Database Explorer
O Explorer oferece uma forma intuitiva e eficiente de trabalhar com o banco de dados. Ele trata automaticamente das relações entre tabelas e da otimização de consultas, para que você possa se concentrar na sua aplicação. Funciona imediatamente sem configuração. Se precisar de controle total sobre as consultas SQL, pode utilizar o acesso SQL.
- O trabalho com dados é natural e fácil de entender
- Gera consultas SQL otimizadas que carregam apenas os dados necessários
- Permite acesso fácil a dados relacionados sem a necessidade de escrever consultas JOIN
- Funciona imediatamente sem qualquer configuração ou geração de entidades
Começa-se com o Explorer chamando o método table() do objeto Nette\Database\Explorer (detalhes sobre a conexão
podem ser encontrados no capítulo Conexão e
configuração):
$books = $explorer->table('book'); // 'book' é o nome da tabela
O método retorna um objeto Selection,
que representa uma consulta SQL. A este objeto, podemos encadear outros métodos para filtrar e ordenar os resultados.
A consulta é construída e executada apenas quando começamos a solicitar os dados, por exemplo, percorrendo um ciclo
foreach. Cada linha é representada por um objeto ActiveRow:
foreach ($books as $book) {
echo $book->title; // exibe a coluna 'title'
echo $book->author_id; // exibe a coluna 'author_id'
}
O Explorer facilita fundamentalmente o trabalho com relações entre tabelas. O exemplo seguinte mostra como podemos facilmente exibir dados de tabelas relacionadas (livros e seus autores). Note que não precisamos escrever nenhuma consulta JOIN, o Nette cria-as por nós:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Livro: ' . $book->title;
echo 'Autor: ' . $book->author->name; // cria JOIN na tabela 'author'
}
O Nette Database Explorer otimiza as consultas para serem o mais eficientes possível. O exemplo acima executa apenas duas consultas SELECT, independentemente de estarmos a processar 10 ou 10 000 livros.
Além disso, o Explorer monitoriza quais colunas são usadas no código e carrega do banco de dados apenas essas, economizando ainda mais desempenho. Este comportamento é totalmente automático e adaptativo. Se modificar o código posteriormente e começar a usar outras colunas, o Explorer ajustará automaticamente as consultas. Não precisa de configurar nada, nem pensar em quais colunas precisará – deixe isso para o Nette.
Filtragem e Ordenação
A classe Selection fornece métodos para filtrar e ordenar a seleção de dados.
where($condition, ...$params) |
Adiciona uma condição WHERE. Múltiplas condições são unidas pelo operador AND |
whereOr(array $conditions) |
Adiciona um grupo de condições WHERE unidas pelo operador OR |
wherePrimary($value) |
Adiciona uma condição WHERE pela chave primária |
order($columns, ...$params) |
Define a ordenação ORDER BY |
select($columns, ...$params) |
Especifica as colunas que devem ser carregadas |
limit($limit, $offset = null) |
Limita o número de linhas (LIMIT) e opcionalmente define OFFSET |
page($page, $itemsPerPage, &$total = null) |
Define a paginação |
group($columns, ...$params) |
Agrupa linhas (GROUP BY) |
having($condition, ...$params) |
Adiciona uma condição HAVING para filtrar linhas agrupadas |
Os métodos podem ser encadeados (a chamada fluent interface):
$table->where(...)->order(...)->limit(...).
Nestes métodos, também pode usar notação especial para aceder a dados de tabelas relacionadas.
Escaping e Identificadores
Os métodos escapam automaticamente os parâmetros e colocam aspas nos identificadores (nomes de tabelas e colunas), prevenindo assim a injeção de SQL. Para o funcionamento correto, é necessário seguir algumas regras:
- Palavras-chave, nomes de funções, procedimentos, etc., escreva em MAIÚSCULAS.
- Nomes de colunas e tabelas escreva em minúsculas.
- Strings sempre insira através de parâmetros.
where('name = ' . $name); // VULNERABILIDADE CRÍTICA: injeção de SQL
where('name LIKE "%search%"'); // ERRADO: complica o quoting automático
where('name LIKE ?', '%search%'); // CORRETO: valor inserido via parâmetro
where('name like ?', $name); // ERRADO: gera: `name` `like` ?
where('name LIKE ?', $name); // CORRETO: gera: `name` LIKE ?
where('LOWER(name) = ?', $value);// CORRETO: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtra os resultados usando condições WHERE. A sua força reside no trabalho inteligente com diferentes tipos de valores e na escolha automática de operadores SQL.
Uso básico:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Graças à deteção automática de operadores apropriados, não precisamos de lidar com vários casos especiais. O Nette resolve-os por nós:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// também é possível usar o placeholder de interrogação sem operador:
$table->where('id ?', 1); // WHERE `id` = 1
O método também processa corretamente condições negativas e arrays vazios:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- não encontra nada
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- encontra tudo
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- encontra tudo
// $table->where('NOT id ?', $ids); Atenção - esta sintaxe não é suportada
Como parâmetro, também podemos passar o resultado de outra tabela – será criada uma subconsulta:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
As condições também podem ser passadas como um array, cujos itens são unidos por AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
No array, podemos usar pares chave ⇒ valor e o Nette escolherá novamente, de forma automática, os operadores corretos:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
No array, podemos combinar expressões SQL com placeholders de interrogação e múltiplos parâmetros. Isto é adequado para condições complexas com operadores definidos com precisão:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // dois parâmetros passados como array
]);
Chamadas múltiplas de where() unem automaticamente as condições com AND.
whereOr (array $parameters): static
Semelhante a where(), adiciona condições, mas com a diferença de que as une usando OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Aqui também podemos usar expressões mais complexas:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Adiciona uma condição para a chave primária da tabela:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Se a tabela tiver uma chave primária composta (por exemplo, foo_id, bar_id), passamo-la como
um array:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Determina a ordem em que as linhas serão retornadas. Podemos ordenar por uma ou mais colunas, em ordem ascendente ou descendente, ou por uma expressão personalizada:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Especifica as colunas que devem ser retornadas do banco de dados. Por padrão, o Nette Database Explorer retorna apenas as
colunas que são realmente usadas no código. O método select() é, portanto, usado nos casos em que precisamos
retornar expressões específicas:
// SELECT *, DATE_FORMAT(`created_at`, ?) AS formatted_date
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Os aliases definidos usando AS ficam então disponíveis como propriedades do objeto ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // acesso ao alias
}
limit (?int $limit, ?int $offset = null): static
Limita o número de linhas retornadas (LIMIT) e opcionalmente permite definir um offset:
$table->limit(10); // LIMIT 10 (retorna as primeiras 10 linhas)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Para paginação, é mais adequado usar o método page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Facilita a paginação dos resultados. Aceita o número da página (contado a partir de 1) e o número de itens por página. Opcionalmente, pode-se passar uma referência a uma variável na qual o número total de páginas será armazenado:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Total de páginas: $numOfPages";
group (string $columns, …$parameters): static
Agrupa linhas de acordo com as colunas especificadas (GROUP BY). É geralmente usado em conjunto com funções de agregação:
// Conta o número de produtos em cada categoria
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Define uma condição para filtrar linhas agrupadas (HAVING). Pode ser usado em conjunto com o método group() e
funções de agregação:
// Encontra categorias que têm mais de 100 produtos
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Leitura de Dados
Para ler dados do banco de dados, temos vários métodos úteis disponíveis:
foreach ($table as $key => $row) |
Itera sobre todas as linhas, $key é o valor da chave primária, $row é o objeto ActiveRow |
$row = $table->get($key) |
Retorna uma única linha pela chave primária |
$row = $table->fetch() |
Retorna a linha atual e move o ponteiro para a próxima |
$array = $table->fetchPairs() |
Cria um array associativo a partir dos resultados |
$array = $table->fetchAll() |
Retorna todas as linhas como um array |
count($table) |
Retorna o número de linhas no objeto Selection |
O objeto ActiveRow destina-se apenas à leitura. Isto significa que não é possível alterar os valores das suas propriedades. Esta restrição garante a consistência dos dados e evita efeitos colaterais inesperados. Os dados são carregados do banco de dados e qualquer alteração deve ser feita explicitamente e de forma controlada.
foreach – Iteração Sobre Todas as Linhas
A forma mais fácil de executar uma consulta e obter linhas é iterando num ciclo foreach. Ele executa
automaticamente a consulta SQL.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key é o valor da chave primária, $book é ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Executa a consulta SQL e retorna a linha pela chave primária, ou null se não existir.
$book = $explorer->table('book')->get(123); // retorna ActiveRow com ID 123 ou null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Retorna uma linha e move o ponteiro interno para a próxima. Se não houver mais linhas, retorna null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Retorna os resultados como um array associativo. O primeiro argumento especifica o nome da coluna que será usada como chave no array, o segundo argumento especifica o nome da coluna que será usada como valor:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Se especificarmos apenas o primeiro parâmetro, o valor será a linha inteira, ou seja, o objeto ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
Em caso de chaves duplicadas, o valor da última linha será usado. Ao usar null como chave, o array será
indexado numericamente a partir de zero (neste caso, não ocorrem colisões):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternativamente, pode fornecer um callback como parâmetro, que retornará para cada linha ou o próprio valor, ou um par chave-valor.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Primeiro livro (Jan Novák)', ...]
// O callback também pode retornar um array com o par chave & valor:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Primeiro livro' => 'Jan Novák', ...]
fetchAll(): array
Retorna todas as linhas como um array associativo de objetos ActiveRow, onde as chaves são os valores das chaves
primárias.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
O método count() sem parâmetro retorna o número de linhas no objeto Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // alternativa
Atenção, count() com parâmetro executa a função de agregação COUNT no banco de dados.
ActiveRow::toArray(): array
Converte o objeto ActiveRow num array associativo, onde as chaves são os nomes das colunas e os valores são os
dados correspondentes.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray será ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Agregação
A classe Selection fornece métodos para executar facilmente funções de agregação (COUNT, SUM, MIN, MAX,
AVG, etc.).
count($expr) |
Conta o número de linhas |
min($expr) |
Retorna o valor mínimo na coluna |
max($expr) |
Retorna o valor máximo na coluna |
sum($expr) |
Retorna a soma dos valores na coluna |
aggregation($function) |
Permite executar qualquer função de agregação. Ex: AVG(), GROUP_CONCAT() |
count (string $expr): int
Executa uma consulta SQL com a função COUNT e retorna o resultado. O método é usado para descobrir quantas linhas correspondem a uma determinada condição:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Atenção, count() sem parâmetro apenas retorna o número de linhas no objeto Selection, veja count().
min (string $expr) e max(string $expr)
Os métodos min() e max() retornam o valor mínimo e máximo na coluna ou expressão
especificada:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Retorna a soma dos valores na coluna ou expressão especificada:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Permite executar qualquer função de agregação.
// preço médio dos produtos na categoria
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// concatena as tags do produto em uma única string
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Se precisarmos agregar resultados que já resultaram de alguma função de agregação e agrupamento (por exemplo,
SUM(valor) sobre linhas agrupadas), como segundo argumento, especificamos a função de agregação que deve ser
aplicada a esses resultados intermediários:
// Calcula o preço total dos produtos em estoque para categorias individuais e, em seguida, soma esses preços.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
Neste exemplo, primeiro calculamos o preço total dos produtos em cada categoria
(SUM(price * stock) AS category_total) e agrupamos os resultados por category_id. Em seguida, usamos
aggregation('SUM(category_total)', 'SUM') para somar esses subtotais category_total. O segundo
argumento 'SUM' diz que a função SUM deve ser aplicada aos resultados intermediários.
Inserir, Atualizar & Excluir
O Nette Database Explorer simplifica a inserção, atualização e exclusão de dados. Todos os métodos listados abaixo
lançarão uma exceção Nette\Database\DriverException em caso de erro.
Selection::insert (iterable $data)
Insere novos registros na tabela.
Inserindo um único registro:
Passamos o novo registro como um array associativo ou objeto iterável (por exemplo, ArrayHash usado em formulários), onde as chaves correspondem aos nomes das colunas na tabela.
Se a tabela tiver uma chave primária definida, o método retorna um objeto ActiveRow, que é recarregado do
banco de dados para refletir quaisquer alterações feitas no nível do banco de dados (gatilhos, valores padrão de colunas,
cálculos de colunas auto-increment). Isso garante a consistência dos dados e o objeto sempre contém os dados atuais do banco
de dados. Se não houver uma chave primária única, ele retorna os dados passados na forma de um array.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row é uma instância de ActiveRow e contém os dados completos da linha inserida,
// incluindo o ID gerado automaticamente e quaisquer alterações feitas por gatilhos
echo $row->id; // Exibe o ID do usuário recém-inserido
echo $row->created_at; // Exibe a hora de criação, se definida por um gatilho
Inserindo múltiplos registros de uma vez:
O método insert() permite inserir vários registros usando uma única consulta SQL. Neste caso, retorna
o número de linhas inseridas.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows será 2
Como parâmetro, também pode ser passado um objeto Selection com uma seleção de dados.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Inserindo valores especiais:
Como valores, também podemos passar arquivos, objetos DateTime ou literais SQL:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // converte para formato de banco de dados
'avatar' => fopen('image.jpg', 'rb'), // insere o conteúdo binário do arquivo
'uuid' => $explorer::literal('UUID()'), // chama a função UUID()
]);
Selection::update (iterable $data): int
Atualiza linhas na tabela de acordo com o filtro especificado. Retorna o número de linhas realmente alteradas.
Passamos as colunas a serem alteradas como um array associativo ou objeto iterável (por exemplo, ArrayHash usado em formulários), onde as chaves correspondem aos nomes das colunas na tabela:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Para alterar valores numéricos, podemos usar os operadores += e -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // aumenta o valor da coluna 'points' em 1
'coins-=' => 1, // diminui o valor da coluna 'coins' em 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Exclui linhas da tabela de acordo com o filtro especificado. Retorna o número de linhas excluídas.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Ao chamar update() e delete(), não se esqueça de especificar as linhas a serem
modificadas/excluídas usando where(). Se where() não for usado, a operação será realizada em toda a
tabela!
ActiveRow::update (iterable $data): bool
Atualiza os dados na linha do banco de dados representada pelo objeto ActiveRow. Como parâmetro, aceita um
iterável com os dados a serem atualizados (as chaves são os nomes das colunas). Para alterar valores numéricos, podemos usar os
operadores += e -=:
Após a execução da atualização, o ActiveRow é automaticamente recarregado do banco de dados para refletir
quaisquer alterações feitas no nível do banco de dados (por exemplo, gatilhos). O método retorna true apenas se houve uma
alteração real nos dados.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // aumentamos o número de visualizações
]);
echo $article->views; // Exibe o número atual de visualizações
Este método atualiza apenas uma linha específica no banco de dados. Para atualização em massa de várias linhas, use o método Selection::update().
ActiveRow::delete()
Exclui a linha do banco de dados representada pelo objeto ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Exclui o livro com ID 1
Este método exclui apenas uma linha específica no banco de dados. Para exclusão em massa de várias linhas, use o método Selection::delete().
Relações entre tabelas
Em bancos de dados relacionais, os dados são divididos em várias tabelas e interligados por chaves estrangeiras. O Nette Database Explorer traz uma maneira revolucionária de trabalhar com essas relações – sem escrever consultas JOIN e sem a necessidade de configurar ou gerar nada.
Para ilustrar o trabalho com relações, usaremos o exemplo de um banco de dados de livros (você pode encontrá-lo no GitHub). No banco de dados, temos as tabelas:
author– escritores e tradutores (colunasid,name,web,born)book– livros (colunasid,author_id,translator_id,title,sequel_id)tag– tags (colunasid,name)book_tag– tabela de ligação entre livros e tags (colunasbook_id,tag_id)
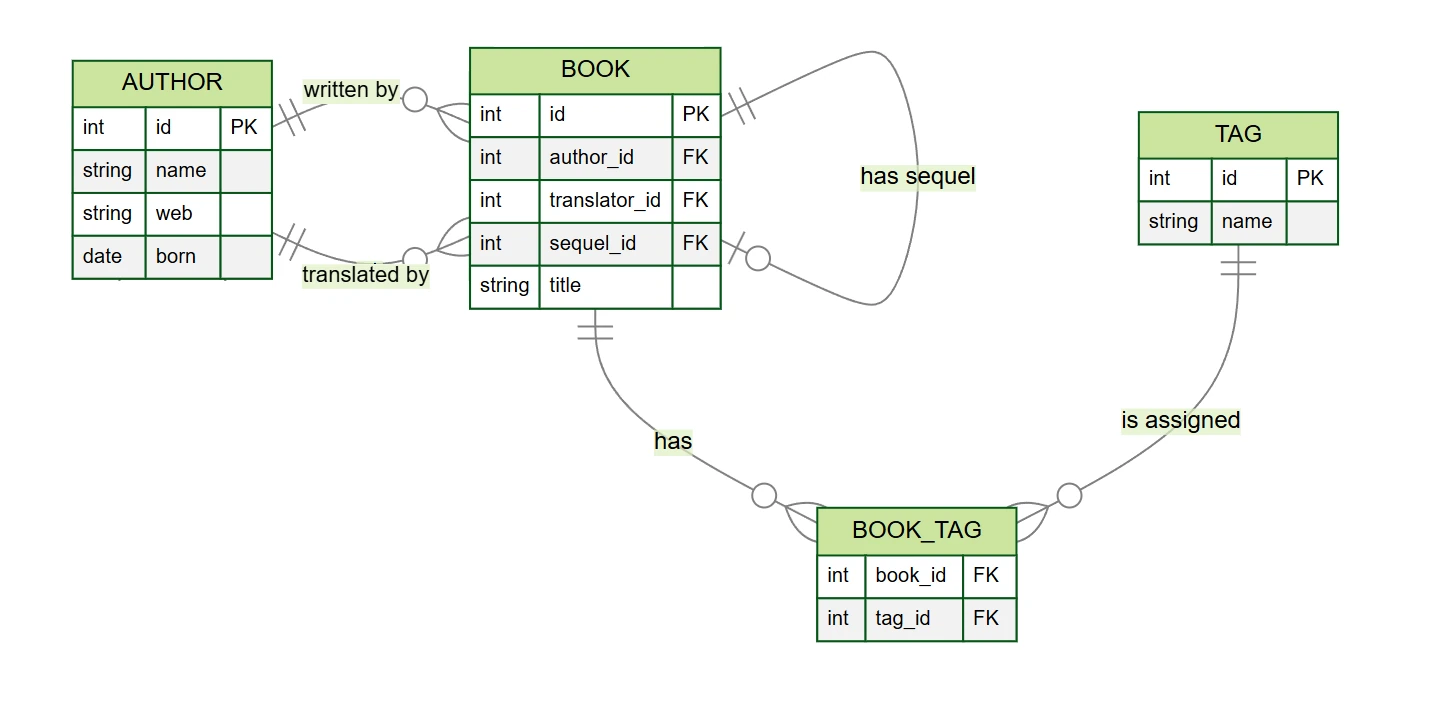
Em nosso exemplo de banco de dados de livros, encontramos vários tipos de relacionamentos (embora o modelo seja simplificado em comparação com a realidade):
- Um-para-muitos 1:N – cada livro tem um autor, um autor pode escrever vários livros
- Zero-para-muitos 0:N – um livro pode ter um tradutor, um tradutor pode traduzir vários livros
- Zero-para-um 0:1 – um livro pode ter uma sequência
- Muitos-para-muitos M:N – um livro pode ter várias tags e uma tag pode ser atribuída a vários livros
Nesses relacionamentos, sempre existe uma tabela pai e uma tabela filho. Por exemplo, no relacionamento entre autor e livro, a
tabela author é a pai e book é a filho – podemos imaginar que o livro sempre “pertence” a
algum autor. Isso também se reflete na estrutura do banco de dados: a tabela filho book contém a chave estrangeira
author_id, que referencia a tabela pai author.
Se precisarmos listar os livros incluindo os nomes de seus autores, temos duas opções. Ou obtemos os dados com uma única consulta SQL usando JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Ou carregamos os dados em duas etapas – primeiro os livros e depois seus autores – e depois os montamos em PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- ids dos autores dos livros obtidos
A segunda abordagem é, na verdade, mais eficiente, embora possa ser surpreendente. Os dados são carregados apenas uma vez e podem ser melhor utilizados no cache. É precisamente desta forma que o Nette Database Explorer funciona – ele resolve tudo nos bastidores e oferece uma API elegante:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'título: ' . $book->title;
echo 'escrito por: ' . $book->author->name; // $book->author é o registro da tabela 'author'
echo 'traduzido por: ' . $book->translator?->name;
}
Acesso à tabela pai
O acesso à tabela pai é direto. Trata-se de relacionamentos como livro tem um autor ou livro pode ter um
tradutor. Obtemos o registro relacionado através da propriedade do objeto ActiveRow – seu nome corresponde ao nome da
coluna com a chave estrangeira sem _id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // encontra o autor pela coluna author_id
echo $book->translator?->name; // encontra o tradutor pela coluna translator_id
Quando acessamos a propriedade $book->author, o Explorer procura na tabela book por uma coluna
cujo nome contenha a string author (ou seja, author_id). Com base no valor nesta coluna, ele carrega
o registro correspondente da tabela author e o retorna como ActiveRow. Da mesma forma funciona
$book->translator, que usa a coluna translator_id. Como a coluna translator_id pode
conter null, usamos o operador ?-> no código.
Um caminho alternativo é oferecido pelo método ref(), que aceita dois argumentos, o nome da tabela de destino e
o nome da coluna de ligação, e retorna uma instância de ActiveRow ou null:
echo $book->ref('author', 'author_id')->name; // relação com o autor
echo $book->ref('author', 'translator_id')->name; // relação com o tradutor
O método ref() é útil se o acesso via propriedade não puder ser usado porque a tabela contém uma coluna com
o mesmo nome (ou seja, author). Nos outros casos, recomenda-se usar o acesso via propriedade, que é mais
legível.
O Explorer otimiza automaticamente as consultas ao banco de dados. Quando percorremos os livros em um loop e acessamos seus registros relacionados (autores, tradutores), o Explorer não gera uma consulta para cada livro separadamente. Em vez disso, ele executa apenas um SELECT para cada tipo de relacionamento, reduzindo significativamente a carga no banco de dados. Por exemplo:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Este código chamará apenas estas três consultas rápidas ao banco de dados:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id da coluna author_id dos livros selecionados
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id da coluna translator_id dos livros selecionados
A lógica para encontrar a coluna de ligação é dada pela implementação de Conventions. Recomendamos o uso de DiscoveredConventions, que analisa as chaves estrangeiras e permite trabalhar facilmente com os relacionamentos existentes entre as tabelas.
Acesso à tabela filho
O acesso à tabela filho funciona na direção oposta. Agora perguntamos quais livros este autor escreveu ou este
tradutor traduziu. Para este tipo de consulta, usamos o método related(), que retorna uma
Selection com os registros relacionados. Vejamos um exemplo:
$author = $explorer->table('author')->get(1);
// Exibe todos os livros do autor
foreach ($author->related('book.author_id') as $book) {
echo "Escreveu: $book->title";
}
// Exibe todos os livros que o autor traduziu
foreach ($author->related('book.translator_id') as $book) {
echo "Traduziu: $book->title";
}
O método related() aceita a descrição da ligação como um único argumento com notação de ponto ou como
dois argumentos separados:
$author->related('book.translator_id'); // um argumento
$author->related('book', 'translator_id'); // dois argumentos
O Explorer pode detectar automaticamente a coluna de ligação correta com base no nome da tabela pai. Neste caso, a ligação
é feita através da coluna book.author_id, porque o nome da tabela de origem é author:
$author->related('book'); // usa book.author_id
Se existissem várias ligações possíveis, o Explorer lançaria uma exceção AmbiguousReferenceKeyException.
O método related() pode, obviamente, ser usado também ao percorrer vários registros em um loop, e o Explorer,
neste caso, também otimiza automaticamente as consultas:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' escreveu:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Este código gerará apenas duas consultas SQL rápidas:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id dos autores selecionados
Relacionamento Muitos-para-Muitos
Para o relacionamento muitos-para-muitos (M:N), é necessária a existência de uma tabela de ligação (no nosso caso
book_tag), que contém duas colunas com chaves estrangeiras (book_id, tag_id). Cada uma
dessas colunas referencia a chave primária de uma das tabelas interligadas. Para obter os dados relacionados, primeiro obtemos os
registros da tabela de ligação usando related('book_tag') e, em seguida, prosseguimos para os dados de destino:
$book = $explorer->table('book')->get(1);
// exibe os nomes das tags atribuídas ao livro
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // exibe o nome da tag através da tabela de ligação
}
$tag = $explorer->table('tag')->get(1);
// ou o inverso: exibe os nomes dos livros marcados com esta tag
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // exibe o nome do livro
}
O Explorer novamente otimiza as consultas SQL para uma forma eficiente:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id dos livros selecionados
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id das tags encontradas em book_tag
Consulta através de tabelas relacionadas
Nos métodos where(), select(), order() e group(), podemos usar notações
especiais para acessar colunas de outras tabelas. O Explorer cria automaticamente os JOINs necessários.
Notação de ponto (tabela_pai.coluna) é usada para o relacionamento 1:N do ponto de vista da
tabela filho:
$books = $explorer->table('book');
// Encontra livros cujo autor tem nome começando com 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Ordena os livros pelo nome do autor em ordem decrescente
$books->order('author.name DESC');
// Exibe o título do livro e o nome do autor
$books->select('book.title, author.name');
Notação de dois pontos (:tabela_filho.coluna) é usada para o relacionamento 1:N do ponto de vista da
tabela pai:
$authors = $explorer->table('author');
// Encontra autores que escreveram um livro com 'PHP' no título
$authors->where(':book.title LIKE ?', '%PHP%');
// Conta o número de livros para cada autor
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
No exemplo acima com notação de dois pontos (:book.title), a coluna com a chave estrangeira não é
especificada. O Explorer detecta automaticamente a coluna correta com base no nome da tabela pai. Neste caso, a ligação é
feita através da coluna book.author_id, porque o nome da tabela de origem é author. Se existissem
várias ligações possíveis, o Explorer lançaria uma exceção AmbiguousReferenceKeyException.
A coluna de ligação pode ser explicitamente especificada entre parênteses:
// Encontra autores que traduziram um livro com 'PHP' no título
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
As notações podem ser encadeadas para acesso através de múltiplas tabelas:
// Encontra autores de livros marcados com a tag 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Extensão de condições para JOIN
O método joinWhere() estende as condições que são especificadas ao ligar tabelas em SQL após a palavra-chave
ON.
Digamos que queremos encontrar livros traduzidos por um tradutor específico:
// Encontra livros traduzidos pelo tradutor chamado 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
Na condição joinWhere(), podemos usar as mesmas construções que no método where() –
operadores, placeholders de interrogação, arrays de valores ou expressões SQL.
Para consultas mais complexas com múltiplos JOINs, podemos definir aliases de tabela:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Observe que, enquanto o método where() adiciona condições à cláusula WHERE, o método
joinWhere() estende as condições na cláusula ON ao ligar tabelas.