Database Explorer
Explorer oferuje intuicyjny i efektywny sposób pracy z bazą danych. Dba automatycznie o relacje między tabelami i optymalizację zapytań, dzięki czemu możesz skupić się na swojej aplikacji. Działa od razu bez konieczności ustawiania. Jeśli potrzebujesz pełnej kontroli nad zapytaniami SQL, możesz wykorzystać dostęp SQL.
- Praca z danymi jest naturalna i łatwa do zrozumienia
- Generuje zoptymalizowane zapytania SQL, które pobierają tylko potrzebne dane
- Umożliwia łatwy dostęp do powiązanych danych bez konieczności pisania zapytań JOIN
- Działa natychmiast bez jakiejkolwiek konfiguracji czy generowania encji
Z Explorerem zaczniesz od wywołania metody table() obiektu Nette\Database\Explorer (szczegóły dotyczące
połączenia znajdziesz w rozdziale Połączenie
i konfiguracja):
$books = $explorer->table('book'); // 'book' to nazwa tabeli
Metoda zwraca obiekt Selection, który
reprezentuje zapytanie SQL. Do tego obiektu możemy dołączać kolejne metody do filtrowania i sortowania wyników. Zapytanie
jest budowane i uruchamiane dopiero w momencie, gdy zaczynamy żądać danych. Na przykład przez przechodzenie pętlą
foreach. Każdy wiersz jest reprezentowany przez obiekt ActiveRow:
foreach ($books as $book) {
echo $book->title; // wypisanie kolumny 'title'
echo $book->author_id; // wypisanie kolumny 'author_id'
}
Explorer zasadniczo ułatwia pracę z relacjami między tabelami. Poniższy przykład pokazuje, jak łatwo możemy wypisać dane z powiązanych tabel (książki i ich autorzy). Zauważ, że nie musimy pisać żadnych zapytań JOIN, Nette stworzy je za nas:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'Książka: ' . $book->title;
echo 'Autor: ' . $book->author->name; // tworzy JOIN do tabeli 'author'
}
Nette Database Explorer optymalizuje zapytania, aby były jak najbardziej efektywne. Powyższy przykład wykona tylko dwa zapytania SELECT, niezależnie od tego, czy przetwarzamy 10 czy 10 000 książek.
Dodatkowo Explorer śledzi, które kolumny są używane w kodzie, i pobiera z bazy danych tylko te, oszczędzając tym samym dodatkową wydajność. To zachowanie jest w pełni automatyczne i adaptacyjne. Jeśli później zmodyfikujesz kod i zaczniesz używać innych kolumn, Explorer automatycznie dostosuje zapytania. Nie musisz niczego ustawiać ani zastanawiać się, które kolumny będziesz potrzebować – zostaw to Nette.
Filtrowanie i sortowanie
Klasa Selection dostarcza metody do filtrowania i sortowania wyboru danych.
where($condition, ...$params) |
Dodaje warunek WHERE. Wiele warunków jest łączonych operatorem AND |
whereOr(array $conditions) |
Dodaje grupę warunków WHERE połączonych operatorem OR |
wherePrimary($value) |
Dodaje warunek WHERE według klucza podstawowego |
order($columns, ...$params) |
Ustawia sortowanie ORDER BY |
select($columns, ...$params) |
Określa kolumny, które mają zostać załadowane |
limit($limit, $offset = null) |
Ogranicza liczbę wierszy (LIMIT) i opcjonalnie ustawia OFFSET |
page($page, $itemsPerPage, &$total = null) |
Ustawia paginację |
group($columns, ...$params) |
Grupuje wiersze (GROUP BY) |
having($condition, ...$params) |
Dodaje warunek HAVING do filtrowania zgrupowanych wierszy |
Metody można łączyć łańcuchowo (tzw. fluent interface):
$table->where(...)->order(...)->limit(...).
W tych metodach możesz również używać specjalnej notacji do dostępu do danych z powiązanych tabel.
Escapowanie i identyfikatory
Metody automatycznie escapują parametry i cytują identyfikatory (nazwy tabel i kolumn), zapobiegając w ten sposób SQL injection. Dla poprawnego działania konieczne jest przestrzeganie kilku zasad:
- Słowa kluczowe, nazwy funkcji, procedur itp. pisz wielkimi literami.
- Nazwy kolumn i tabel pisz małymi literami.
- Ciągi znaków zawsze wstawiaj przez parametry.
where('name = ' . $name); // KRYTYCZNA PODATNOŚĆ: SQL injection
where('name LIKE "%search%"'); // ŹLE: komplikuje automatyczne cytowanie
where('name LIKE ?', '%search%'); // POPRAWNIE: wartość wstawiona przez parametr
where('name like ?', $name); // ŹLE: wygeneruje: `name` `like` ?
where('name LIKE ?', $name); // POPRAWNIE: wygeneruje: `name` LIKE ?
where('LOWER(name) = ?', $value);// POPRAWNIE: LOWER(`name`) = ?
where (string|array $condition, …$parameters): static
Filtruje wyniki za pomocą warunków WHERE. Jej mocną stroną jest inteligentna praca z różnymi typami wartości i automatyczny wybór operatorów SQL.
Podstawowe użycie:
$table->where('id', $value); // WHERE `id` = 123
$table->where('id > ?', $value); // WHERE `id` > 123
$table->where('id = ? OR name = ?', $id, $name); // WHERE `id` = 1 OR `name` = 'Jon Snow'
Dzięki automatycznej detekcji odpowiednich operatorów nie musimy zajmować się różnymi specjalnymi przypadkami. Nette rozwiąże je za nas:
$table->where('id', 1); // WHERE `id` = 1
$table->where('id', null); // WHERE `id` IS NULL
$table->where('id', [1, 2, 3]); // WHERE `id` IN (1, 2, 3)
// można również użyć znaku zapytania bez operatora:
$table->where('id ?', 1); // WHERE `id` = 1
Metoda poprawnie przetwarza również warunki negatywne i puste tablice:
$table->where('id', []); // WHERE `id` IS NULL AND FALSE -- nic nie znajdzie
$table->where('id NOT', []); // WHERE `id` IS NULL OR TRUE -- znajdzie wszystko
$table->where('NOT (id ?)', []); // WHERE NOT (`id` IS NULL AND FALSE) -- znajdzie wszystko
// $table->where('NOT id ?', $ids); Uwaga - ta składnia nie jest obsługiwana
Jako parametr możemy przekazać również wynik z innej tabeli – utworzy się podzapytanie:
// WHERE `id` IN (SELECT `id` FROM `tableName`)
$table->where('id', $explorer->table($tableName));
// WHERE `id` IN (SELECT `col` FROM `tableName`)
$table->where('id', $explorer->table($tableName)->select('col'));
Warunki możemy przekazać również jako tablicę, której elementy zostaną połączone za pomocą AND:
// WHERE (`price_final` < `price_original`) AND (`stock_count` > `min_stock`)
$table->where([
'price_final < price_original',
'stock_count > min_stock',
]);
W tablicy możemy użyć par klucz ⇒ wartość, a Nette ponownie automatycznie wybierze odpowiednie operatory:
// WHERE (`status` = 'active') AND (`id` IN (1, 2, 3))
$table->where([
'status' => 'active',
'id' => [1, 2, 3],
]);
W tablicy możemy łączyć wyrażenia SQL ze znakami zapytania i wieloma parametrami. Jest to odpowiednie dla złożonych warunków z precyzyjnie zdefiniowanymi operatorami:
// WHERE (`age` > 18) AND (ROUND(`score`, 2) > 75.5)
$table->where([
'age > ?' => 18,
'ROUND(score, ?) > ?' => [2, 75.5], // dwa parametry przekazujemy jako tablicę
]);
Wielokrotne wywołanie where() automatycznie łączy warunki za pomocą AND.
whereOr (array $parameters): static
Podobnie jak where() dodaje warunki, ale z tą różnicą, że łączy je za pomocą OR:
// WHERE (`status` = 'active') OR (`deleted` = 1)
$table->whereOr([
'status' => 'active',
'deleted' => true,
]);
Również tutaj możemy użyć bardziej złożonych wyrażeń:
// WHERE (`price` > 1000) OR (`price_with_tax` > 1500)
$table->whereOr([
'price > ?' => 1000,
'price_with_tax > ?' => 1500,
]);
wherePrimary (mixed $key): static
Dodaje warunek dla klucza podstawowego tabeli:
// WHERE `id` = 123
$table->wherePrimary(123);
// WHERE `id` IN (1, 2, 3)
$table->wherePrimary([1, 2, 3]);
Jeśli tabela ma złożony klucz podstawowy (np. foo_id, bar_id), przekażemy go jako tablicę:
// WHERE `foo_id` = 1 AND `bar_id` = 5
$table->wherePrimary(['foo_id' => 1, 'bar_id' => 5])->fetch();
// WHERE (`foo_id`, `bar_id`) IN ((1, 5), (2, 3))
$table->wherePrimary([
['foo_id' => 1, 'bar_id' => 5],
['foo_id' => 2, 'bar_id' => 3],
])->fetchAll();
order (string $columns, …$parameters): static
Określa kolejność, w jakiej będą zwracane wiersze. Możemy sortować według jednej lub więcej kolumn, w porządku malejącym lub rosnącym, lub według własnego wyrażenia:
$table->order('created'); // ORDER BY `created`
$table->order('created DESC'); // ORDER BY `created` DESC
$table->order('priority DESC, created'); // ORDER BY `priority` DESC, `created`
$table->order('status = ? DESC', 'active'); // ORDER BY `status` = 'active' DESC
select (string $columns, …$parameters): static
Określa kolumny, które mają zostać zwrócone z bazy danych. Domyślnie Nette Database Explorer zwraca tylko te kolumny,
które są rzeczywiście używane w kodzie. Metodę select() używamy więc w przypadkach, gdy potrzebujemy zwrócić
specyficzne wyrażenia:
// SELECT *, DATE_FORMAT(`created_at`, "%d.%m.%Y") AS `formatted_date`
$table->select('*, DATE_FORMAT(created_at, ?) AS formatted_date', '%d.%m.%Y');
Aliasy zdefiniowane za pomocą AS są następnie dostępne jako właściwości obiektu ActiveRow:
foreach ($table as $row) {
echo $row->formatted_date; // dostęp do aliasu
}
limit (?int $limit, ?int $offset = null): static
Ogranicza liczbę zwracanych wierszy (LIMIT) i opcjonalnie pozwala ustawić offset:
$table->limit(10); // LIMIT 10 (zwraca pierwsze 10 wierszy)
$table->limit(10, 20); // LIMIT 10 OFFSET 20
Do paginacji bardziej odpowiednie jest użycie metody page().
page (int $page, int $itemsPerPage, &$numOfPages = null): static
Ułatwia paginację wyników. Przyjmuje numer strony (liczony od 1) i liczbę elementów na stronę. Opcjonalnie można przekazać referencję do zmiennej, do której zostanie zapisana całkowita liczba stron:
$numOfPages = null;
$table->page(page: 3, itemsPerPage: 10, $numOfPages);
echo "Łącznie stron: $numOfPages";
group (string $columns, …$parameters): static
Grupuje wiersze według podanych kolumn (GROUP BY). Używa się jej zazwyczaj w połączeniu z funkcjami agregującymi:
// Oblicza liczbę produktów w każdej kategorii
$table->select('category_id, COUNT(*) AS count')
->group('category_id');
having (string $having, …$parameters): static
Ustawia warunek do filtrowania zgrupowanych wierszy (HAVING). Można ją użyć w połączeniu z metodą group()
i funkcjami agregującymi:
// Znajduje kategorie, które mają więcej niż 100 produktów
$table->select('category_id, COUNT(*) AS count')
->group('category_id')
->having('count > ?', 100);
Odczyt danych
Do odczytu danych z bazy danych mamy do dyspozycji kilka użytecznych metod:
foreach ($table as $key => $row) |
Iteruje po wszystkich wierszach, $key to wartość klucza podstawowego, $row to obiekt
ActiveRow |
$row = $table->get($key) |
Zwraca jeden wiersz według klucza podstawowego |
$row = $table->fetch() |
Zwraca bieżący wiersz i przesuwa wskaźnik na następny |
$array = $table->fetchPairs() |
Tworzy tablicę asocjacyjną z wyników |
$array = $table->fetchAll() |
Zwraca wszystkie wiersze jako tablicę |
count($table) |
Zwraca liczbę wierszy w obiekcie Selection |
Obiekt ActiveRow jest przeznaczony tylko do odczytu. Oznacza to, że nie można zmieniać wartości jego właściwości. To ograniczenie zapewnia spójność danych i zapobiega nieoczekiwanym efektom ubocznym. Dane są ładowane z bazy danych, a jakakolwiek zmiana powinna być przeprowadzona jawnie i kontrolowanie.
foreach – iteracja po wszystkich wierszach
Najprostszy sposób na wykonanie zapytania i uzyskanie wierszy to iteracja w pętli foreach. Automatycznie
uruchamia zapytanie SQL.
$books = $explorer->table('book');
foreach ($books as $key => $book) {
// $key to wartość klucza podstawowego, $book to ActiveRow
echo "$book->title ({$book->author->name})";
}
get ($key): ?ActiveRow
Wykonuje zapytanie SQL i zwraca wiersz według klucza podstawowego, lub null, jeśli nie istnieje.
$book = $explorer->table('book')->get(123); // zwróci ActiveRow o ID 123 lub null
if ($book) {
echo $book->title;
}
fetch(): ?ActiveRow
Zwraca wiersz i przesuwa wewnętrzny wskaźnik na następny. Jeśli nie ma już kolejnych wierszy, zwraca
null.
$books = $explorer->table('book');
while ($book = $books->fetch()) {
$this->processBook($book);
}
fetchPairs (string|int|null $key = null, string|int|null $value = null): array
Zwraca wyniki jako tablicę asocjacyjną. Pierwszy argument określa nazwę kolumny, która zostanie użyta jako klucz w tablicy, drugi argument określa nazwę kolumny, która zostanie użyta jako wartość:
$authors = $explorer->table('author')->fetchPairs('id', 'name');
// [1 => 'John Doe', 2 => 'Jane Doe', ...]
Jeśli podamy tylko pierwszy parametr, wartością będzie cały wiersz, czyli obiekt ActiveRow:
$authors = $explorer->table('author')->fetchPairs('id');
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
W przypadku duplikujących się kluczy użyta zostanie wartość z ostatniego wiersza. Przy użyciu null jako
klucza tablica będzie indeksowana numerycznie od zera (wtedy do kolizji nie dochodzi):
$authors = $explorer->table('author')->fetchPairs(null, 'name');
// [0 => 'John Doe', 1 => 'Jane Doe', ...]
fetchPairs (Closure $callback): array
Alternatywnie możesz jako parametr podać callback, który dla każdego wiersza będzie zwracał albo samą wartość, albo parę klucz-wartość.
$titles = $explorer->table('book')
->fetchPairs(fn($row) => "$row->title ({$row->author->name})");
// ['Pierwsza książka (Jan Nowak)', ...]
// Callback może również zwracać tablicę z parą klucz & wartość:
$titles = $explorer->table('book')
->fetchPairs(fn($row) => [$row->title, $row->author->name]);
// ['Pierwsza książka' => 'Jan Nowak', ...]
fetchAll(): array
Zwraca wszystkie wiersze jako tablicę asocjacyjną obiektów ActiveRow, gdzie klucze są wartościami kluczy
podstawowych.
$allBooks = $explorer->table('book')->fetchAll();
// [1 => ActiveRow(id: 1, ...), 2 => ActiveRow(id: 2, ...), ...]
count(): int
Metoda count() bez parametru zwraca liczbę wierszy w obiekcie Selection:
$table->where('category', 1);
$count = $table->count();
$count = count($table); // alternatywa
Uwaga, count() z parametrem wykonuje funkcję agregującą COUNT w bazie danych, zobacz poniżej.
ActiveRow::toArray(): array
Konwertuje obiekt ActiveRow na tablicę asocjacyjną, gdzie klucze są nazwami kolumn, a wartości
odpowiadającymi danymi.
$book = $explorer->table('book')->get(1);
$bookArray = $book->toArray();
// $bookArray będzie ['id' => 1, 'title' => '...', 'author_id' => ..., ...]
Agregacja
Klasa Selection dostarcza metody do łatwego wykonywania funkcji agregujących (COUNT, SUM, MIN, MAX,
AVG itd.).
count($expr) |
Oblicza liczbę wierszy |
min($expr) |
Zwraca minimalną wartość w kolumnie |
max($expr) |
Zwraca maksymalną wartość w kolumnie |
sum($expr) |
Zwraca sumę wartości w kolumnie |
aggregation($function) |
Umożliwia wykonanie dowolnej funkcji agregującej. Np. AVG(), GROUP_CONCAT() |
count (string $expr): int
Wykonuje zapytanie SQL z funkcją COUNT i zwraca wynik. Metoda jest używana do sprawdzenia, ile wierszy odpowiada określonemu warunkowi:
$count = $table->count('*'); // SELECT COUNT(*) FROM `table`
$count = $table->count('DISTINCT column'); // SELECT COUNT(DISTINCT `column`) FROM `table`
Uwaga, count() bez parametru tylko zwraca liczbę wierszy w obiekcie Selection.
min (string $expr) a max(string $expr)
Metody min() i max() zwracają minimalną i maksymalną wartość w określonej kolumnie lub
wyrażeniu:
// SELECT MAX(`price`) FROM `products` WHERE `active` = 1
$maxPrice = $products->where('active', true)
->max('price');
sum (string $expr)
Zwraca sumę wartości w określonej kolumnie lub wyrażeniu:
// SELECT SUM(`price` * `items_in_stock`) FROM `products` WHERE `active` = 1
$totalPrice = $products->where('active', true)
->sum('price * items_in_stock');
aggregation (string $function, ?string $groupFunction = null)
Umożliwia wykonanie dowolnej funkcji agregującej.
// średnia cena produktów w kategorii
$avgPrice = $products->where('category_id', 1)
->aggregation('AVG(price)');
// łączy etykiety produktu w jeden ciąg
$tags = $products->where('id', 1)
->aggregation('GROUP_CONCAT(tag.name) AS tags')
->fetch()
->tags;
Jeśli potrzebujemy agregować wyniki, które już same w sobie powstały z jakiejś funkcji agregującej i grupowania (np.
SUM(wartość) przez zgrupowane wiersze), jako drugi argument podajemy funkcję agregującą, która ma być
zastosowana do tych wyników pośrednich:
// Oblicza całkowitą cenę produktów w magazynie dla poszczególnych kategorii, a następnie sumuje te ceny.
$totalPrice = $products->select('category_id, SUM(price * stock) AS category_total')
->group('category_id')
->aggregation('SUM(category_total)', 'SUM');
W tym przykładzie najpierw obliczamy całkowitą cenę produktów w każdej kategorii
(SUM(price * stock) AS category_total) i grupujemy wyniki według category_id. Następnie używamy
aggregation('SUM(category_total)', 'SUM') do zsumowania tych sum pośrednich category_total. Drugi
argument 'SUM' mówi, że na wyniki pośrednie ma być zastosowana funkcja SUM.
Insert, Update & Delete
Nette Database Explorer upraszcza wstawianie, aktualizację i usuwanie danych. Wszystkie podane metody w przypadku błędu
wyrzucą wyjątek Nette\Database\DriverException.
Selection::insert (iterable $data)
Wstawia nowe rekordy do tabeli.
Wstawianie jednego rekordu:
Nowy rekord przekazujemy jako tablicę asocjacyjną lub obiekt iterable (na przykład ArrayHash używany w formularzach), gdzie klucze odpowiadają nazwom kolumn w tabeli.
Jeśli tabela ma zdefiniowany klucz podstawowy, metoda zwraca obiekt ActiveRow, który jest ponownie ładowany
z bazy danych, aby uwzględnić ewentualne zmiany dokonane na poziomie bazy danych (triggery, wartości domyślne kolumn,
obliczenia kolumn auto-increment). Zapewnia to spójność danych, a obiekt zawsze zawiera aktualne dane z bazy danych. Jeśli
jednoznaczny klucz podstawowy nie istnieje, zwraca przekazane dane w formie tablicy.
$row = $explorer->table('users')->insert([
'name' => 'John Doe',
'email' => 'john.doe@example.com',
]);
// $row jest instancją ActiveRow i zawiera kompletne dane wstawionego wiersza,
// w tym automatycznie generowane ID i ewentualne zmiany dokonane przez triggery
echo $row->id; // Wypisuje ID nowo wstawionego użytkownika
echo $row->created_at; // Wypisuje czas utworzenia, jeśli jest ustawiony przez trigger
Wstawianie wielu rekordów naraz:
Metoda insert() umożliwia wstawienie wielu rekordów za pomocą jednego zapytania SQL. W tym przypadku zwraca
liczbę wstawionych wierszy.
$insertedRows = $explorer->table('users')->insert([
[
'name' => 'John',
'year' => 1994,
],
[
'name' => 'Jack',
'year' => 1995,
],
]);
// INSERT INTO `users` (`name`, `year`) VALUES ('John', 1994), ('Jack', 1995)
// $insertedRows będzie 2
Jako parametr można również przekazać obiekt Selection z wyborem danych.
$newUsers = $explorer->table('potential_users')
->where('approved', 1)
->select('name, email');
$insertedRows = $explorer->table('users')->insert($newUsers);
Wstawianie specjalnych wartości:
Jako wartości możemy przekazywać również pliki, obiekty DateTime lub literały SQL:
$explorer->table('users')->insert([
'name' => 'John',
'created_at' => new DateTime, // konwertuje na format bazy danych
'avatar' => fopen('image.jpg', 'rb'), // wstawia binarną zawartość pliku
'uuid' => $explorer::literal('UUID()'), // wywołuje funkcję UUID()
]);
Selection::update (iterable $data): int
Aktualizuje wiersze w tabeli według podanego filtra. Zwraca liczbę rzeczywiście zmienionych wierszy.
Zmieniane kolumny przekazujemy jako tablicę asocjacyjną lub obiekt iterable (na przykład ArrayHash używany w formularzach), gdzie klucze odpowiadają nazwom kolumn w tabeli:
$affected = $explorer->table('users')
->where('id', 10)
->update([
'name' => 'John Smith',
'year' => 1994,
]);
// UPDATE `users` SET `name` = 'John Smith', `year` = 1994 WHERE `id` = 10
Do zmiany wartości liczbowych możemy użyć operatorów += i -=:
$explorer->table('users')
->where('id', 10)
->update([
'points+=' => 1, // zwiększa wartość kolumny 'points' o 1
'coins-=' => 1, // zmniejsza wartość kolumny 'coins' o 1
]);
// UPDATE `users` SET `points` = `points` + 1, `coins` = `coins` - 1 WHERE `id` = 10
Selection::delete(): int
Usuwa wiersze z tabeli według podanego filtra. Zwraca liczbę usuniętych wierszy.
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE `id` = 10
Podczas wywoływania update() i delete() nie zapomnij za pomocą where()
określić wierszy, które mają zostać zmodyfikowane/usunięte. Jeśli where() nie zostanie użyte, operacja
zostanie przeprowadzona na całej tabeli!
ActiveRow::update (iterable $data): bool
Aktualizuje dane w wierszu bazy danych reprezentowanym przez obiekt ActiveRow. Jako parametr przyjmuje iterable
z danymi, które mają zostać zaktualizowane (klucze są nazwami kolumn). Do zmiany wartości liczbowych możemy użyć
operatorów += i -=:
Po wykonaniu aktualizacji ActiveRow jest automatycznie ponownie ładowany z bazy danych, aby uwzględnić
ewentualne zmiany dokonane na poziomie bazy danych (np. triggery). Metoda zwraca true tylko jeśli doszło do rzeczywistej zmiany
danych.
$article = $explorer->table('article')->get(1);
$article->update([
'views += 1', // zwiększamy liczbę wyświetleń
]);
echo $article->views; // Wypisuje aktualną liczbę wyświetleń
Ta metoda aktualizuje tylko jeden konkretny wiersz w bazie danych. Do masowej aktualizacji wielu wierszy użyj metody Selection::update().
ActiveRow::delete()
Usuwa wiersz z bazy danych, który jest reprezentowany przez obiekt ActiveRow.
$book = $explorer->table('book')->get(1);
$book->delete(); // Usuwa książkę o ID 1
Ta metoda usuwa tylko jeden konkretny wiersz w bazie danych. Do masowego usunięcia wielu wierszy użyj metody Selection::delete().
Relacje między tabelami
W relacyjnych bazach danych dane są podzielone na wiele tabel i wzajemnie powiązane za pomocą kluczy obcych. Nette Database Explorer wprowadza rewolucyjny sposób pracy z tymi relacjami – bez pisania zapytań JOIN i konieczności cokolwiek konfigurować czy generować.
Do ilustracji pracy z relacjami użyjemy przykładu bazy danych książek (znajdziesz go na GitHubie). W bazie danych mamy tabele:
author– pisarze i tłumacze (kolumnyid,name,web,born)book– książki (kolumnyid,author_id,translator_id,title,sequel_id)tag– etykiety (kolumnyid,name)book_tag– tabela łącząca między książkami a etykietami (kolumnybook_id,tag_id)
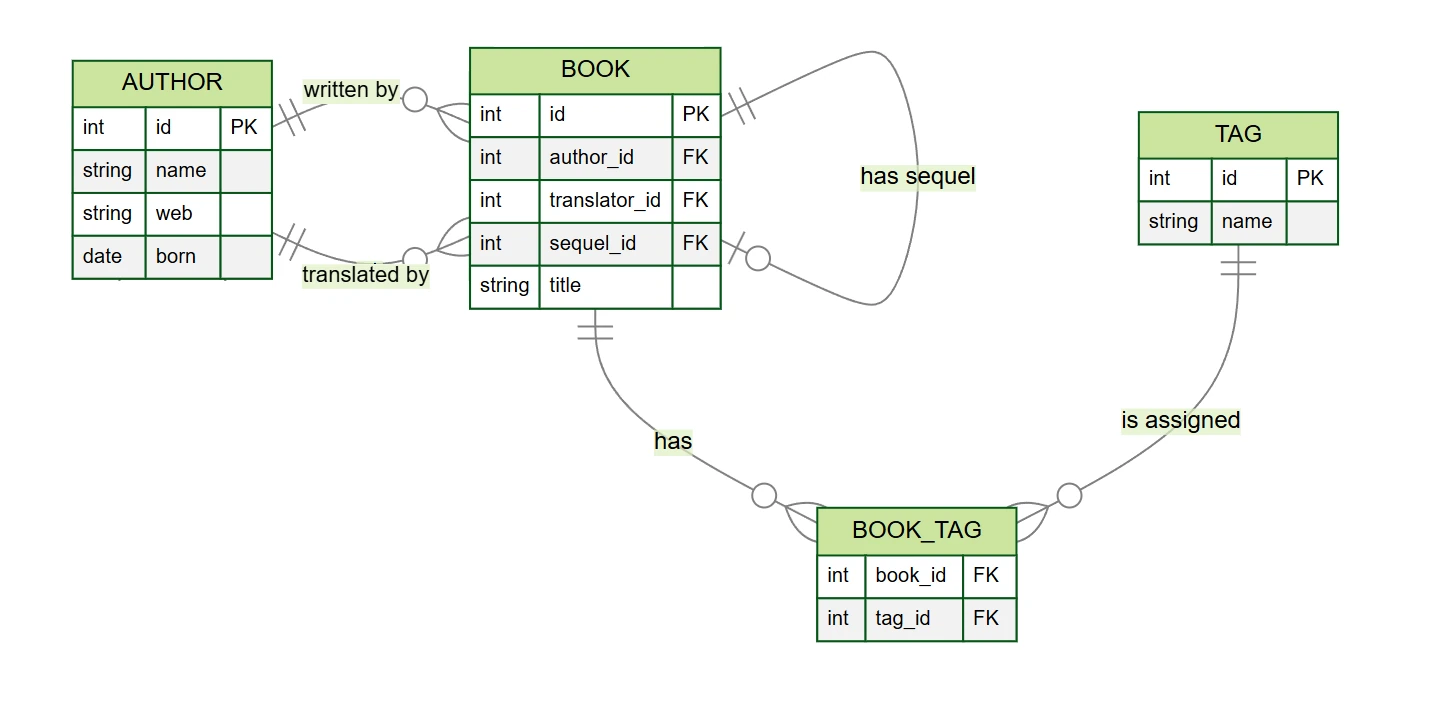
W naszym przykładzie bazy danych książek znajdziemy kilka typów relacji (chociaż model jest uproszczony w porównaniu do rzeczywistości):
- One-to-many 1:N – każda książka ma jednego autora, autor może napisać kilka książek
- Zero-to-many 0:N – książka może mieć tłumacza, tłumacz może przetłumaczyć kilka książek
- Zero-to-one 0:1 – książka może mieć kolejną część
- Many-to-many M:N – książka może mieć kilka tagów, a tag może być przypisany kilku książkom
W tych relacjach zawsze istnieje tabela nadrzędna i podrzędna. Na przykład w relacji między autorem a książką tabela
author jest nadrzędna, a book podrzędna – możemy to sobie wyobrazić tak, że książka zawsze
“należy” do jakiegoś autora. Przejawia się to również w strukturze bazy danych: podrzędna tabela book
zawiera klucz obcy author_id, który odnosi się do nadrzędnej tabeli author.
Jeśli potrzebujemy wypisać książki wraz z imionami ich autorów, mamy dwie możliwości. Albo uzyskamy dane jednym zapytaniem SQL za pomocą JOIN:
SELECT book.*, author.name FROM book LEFT JOIN author ON book.author_id = author.id
Albo załadujemy dane w dwóch krokach – najpierw książki, a potem ich autorów – a następnie złożymy je w PHP:
SELECT * FROM book;
SELECT * FROM author WHERE id IN (1, 2, 3); -- id autorów pobranych książek
Drugie podejście jest w rzeczywistości bardziej efektywne, choć może to być zaskakujące. Dane są ładowane tylko raz i mogą być lepiej wykorzystane w cache. Właśnie w ten sposób działa Nette Database Explorer – wszystko rozwiązuje pod powierzchnią i oferuje Ci eleganckie API:
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'tytuł: ' . $book->title;
echo 'napisane przez: ' . $book->author->name; // $book->author to rekord z tabeli 'author'
echo 'przetłumaczone przez: ' . $book->translator?->name;
}
Dostęp do tabeli nadrzędnej
Dostęp do tabeli nadrzędnej jest prosty. Chodzi o relacje takie jak książka ma autora lub książka może
mieć tłumacza. Powiązany rekord uzyskujemy przez właściwość obiektu ActiveRow – jej nazwa odpowiada nazwie kolumny
z kluczem obcym bez id:
$book = $explorer->table('book')->get(1);
echo $book->author->name; // znajduje autora według kolumny author_id
echo $book->translator?->name; // znajduje tłumacza według translator_id
Gdy uzyskujemy dostęp do właściwości $book->author, Explorer w tabeli book szuka kolumny,
której nazwa zawiera ciąg author (czyli author_id). Według wartości w tej kolumnie ładuje
odpowiedni rekord z tabeli author i zwraca go jako ActiveRow. Podobnie działa
$book->translator, który wykorzystuje kolumnę translator_id. Ponieważ kolumna
translator_id może zawierać null, użyjemy w kodzie operatora ?->.
Alternatywną ścieżkę oferuje metoda ref(), która przyjmuje dwa argumenty, nazwę tabeli docelowej i nazwę
kolumny łączącej, i zwraca instancję ActiveRow lub null:
echo $book->ref('author', 'author_id')->name; // relacja do autora
echo $book->ref('author', 'translator_id')->name; // relacja do tłumacza
Metoda ref() przydaje się, jeśli nie można użyć dostępu przez właściwość, ponieważ tabela zawiera
kolumnę o tej samej nazwie (tj. author). W pozostałych przypadkach zaleca się używanie dostępu przez
właściwość, który jest bardziej czytelny.
Explorer automatycznie optymalizuje zapytania do bazy danych. Kiedy przechodzimy przez książki w pętli i uzyskujemy dostęp do ich powiązanych rekordów (autorów, tłumaczy), Explorer nie generuje zapytania dla każdej książki osobno. Zamiast tego wykonuje tylko jedno zapytanie SELECT dla każdego typu relacji, co znacznie zmniejsza obciążenie bazy danych. Na przykład:
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
echo $book->translator?->name;
}
Ten kod wywoła tylko te trzy błyskawiczne zapytania do bazy danych:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id z kolumny author_id wybranych książek
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id z kolumny translator_id wybranych książek
Logika wyszukiwania kolumny łączącej jest określona przez implementację Conventions. Zalecamy użycie DiscoveredConventions, które analizuje klucze obce i pozwala łatwo pracować z istniejącymi relacjami między tabelami.
Dostęp do tabeli podrzędnej
Dostęp do tabeli podrzędnej działa w przeciwnym kierunku. Teraz pytamy jakie książki napisał ten autor lub
przetłumaczył ten tłumacz. Do tego typu zapytania używamy metody related(), która zwraca
Selection z powiązanymi rekordami. Spójrzmy na przykład:
$author = $explorer->table('author')->get(1);
// Wypisuje wszystkie książki autora
foreach ($author->related('book.author_id') as $book) {
echo "Napisał: $book->title";
}
// Wypisuje wszystkie książki, które autor przetłumaczył
foreach ($author->related('book.translator_id') as $book) {
echo "Przetłumaczył: $book->title";
}
Metoda related() przyjmuje opis połączenia jako jeden argument z notacją kropkową lub jako dwa osobne
argumenty:
$author->related('book.translator_id'); // jeden argument
$author->related('book', 'translator_id'); // dwa argumenty
Explorer potrafi automatycznie wykryć poprawną kolumnę łączącą na podstawie nazwy tabeli nadrzędnej. W tym przypadku
łączy się przez kolumnę book.author_id, ponieważ nazwa tabeli źródłowej to author:
$author->related('book'); // użyje book.author_id
Gdyby istniało więcej możliwych połączeń, Explorer wyrzuci wyjątek AmbiguousReferenceKeyException.
Metodę related() możemy oczywiście użyć również przy przechodzeniu przez wiele rekordów w pętli, a
Explorer również w tym przypadku automatycznie optymalizuje zapytania:
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' napisał:';
foreach ($author->related('book') as $book) {
echo $book->title;
}
}
Ten kod wygeneruje tylko dwa błyskawiczne zapytania SQL:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id wybranych autorów
Relacja Many-to-many
Dla relacji many-to-many (M:N) potrzebna jest istnienie tabeli łączącej (w naszym przypadku book_tag), która
zawiera dwie kolumny z kluczami obcymi (book_id, tag_id). Każda z tych kolumn odnosi się do klucza
podstawowego jednej z łączonych tabel. Aby uzyskać powiązane dane, najpierw uzyskujemy rekordy z tabeli łączącej za
pomocą related('book_tag'), a następnie przechodzimy do danych docelowych:
$book = $explorer->table('book')->get(1);
// wypisuje nazwy tagów przypisanych do książki
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name; // wypisuje nazwę tagu przez tabelę łączącą
}
$tag = $explorer->table('tag')->get(1);
// lub odwrotnie: wypisuje nazwy książek oznaczonych tym tagiem
foreach ($tag->related('book_tag') as $bookTag) {
echo $bookTag->book->title; // wypisuje nazwę książki
}
Explorer ponownie optymalizuje zapytania SQL do efektywnej postaci:
SELECT * FROM `book`;
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 2, ...)); -- id wybranych książek
SELECT * FROM `tag` WHERE (`tag`.`id` IN (1, 2, ...)); -- id tagów znalezionych w book_tag
Zapytania przez powiązane tabele
W metodach where(), select(), order() i group() możemy używać
specjalnych notacji do dostępu do kolumn z innych tabel. Explorer automatycznie utworzy potrzebne JOINy.
Notacja kropkowa (tabela_nadrzędna.kolumna) jest używana dla relacji 1:N z perspektywy tabeli
podrzędnej:
$books = $explorer->table('book');
// Znajduje książki, których autor ma imię zaczynające się na 'Jon'
$books->where('author.name LIKE ?', 'Jon%');
// Sortuje książki według imienia autora malejąco
$books->order('author.name DESC');
// Wypisuje tytuł książki i imię autora
$books->select('book.title, author.name');
Notacja dwukropkowa (:tabela_podrzędna.kolumna) jest używana dla relacji 1:N z perspektywy tabeli
nadrzędnej:
$authors = $explorer->table('author');
// Znajduje autorów, którzy napisali książkę z 'PHP' w tytule
$authors->where(':book.title LIKE ?', '%PHP%');
// Oblicza liczbę książek dla każdego autora
$authors->select('*, COUNT(:book.id) AS book_count')
->group('author.id');
W powyższym przykładzie z notacją dwukropkową (:book.title) nie jest określona kolumna z kluczem obcym.
Explorer automatycznie wykrywa poprawną kolumnę na podstawie nazwy tabeli nadrzędnej. W tym przypadku łączy się przez
kolumnę book.author_id, ponieważ nazwa tabeli źródłowej to author. Gdyby istniało więcej
możliwych połączeń, Explorer wyrzuci wyjątek AmbiguousReferenceKeyException.
Kolumnę łączącą można jawnie podać w nawiasie:
// Znajduje autorów, którzy przetłumaczyli książkę z 'PHP' w tytule
$authors->where(':book(translator_id).title LIKE ?', '%PHP%');
Notacje można łączyć łańcuchowo dla dostępu przez wiele tabel:
// Znajduje autorów książek oznaczonych tagiem 'PHP'
$authors->where(':book:book_tag.tag.name', 'PHP')
->group('author.id');
Rozszerzenie warunków dla JOIN
Metoda joinWhere() rozszerza warunki, które podaje się przy łączeniu tabel w SQL za słowem kluczowym
ON.
Załóżmy, że chcemy znaleźć książki przetłumaczone przez konkretnego tłumacza:
// Znajduje książki przetłumaczone przez tłumacza o imieniu 'David'
$books = $explorer->table('book')
->joinWhere('translator', 'translator.name', 'David');
// LEFT JOIN author translator ON book.translator_id = translator.id AND (translator.name = 'David')
W warunku joinWhere() możemy używać tych samych konstrukcji co w metodzie where() –
operatorów, znaków zapytania, tablic wartości czy wyrażeń SQL.
Dla bardziej złożonych zapytań z wieloma JOINami możemy zdefiniować aliasy tabel:
$tags = $explorer->table('tag')
->joinWhere(':book_tag.book.author', 'book_author.born < ?', 1950)
->alias(':book_tag.book.author', 'book_author');
// LEFT JOIN `book_tag` ON `tag`.`id` = `book_tag`.`tag_id`
// LEFT JOIN `book` ON `book_tag`.`book_id` = `book`.`id`
// LEFT JOIN `author` `book_author` ON `book`.`author_id` = `book_author`.`id`
// AND (`book_author`.`born` < 1950)
Zauważ, że podczas gdy metoda where() dodaje warunki do klauzuli WHERE, metoda
joinWhere() rozszerza warunki w klauzuli ON podczas łączenia tabel.