
}
Acceso a la tabla padre
El acceso a la tabla padre es directo. Se trata de relaciones como un libro tiene un autor o un libro puede tener
un traductor. Obtenemos el registro relacionado a través de una propiedad del objeto ActiveRow; su nombre
corresponde al nombre de la columna de clave foránea sin _id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // Encuentra al autor por la columna author_id
echo $book->translator?->name; // Encuentra al traductor por translator_id
Cuando accedemos a la propiedad $book->author, Explorer busca en la tabla book una columna cuyo
nombre contenga la cadena author (es decir, author_id). Según el valor en esta columna, carga el
registro correspondiente de la tabla author y lo devuelve como ActiveRow. De manera similar funciona
$book->translator, que utiliza la columna translator_id. Dado que la columna
translator_id puede contener null, usamos el operador ?-> en el código.
Una ruta alternativa la ofrece el método ref(), que acepta dos argumentos, el nombre de la tabla de destino y el
nombre de la columna de unión, y devuelve una instancia de ActiveRow o null:
echo $book->ref('author', 'author_id')->name; // Relación con el autor
echo $book->ref('author', 'translator_id')->name; // Relación con el traductor
El método ref() es útil si no se puede usar el acceso a través de la propiedad porque la tabla contiene una
columna con el mismo nombre (es decir, author). En otros casos, se recomienda usar el acceso a través de la
propiedad, que es más legible.
Explorer optimiza automáticamente las consultas a la base de datos. Cuando iteramos sobre libros en un bucle y accedemos a sus registros relacionados (autores, traductores), Explorer no genera una consulta para cada libro por separado. En su lugar, ejecuta solo un SELECT para cada tipo de relación, reduciendo significativamente la carga de la base de datos. Por ejemplo:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Este código solo llama a estas tres consultas rápidas a la base de datos:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- IDs de la columna author_id de los libros seleccionados
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- IDs de la columna translator_id de los libros seleccionados
La lógica para encontrar la columna de unión viene dada por la implementación de Conventions. Recomendamos usar DiscoveredConventions, que analiza las claves foráneas y permite trabajar fácilmente con las relaciones existentes entre tablas.
Acceso a la tabla hija
El acceso a la tabla hija funciona en la dirección opuesta. Ahora preguntamos qué libros escribió este autor
o tradujo este traductor. Para este tipo de consulta, usamos el método related(), que devuelve una
Selection con registros relacionados. Veamos un ejemplo:
$author = $explorer->table('author')->get(1);
// Imprime todos los libros del autor
foreach ($author->related('book.author_id') as $book) {
echo "Escrito por: $book->title";
}
// Imprime todos los libros que el autor tradujo
foreach ($author->related('book.translator_id') as $book) {
echo "Traducido por: $book->title";
}
El método related() acepta la descripción de la unión como un argumento con notación de puntos o como dos
argumentos separados:
$author->related('book.translator_id'); // Un argumento
$author->related('book', 'translator_id'); // Dos argumentos
Explorer puede detectar automáticamente la columna de unión correcta basándose en el nombre de la tabla padre. En este caso,
la unión se realiza a través de la columna book.author_id, porque el nombre de la tabla de origen es
author:
$author->related('book'); // Usa book.author_id
Si hubiera múltiples uniones posibles, Explorer lanzaría una excepción AmbiguousReferenceKeyException.
Por supuesto, también podemos usar el método related() al iterar sobre múltiples registros en un bucle, y
Explorer también optimiza automáticamente las consultas en este caso:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' escribió:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Este código genera solo dos consultas SQL rápidas:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- IDs de los autores seleccionados
Relación Muchos a Muchos
Para una relación muchos a muchos (M:N), se requiere una tabla de unión (en nuestro caso book_tag), que contiene
dos columnas con claves foráneas (book_id, tag_id). Cada una de estas columnas hace referencia a la
clave primaria de una de las tablas conectadas. Para obtener los datos relacionados, primero obtenemos los registros de la tabla
de unión usando related('book_tag') y luego continuamos hacia los datos de destino:
$book = $explorer->table('book')->get(1);
// Imprime los nombres de las etiquetas asignadas al libro
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // Imprime el nombre de la etiqueta a través de la tabla de unión
}
$tag = $explorer->table('tag')->get(1);
// O viceversa: imprime los nombres de los libros etiquetados con esta etiqueta
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // Imprime el título del libro
}
Explorer optimiza de nuevo las consultas SQL a una forma eficiente:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- IDs de los libros seleccionados
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- IDs de las etiquetas encontradas en book_tag
Consultas a través de tablas relacionadas
En los métodos where(), select(), order() y group(), podemos usar
notaciones especiales para acceder a columnas de otras tablas. Explorer crea automáticamente los JOIN
necesarios.
La notación de puntos (tabla_padre.columna) se utiliza para la relación 1:N desde la perspectiva de la
tabla hija:
$books = $explorer->table('book');
// Encuentra libros cuyo autor tiene un nombre que empieza por 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Ordena los libros por nombre de autor en orden descendente
$books->order('author.name DESC');
// Imprime el título del libro y el nombre del autor
$books->select('book.title, author.name');
La notación de dos puntos (:tabla_hija.columna) se utiliza para la relación 1:N desde la perspectiva de
la tabla padre:
$authors = $explorer->table('author');
// Encuentra autores que escribieron un libro con 'PHP' en el título
$authors->where(':book.title LIKE ?', '%PHP%');
// Cuenta el número de libros para cada autor
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
En el ejemplo anterior con notación de dos puntos (:book.title), no se especifica la columna de clave foránea.
Explorer detecta automáticamente la columna correcta basándose en el nombre de la tabla padre. En este caso, la unión se
realiza a través de la columna book.author_id, porque el nombre de la tabla de origen es author. Si
hubiera múltiples uniones posibles, Explorer lanzaría una excepción AmbiguousReferenceKeyException.
La columna de unión se puede especificar explícitamente entre paréntesis:
// Encuentra autores que tradujeron un libro con 'PHP' en el título
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Las notaciones se pueden encadenar para acceder a través de múltiples tablas:
// Encuentra autores de libros etiquetados con 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Extensión de condiciones para JOIN
El método joinWhere() extiende las condiciones que se especifican al unir tablas en SQL después de la palabra
clave ON.
Supongamos que queremos encontrar libros traducidos por un traductor específico:
// Encuentra libros traducidos por el traductor llamado 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
En la condición joinWhere(), podemos usar las mismas construcciones que en el método where() –
operadores, marcadores de posición de signo de interrogación, arrays de valores o expresiones SQL.
Para consultas más complejas con múltiples JOIN, podemos definir alias de tabla:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Ten en cuenta que mientras el método where() añade condiciones a la cláusula WHERE, el método
joinWhere() extiende las condiciones en la cláusula ON al unir tablas.