Database Explorer
Explorer пропонує інтуїтивно зрозумілий та ефективний спосіб роботи з базою даних. Він автоматично дбає про зв'язки між таблицями та оптимізацію запитів, тож ви можете зосередитися на своєму додатку. Працює одразу без налаштувань. Якщо вам потрібен повний контроль над SQL-запитами, ви можете скористатися SQL-підходом.
- Робота з даними є природною та легкою для розуміння
- Генерує оптимізовані SQL-запити, які завантажують лише необхідні дані
- Дозволяє легко отримати доступ до пов'язаних даних без необхідності писати JOIN-запити
- Працює одразу без будь-якої конфігурації чи генерації сутностей
З Explorer ви починаєте, викликаючи метод table() об'єкта Nette\Database\Explorer (деталі
підключення див. у розділі Підключення та
конфігурація):
$books = $explorer->table('book'); // 'book' - назва таблиці
Метод повертає об'єкт Selection, який представляє
SQL-запит. До цього об'єкта можна додавати інші методи для фільтрації та
сортування результатів. Запит складається та виконується лише тоді,
коли ми починаємо запитувати дані. Наприклад, проходячи циклом
foreach. Кожен рядок представлений об'єктом ActiveRow:
foreach ($books as $book) {
echo $book->title; // виведення стовпця 'title'
echo $book->author_id; // виведення стовпця 'author_id'
}
Explorer суттєво спрощує роботу зі зв'язками між таблицями. Наступний приклад показує, як легко ми можемо вивести дані з пов'язаних таблиць (книги та їхні автори). Зверніть увагу, що нам не потрібно писати жодних JOIN-запитів, Nette створить їх за нас:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Книга: ' . $book->title;
echo 'Автор: ' . $book->author->name; // створить JOIN на таблицю 'author'
}
Nette Database Explorer оптимізує запити, щоб вони були максимально ефективними. Вищезгаданий приклад виконає лише два SELECT-запити, незалежно від того, чи обробляємо ми 10 чи 10 000 книг.
Крім того, Explorer відстежує, які стовпці використовуються в коді, і завантажує з бази даних лише їх, тим самим заощаджуючи додаткову продуктивність. Ця поведінка повністю автоматична та адаптивна. Якщо ви пізніше зміните код і почнете використовувати інші стовпці, Explorer автоматично змінить запити. Вам не потрібно нічого налаштовувати або думати про те, які стовпці вам знадобляться – залиште це Nette.
Фільтрація та сортування
Клас Selection надає методи для фільтрації та сортування
вибірки даних.
where($condition, ...$params) |
Додає умову WHERE. Кілька умов об'єднуються оператором AND |
whereOr(array $conditions) |
Додає групу умов WHERE, об'єднаних оператором OR |
wherePrimary($value) |
Додає умову WHERE за первинним ключем |
order($columns, ...$params) |
Встановлює сортування ORDER BY |
select($columns, ...$params) |
Вказує стовпці, які потрібно завантажити |
limit($limit, $offset = null) |
Обмежує кількість рядків (LIMIT) та опціонально встановлює OFFSET |
page($page, $itemsPerPage, &$total = null) |
Встановлює пагінацію |
group($columns, ...$params) |
Групує рядки (GROUP BY) |
having($condition, ...$params) |
Додає умову HAVING для фільтрації згрупованих рядків |
Методи можна ланцюжком (так званий fluent interface):
$table->where(...)->order(...)->limit(...).
У цих методах ви також можете використовувати спеціальну нотацію для доступу до даних з пов'язаних таблиць.
Екранування та ідентифікатори
Методи автоматично екранують параметри та беруть у лапки ідентифікатори (назви таблиць та стовпців), тим самим запобігаючи SQL injection. Для правильної роботи необхідно дотримуватися кількох правил:
- Ключові слова, назви функцій, процедур тощо пишіть великими літерами.
- Назви стовпців та таблиць пишіть малими літерами.
- Рядки завжди підставляйте через параметри.
where('name = ' . $name); // КРИТИЧНА ВРАЗЛИВІСТЬ: SQL injection
where('name LIKE "%search%"'); // ПОГАНО: ускладнює автоматичне взяття в лапки
where('name LIKE ?', '%search%'); // ПРАВИЛЬНО: значення підставлене через параметр
where('name like ?', $name); // ПОГАНО: згенерує: `name` `like` ?
where('name LIKE ?', $name); // ПРАВИЛЬНО: згенерує: `name` LIKE ?
where('LOWER(name) = ?', $value);// ПРАВИЛЬНО: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Фільтрує результати за допомогою умов WHERE. Її сильною стороною є інтелектуальна робота з різними типами значень та автоматичний вибір SQL-операторів.
Базове використання:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Завдяки автоматичному визначенню відповідних операторів нам не потрібно розбиратися з різними спеціальними випадками. Nette вирішить їх за нас:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// можна використовувати і знак питання без оператора:
$table->where('id ?', 1); // WHERE `id` = 1
Метод правильно обробляє також заперечні умови та порожні масиви:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- нічого не знайде
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- знайде все
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- знайде все
// $table->where('NOT id ?', $ids); Увага - ця синтаксична конструкція не підтримується
Як параметр ми можемо передати також результат з іншої таблиці – створиться підзапит:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Умови ми можемо передати також як масив, елементи якого об'єднаються за допомогою AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
У масиві ми можемо використовувати пари ключ ⇒ значення, і Nette знову автоматично вибере правильні оператори:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
У масиві ми можемо комбінувати SQL-вирази зі знаками питання та кількома параметрами. Це зручно для складних умов з точно визначеними операторами:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // два параметри передаємо як масив
]);
Багаторазовий виклик where() автоматично об'єднує умови за
допомогою AND.
whereOr (array $parameters): static
Подібно до where(), додає умови, але з тією різницею, що об'єднує їх
за допомогою OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Тут також можна використовувати складніші вирази:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Додає умову для первинного ключа таблиці:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Якщо таблиця має складений первинний ключ (наприклад, foo_id,
bar_id), передаємо його як масив:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Визначає порядок, у якому будуть повернені рядки. Можна сортувати за одним або кількома стовпцями, у спадному чи зростаючому порядку, або за власним виразом:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Вказує стовпці, які потрібно повернути з бази даних. За замовчуванням
Nette Database Explorer повертає лише ті стовпці, які реально використовуються в
коді. Метод select() ми використовуємо у випадках, коли потрібно
повернути специфічні вирази:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Аліаси, визначені за допомогою AS, потім доступні як
властивості об'єкта ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // доступ до аліасу
}
limit (?int $limit, ?int $offset = null): static
Обмежує кількість повернутих рядків (LIMIT) та опціонально дозволяє встановити зсув (offset):
$table->limit(10); // LIMIT 10 (поверне перші 10 рядків)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Для пагінації краще використовувати метод page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Спрощує пагінацію результатів. Приймає номер сторінки (рахується з 1) та кількість елементів на сторінку. Опціонально можна передати посилання на змінну, в яку буде збережено загальну кількість сторінок:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Всього сторінок: $numOfPages";
group (string $columns, …$parameters): static
Групує рядки за вказаними стовпцями (GROUP BY). Зазвичай використовується у поєднанні з агрегатними функціями:
// Рахує кількість продуктів у кожній категорії
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Встановлює умову для фільтрації згрупованих рядків (HAVING). Можна
використовувати у поєднанні з методом group() та агрегатними
функціями:
// Знаходить категорії, які мають більше 100 продуктів
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Читання даних
Для читання даних з бази даних у нас є кілька корисних методів:
foreach ($table as $key => $row) |
Ітерує по всіх рядках, $key – значення первинного ключа,
$row – об'єкт ActiveRow |
$row = $table->get($key) |
Повертає один рядок за первинним ключем |
$row = $table->fetch() |
Повертає поточний рядок і переміщує вказівник на наступний |
$array = $table->fetchPairs() |
Створює асоціативний масив з результатів |
$array = $table->fetchAll() |
Повертає всі рядки як масив |
count($table) |
Повертає кількість рядків в об'єкті Selection |
Об'єкт ActiveRow призначений лише для читання. Це означає, що не можна змінювати значення його властивостей. Це обмеження забезпечує консистенцію даних та запобігає неочікуваним побічним ефектам. Дані завантажуються з бази даних, і будь-яка зміна повинна бути виконана явно та контрольовано.
foreach – ітерація по всіх рядках
Найпростіший спосіб виконати запит і отримати рядки – це ітерація в
циклі foreach. Автоматично запускає SQL-запит.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key - значення первинного ключа, $book - ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Виконує SQL-запит і повертає рядок за первинним ключем, або null,
якщо він не існує.
$book = $explorer->table('book')->get(123); // поверне ActiveRow з ID 123 або null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Повертає рядок і переміщує внутрішній вказівник на наступний. Якщо
більше немає рядків, повертає null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Повертає результати як асоціативний масив. Перший аргумент визначає назву стовпця, який буде використовуватися як ключ у масиві, другий аргумент визначає назву стовпця, який буде використовуватися як значення:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Якщо вказати лише перший параметр, значенням буде весь рядок, тобто
об'єкт ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
У випадку дублювання ключів використовується значення з останнього
рядка. При використанні null як ключа, масив буде індексований
чисельно з нуля (тоді колізій не виникає):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Альтернативно, ви можете вказати як параметр callback, який для кожного рядка повертатиме або саме значення, або пару ключ-значення.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Перша книга (Ян Новак)', ...]
// Callback може також повертати масив з парою ключ & значення:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Перша книга' => 'Ян Новак', ...]
fetchAll(): array
Повертає всі рядки як асоціативний масив об'єктів ActiveRow, де
ключами є значення первинних ключів.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Метод count() без параметра повертає кількість рядків в об'єкті
Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // альтернатива
Увага, count() з параметром виконує агрегатну функцію COUNT у базі
даних, див. нижче.
ActiveRow::toArray(): array
Перетворює об'єкт ActiveRow на асоціативний масив, де ключами є
назви стовпців, а значеннями – відповідні дані.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray буде ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Агрегація
Клас Selection надає методи для легкого виконання агрегатних
функцій (COUNT, SUM, MIN, MAX, AVG тощо).
count($expr) |
Рахує кількість рядків |
min($expr) |
Повертає мінімальне значення у стовпці |
max($expr) |
Повертає максимальне значення у стовпці |
sum($expr) |
Повертає суму значень у стовпці |
aggregation($function) |
Дозволяє виконати будь-яку агрегатну функцію. Напр.
AVG(), GROUP_CONCAT() |
count (string $expr): int
Виконує SQL-запит з функцією COUNT і повертає результат. Метод використовується для визначення, скільки рядків відповідає певній умові:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Увага, count() без параметра лише повертає кількість
рядків в об'єкті Selection.
min (string $expr) a max(string $expr)
Методи min() та max() повертають мінімальне та максимальне
значення у вказаному стовпці або виразі:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Повертає суму значень у вказаному стовпці або виразі:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Дозволяє виконати будь-яку агрегатну функцію.
// середня ціна продуктів у категорії
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// об'єднує теги продукту в один рядок
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Якщо нам потрібно агрегувати результати, які вже самі по собі виникли
з якоїсь агрегатної функції та групування (наприклад,
SUM(значення) за згрупованими рядками), як другий аргумент
вкажемо агрегатну функцію, яка має бути застосована до цих проміжних
результатів:
// Розраховує загальну вартість продуктів на складі для окремих категорій, а потім підсумовує ці ціни разом.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
У цьому прикладі ми спочатку розраховуємо загальну вартість
продуктів у кожній категорії (SUM(price * stock) AS category_total) та групуємо
результати за category_id. Потім використовуємо
aggregation('SUM(category_total)', 'SUM') для підсумовування цих проміжних сум
category_total. Другий аргумент 'SUM' вказує, що до проміжних
результатів має бути застосована функція SUM.
Insert, Update & Delete
Nette Database Explorer спрощує вставку, оновлення та видалення даних. Усі
наведені методи у випадку помилки викидають виняток
Nette\Database\DriverException.
Selection::insert (iterable $data)
Вставляє нові записи до таблиці.
Вставка одного запису:
Новий запис передаємо як асоціативний масив або iterable об'єкт (наприклад, ArrayHash, що використовується у формах), де ключі відповідають назвам стовпців у таблиці.
Якщо таблиця має визначений первинний ключ, метод повертає об'єкт
ActiveRow, який перезавантажується з бази даних, щоб врахувати
можливі зміни, внесені на рівні бази даних (тригери, значення за
замовчуванням стовпців, обчислення auto-increment стовпців). Це забезпечує
консистенцію даних, і об'єкт завжди містить актуальні дані з бази
даних. Якщо однозначного первинного ключа немає, повертає передані
дані у вигляді масиву.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row є екземпляром ActiveRow і містить повні дані вставленого рядка,
// включно з автоматично згенерованим ID та можливими змінами, внесеними тригерами
echo $row->id; // Виведе ID новоствореного користувача
echo $row->created_at; // Виведе час створення, якщо встановлено тригером
Вставка кількох записів одночасно:
Метод insert() дозволяє вставити кілька записів за допомогою
одного SQL-запиту. У цьому випадку повертає кількість вставлених
рядків.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows буде 2
Як параметр можна також передати об'єкт Selection з
вибіркою даних.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Вставка спеціальних значень:
Як значення ми можемо передавати також файли, об'єкти DateTime або SQL-літерали:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // перетворює на формат бази даних
'avatar' => fopen('image.jpg', 'rb'), // вставляє бінарний вміст файлу
'uuid' => $explorer::literal('UUID()'), // викликає функцію UUID()
]);
Selection::update (iterable $data): int
Оновлює рядки в таблиці відповідно до вказаного фільтра. Повертає кількість фактично змінених рядків.
Змінювані стовпці передаємо як асоціативний масив або iterable об'єкт (наприклад, ArrayHash, що використовується у формах), де ключі відповідають назвам стовпців у таблиці:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Для зміни числових значень можна використовувати оператори +=
та -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // збільшить значення стовпця 'points' на 1
'coins-=' => 1, // зменшить значення стовпця 'coins' на 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Видаляє рядки з таблиці відповідно до вказаного фільтра. Повертає кількість видалених рядків.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
При виклику update() та delete() не забудьте за
допомогою where() вказати рядки, які потрібно змінити/видалити.
Якщо where() не використовувати, операція буде виконана над усією
таблицею!
ActiveRow::update (iterable $data): bool
Оновлює дані в рядку бази даних, представленому об'єктом ActiveRow.
Як параметр приймає iterable з даними, які потрібно оновити (ключі – назви
стовпців). Для зміни числових значень можна використовувати оператори
+= та -=:
Після виконання оновлення ActiveRow автоматично
перезавантажується з бази даних, щоб врахувати можливі зміни, внесені
на рівні бази даних (наприклад, тригери). Метод повертає true лише якщо
відбулася фактична зміна даних.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // збільшимо кількість переглядів
]);
echo $article->views; // Виведе поточну кількість переглядів
Цей метод оновлює лише один конкретний рядок у базі даних. Для масового оновлення кількох рядків використовуйте метод Selection::update().
ActiveRow::delete()
Видаляє рядок з бази даних, який представлений об'єктом
ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Видалить книгу з ID 1
Цей метод видаляє лише один конкретний рядок у базі даних. Для масового видалення кількох рядків використовуйте метод Selection::delete().
Зв'язки між таблицями
У реляційних базах даних дані розділені на кілька таблиць і взаємопов'язані за допомогою зовнішніх ключів. Nette Database Explorer пропонує революційний спосіб роботи з цими зв'язками – без написання JOIN-запитів та необхідності щось конфігурувати чи генерувати.
Для ілюстрації роботи зі зв'язками використаємо приклад бази даних книг (знайдете його на GitHub). У базі даних маємо таблиці:
author– письменники та перекладачі (стовпціid,name,web,born)book– книги (стовпціid,author_id,translator_id,title,sequel_id)tag– теги (стовпціid,name)book_tag– таблиця зв'язку між книгами та тегами (стовпціbook_id,tag_id)
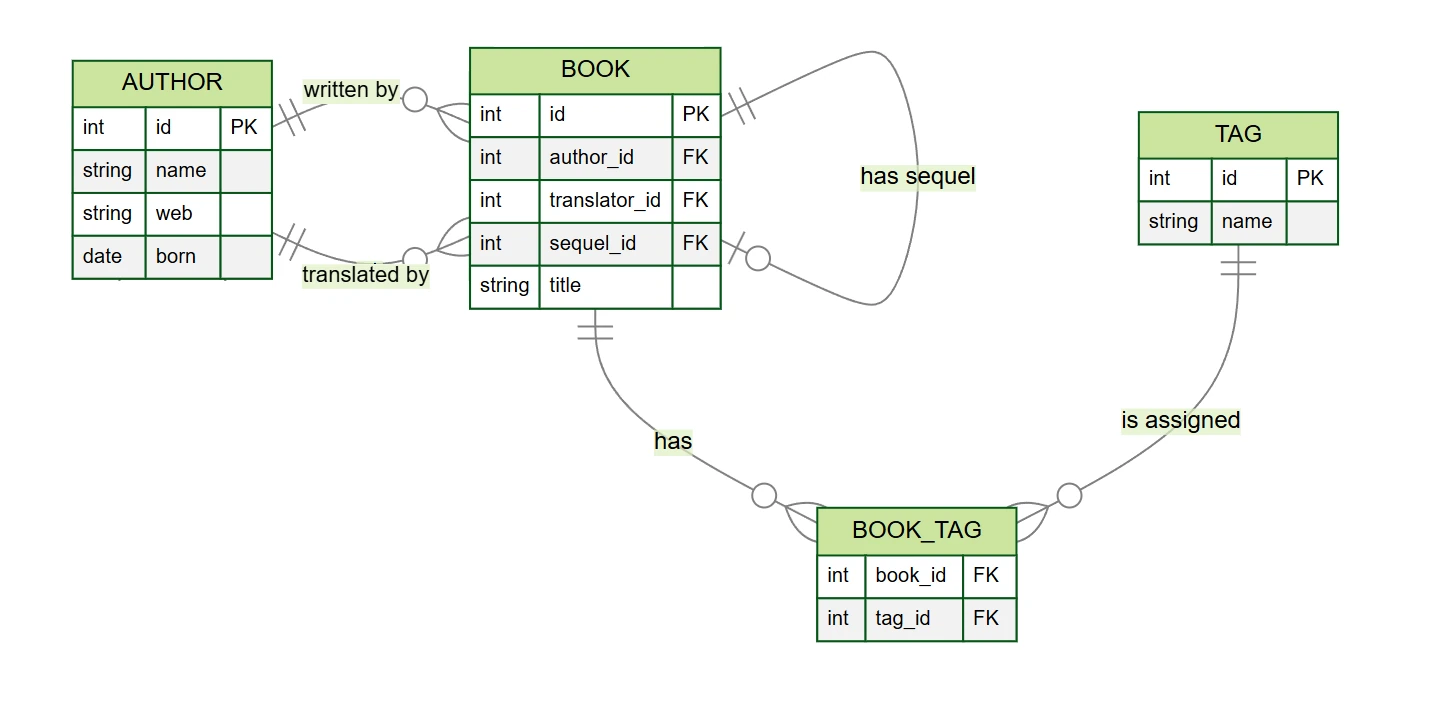
У нашому прикладі бази даних книг знайдемо кілька типів зв'язків (хоча модель спрощена порівняно з реальністю):
- One-to-many 1:N – кожна книга має одного автора, автор може написати кілька книг
- Zero-to-many 0:N – книга може мати перекладача, перекладач може перекласти кілька книг
- Zero-to-one 0:1 – книга може мати наступну частину
- Many-to-many M:N – книга може мати кілька тегів, а тег може бути присвоєний кільком книгам
У цих зв'язках завжди існує батьківська та дочірня таблиця.
Наприклад, у зв'язку між автором та книгою таблиця author є
батьківською, а book – дочірньою. Ми можемо уявити це так, що
книга завжди “належить” якомусь автору. Це проявляється і в структурі
бази даних: дочірня таблиця book містить зовнішній ключ
author_id, який посилається на батьківську таблицю author.
Якщо нам потрібно вивести книги разом з іменами їхніх авторів, у нас є два варіанти. Або отримати дані одним SQL-запитом за допомогою JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Або завантажити дані у два кроки – спочатку книги, а потім їхніх авторів – і потім зібрати їх у PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- id авторів отриманих книг
Другий підхід насправді ефективніший, хоча це може здатися дивним. Дані завантажуються лише один раз і можуть бути краще використані в кеші. Саме таким чином працює Nette Database Explorer – все вирішує під капотом і пропонує вам елегантний API:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'title: ' . $book->title;
echo 'written by: ' . $book->author->name; // $book->author - це запис з таблиці 'author'
echo 'translated by: ' . $book->translator?->name;
}
Доступ до батьківської таблиці
Доступ до батьківської таблиці є прямолінійним. Йдеться про зв'язки
типу книга має автора або книга може мати перекладача.
Пов'язаний запис отримуємо через властивість об'єкта ActiveRow – її назва
відповідає назві стовпця із зовнішнім ключем без id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // знайде автора за стовпцем author_id
echo $book->translator?->name; // знайде перекладача за translator_id
Коли ми звертаємося до властивості $book->author, Explorer у таблиці
book шукає стовпець, назва якого містить рядок author (тобто
author_id). За значенням у цьому стовпці він завантажує відповідний
запис з таблиці author і повертає його як ActiveRow. Подібно
працює і $book->translator, який використовує стовпець translator_id.
Оскільки стовпець translator_id може містити null, ми
використовуємо в коді оператор ?->.
Альтернативний шлях пропонує метод ref(), який приймає два
аргументи: назву цільової таблиці та назву сполучного стовпця, і
повертає екземпляр ActiveRow або null:
echo $book->ref('author', 'author_id')->name; // зв'язок з автором
echo $book->ref('author', 'translator_id')->name; // зв'язок з перекладачем
Метод ref() корисний, якщо не можна використати доступ через
властивість, оскільки таблиця містить стовпець з такою ж назвою (тобто
author). В інших випадках рекомендується використовувати доступ
через властивість, який є більш читабельним.
Explorer автоматично оптимізує запити до бази даних. Коли ми проходимо книги в циклі та звертаємося до їхніх пов'язаних записів (авторів, перекладачів), Explorer не генерує запит для кожної книги окремо. Замість цього він виконує лише один SELECT для кожного типу зв'язку, тим самим значно знижуючи навантаження на базу даних. Наприклад:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Цей код викличе лише ці три блискавичні запити до бази даних:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id зі стовпця author_id вибраних книг
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id зі стовпця translator_id вибраних книг
Логіка пошуку сполучного стовпця визначається реалізацією Conventions. Рекомендуємо використовувати DiscoveredConventions, які аналізують зовнішні ключі та дозволяють легко працювати з існуючими зв'язками між таблицями.
Доступ до дочірньої таблиці
Доступ до дочірньої таблиці працює у зворотному напрямку. Тепер ми
запитуємо які книги написав цей автор або переклав цей
перекладач. Для цього типу запиту ми використовуємо метод
related(), який повертає Selection з пов'язаними записами.
Розглянемо приклад:
$author = $explorer->table('author')->get(1);
// Виведе всі книги автора
foreach ($author->related('book.author_id') as $book) {
echo "Написав: $book->title";
}
// Виведе всі книги, які автор переклав
foreach ($author->related('book.translator_id') as $book) {
echo "Переклав: $book->title";
}
Метод related() приймає опис з'єднання як один аргумент з точковою
нотацією або як два окремі аргументи:
$author->related('book.translator_id'); // один аргумент
$author->related('book', 'translator_id'); // два аргументи
Explorer може автоматично визначити правильний сполучний стовпець на
основі назви батьківської таблиці. У цьому випадку з'єднання
відбувається через стовпець book.author_id, оскільки назва вихідної
таблиці – author:
$author->related('book'); // використовує book.author_id
Якщо існує кілька можливих з'єднань, Explorer викине виняток AmbiguousReferenceKeyException.
Метод related() можна, звичайно, використовувати і при проходженні
кількох записів у циклі, і Explorer і в цьому випадку автоматично оптимізує
запити:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' написав:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Цей код згенерує лише два блискавичні SQL-запити:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id вибраних авторів
Зв'язок Many-to-many
Для зв'язку many-to-many (M:N) необхідна наявність таблиці зв'язку (у нашому
випадку book_tag), яка містить два стовпці із зовнішніми ключами
(book_id, tag_id). Кожен з цих стовпців посилається на первинний
ключ однієї з пов'язуваних таблиць. Для отримання пов'язаних даних
спочатку отримуємо записи з таблиці зв'язку за допомогою
related('book_tag'), а далі переходимо до цільових даних:
$book = $explorer->table('book')->get(1);
// виведе назви тегів, присвоєних книзі
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // виведе назву тегу через таблицю зв'язку
}
$tag = $explorer->table('tag')->get(1);
// або навпаки: виведе назви книг, позначених цим тегом
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // виведе назву книги
}
Explorer знову оптимізує SQL-запити до ефективної форми:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id вибраних книг
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id тегів, знайдених у book_tag
Запити через пов'язані таблиці
У методах where(), select(), order() та group() ми можемо
використовувати спеціальні нотації для доступу до стовпців з інших
таблиць. Explorer автоматично створить необхідні JOIN-и.
Точкова нотація (батьківська_таблиця.стовпець)
використовується для зв'язку 1:N з точки зору дочірньої таблиці:
$books = $explorer->table('book');
// Знаходить книги, автор яких має ім'я, що починається на 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Сортує книги за іменем автора за спаданням
$books->order('author.name DESC');
// Виводить назву книги та ім'я автора
$books->select('book.title, author.name');
Двокрапкова нотація (:дочірня_таблиця.стовпець)
використовується для зв'язку 1:N з точки зору батьківської таблиці:
$authors = $explorer->table('author');
// Знаходить авторів, які написали книгу з 'PHP' у назві
$authors->where(':book.title LIKE ?', '%PHP%');
// Рахує кількість книг для кожного автора
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
У вищезгаданому прикладі з двокрапковою нотацією (:book.title) не
вказано стовпець із зовнішнім ключем. Explorer автоматично визначає
правильний стовпець на основі назви батьківської таблиці. У цьому
випадку з'єднання відбувається через стовпець book.author_id,
оскільки назва вихідної таблиці – author. Якщо існує кілька
можливих з'єднань, Explorer викине виняток AmbiguousReferenceKeyException.
Сполучний стовпець можна явно вказати в дужках:
// Знаходить авторів, які переклали книгу з 'PHP' у назві
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Нотації можна ланцюжком для доступу через кілька таблиць:
// Знаходить авторів книг, позначених тегом 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Розширення умов для JOIN
Метод joinWhere() розширює умови, які вказуються при з'єднанні
таблиць у SQL за ключовим словом ON.
Припустимо, ми хочемо знайти книги, перекладені конкретним перекладачем:
// Знаходить книги, перекладені перекладачем на ім'я 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
В умові joinWhere() ми можемо використовувати ті ж конструкції, що й
у методі where() – оператори, знаки питання, масиви значень або
SQL-вирази.
Для складніших запитів з кількома JOIN-ами ми можемо визначити аліаси таблиць:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Зверніть увагу, що тоді як метод where() додає умови до клаузули
WHERE, метод joinWhere() розширює умови в клаузулі ON при
з'єднанні таблиць.