Database Explorer
Nette Database Explorer (dříve Nette Database Table, NDBT) zásadním způsobem zjednodušuje získávání dat z databáze bez nutnosti psát SQL dotazy.
- pokládá efektivní dotazy
- nepřenáší zbytečná data
- má elegantní syntax
Používání Database Explorer začíná od tabulky a to zavoláním metody table() nad objektem Nette\Database\Explorer. Jak ho nejsnadněji získat
je popsáno tady, pokud však používáme Nette
Database Explorer samostatně, lze jej vytvořit i ručně.
$books = $explorer->table('book'); // jméno tabulky je 'book'
Vrací nám objekt Selection, nad kterým můžeme iterovat a projít tak všechny knihy. Řádky jsou instance ActiveRow a data z nich můžeme přímo číst.
foreach ($books as $book) {
echo $book->title;
echo $book->author_id;
}
Výběr jednoho konkrétního řádku se provádí pomocí metody get(), která vrací přímo instanci
ActiveRow.
$book = $explorer->table('book')->get(2); // vrátí knihu s id 2
echo $book->title;
echo $book->author_id;
Pojďme si vyzkoušet jednoduchý příklad. Potřebujeme z databáze vybrat knihy a jejich autory. To je jednoduchý příklad vazby 1:N. Časté řešení je vybrat data jedním SQL dotazem se spojením tabulek pomocí JOINu. Druhou možností je vybrat data odděleně, jedním dotazem knihy, a poté pro každou knihu vybrat jejího autora (např. pomocí foreach cyklu). To může být optimalizováno do dvou požadavků do databáze, jeden pro knihy a druhý pro autory – a přesně takto to dělá Nette Database Explorer.
V níže uvedených příkladech budeme pracovat s databázovým schématem na obrázku. Jsou v něm vazby OneHasMany (1:N)
(autor knihy author_id a případný překladatel translator_id, který může mít hodnotu
null) a vazba ManyHasMany (M:N) mezi knihou a jejími tagy.
Příklad včetně schématu najdete na GitHubu.
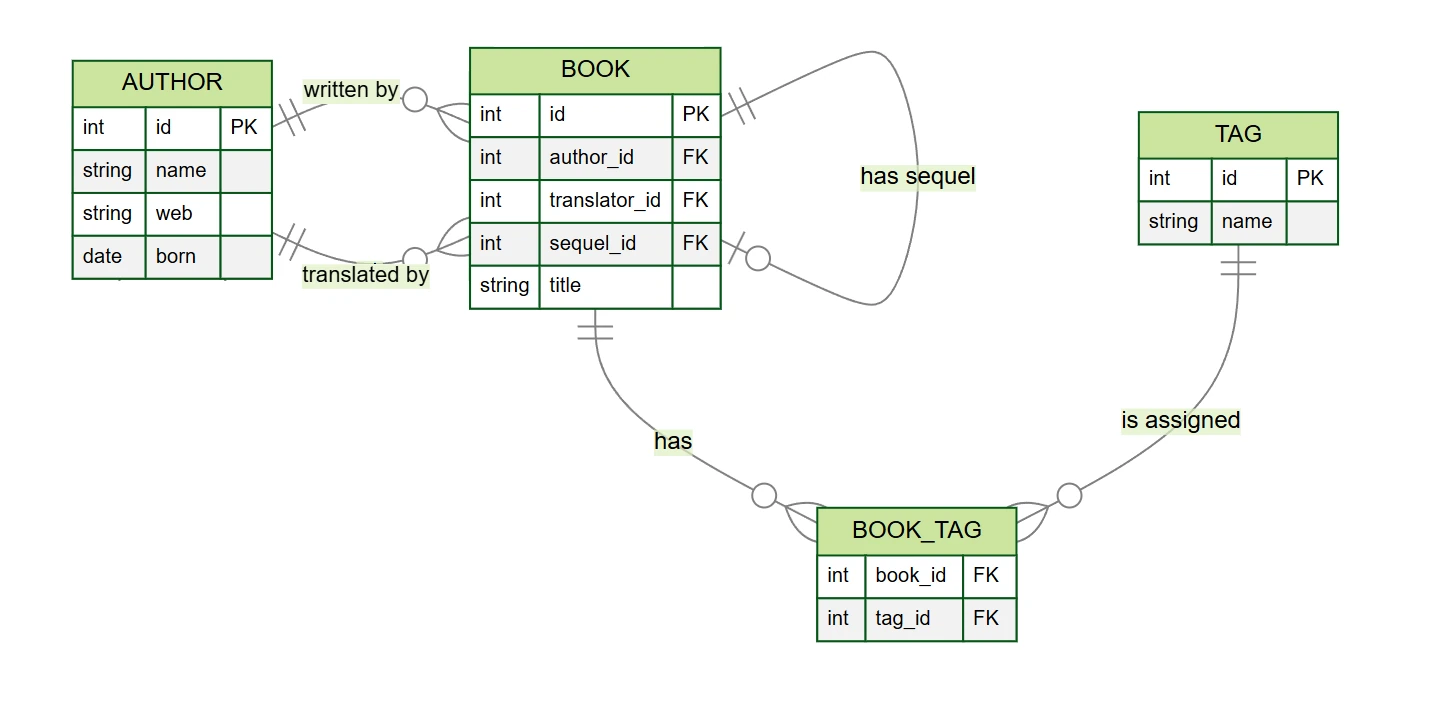
Struktura databáze pro uvedené příklady
Následující kód vypíše jméno autora každé knihy a všechny její tagy. Jak přesně to funguje si povíme za chvíli.
$books = $explorer->table('book');
foreach ($books as $book) {
echo 'title: ' . $book->title;
echo 'written by: ' . $book->author->name; // $book->author je řádek z tabulky 'author'
echo 'tags: ';
foreach ($book->related('book_tag') as $bookTag) {
echo $bookTag->tag->name . ', '; // $bookTag->tag je řádek z tabulky 'tag'
}
}
Příjemně vás překvapí, jak efektivně databázová vrstva pracuje. Výše uvedený příklad provede konstantní počet požadavků, které vypadají takto:
SELECT * FROM `book`
SELECT * FROM `author` WHERE (`author`.`id` IN (11, 12))
SELECT * FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 4, 2, 3))
SELECT * FROM `tag` WHERE (`tag`.`id` IN (21, 22, 23))
Pokud použijete cache (ve výchozím nastavení je zapnutá), nebudou z databáze načítány žádné nepotřebné sloupce. Po prvním dotazu se do cache uloží jména použitých sloupců a dále budou z databáze vybírány pouze ty sloupce, které skutečně použijete:
SELECT `id`, `title`, `author_id` FROM `book`
SELECT `id`, `name` FROM `author` WHERE (`author`.`id` IN (11, 12))
SELECT `book_id`, `tag_id` FROM `book_tag` WHERE (`book_tag`.`book_id` IN (1, 4, 2, 3))
SELECT `id`, `name` FROM `tag` WHERE (`tag`.`id` IN (21, 22, 23))
Výběry
Podívejme se na možnosti filtrování a omezování výběru pomocí třídy Nette\Database\Table\Selection:
$table->where($where[, $param[, ...]]) |
Nastaví WHERE s použitím AND jako spojovatele při více než jedné podmínce |
$table->whereOr($where) |
Nastaví WHERE s použitím OR jako spojovatele při více než jedné podmínce |
$table->order($columns) |
Nastaví ORDER BY, může být výraz ('column DESC, id DESC') |
$table->select($columns) |
Nastaví vrácené sloupce, může být výraz ('col, MD5(col) AS hash') |
$table->limit($limit[, $offset]) |
Nastaví LIMIT a OFFSET |
$table->page($page, $itemsPerPage[, &$lastPage]) |
Nastaví stránkování |
$table->group($columns) |
Nastaví GROUP BY |
$table->having($having) |
Nastaví HAVING |
Můžeme použít tzv. fluent interface,
například $table->where(...)->order(...)->limit(...). Vícenásobné where nebo
whereOr podmínky je spojeny operátorem AND.
where()
Nette Database Explorer automaticky přidá vhodné operátory podle toho, jaká data dostane:
$table->where('field', $value) |
field = $value |
$table->where('field', null) |
field IS NULL |
$table->where('field > ?', $val) |
field > $val |
$table->where('field', [1, 2]) |
field IN (1, 2) |
$table->where('id = ? OR name = ?', 1, $name) |
id = 1 OR name = ‚Jon Snow‘ |
$table->where('field', $explorer->table($tableName)) |
field IN (SELECT $primary FROM $tableName) |
$table->where('field', $explorer->table($tableName)->select('col')) |
field IN (SELECT col FROM $tableName) |
Zástupný symbol (otazník) funguje i bez sloupcového operátoru. Následující volání jsou stejná:
$table->where('id = ? OR id = ?', 1, 2);
$table->where('id ? OR id ?', 1, 2);
Díky tomu lze generovat správný operátor na základě hodnoty:
$table->where('id ?', 2); // id = 2
$table->where('id ?', null); // id IS NULL
$table->where('id', $ids); // id IN (...)
Selection správně zpracovává i záporné podmínky a umí pracovat také s prázdnými poli:
$table->where('id', []); // id IS NULL AND FALSE
$table->where('id NOT', []); // id IS NULL OR TRUE
$table->where('NOT (id ?)', $ids); // NOT (id IS NULL AND FALSE)
// toto způsobí výjimku, tato syntax není podporovaná
$table->where('NOT id ?', $ids);
whereOr()
Příklad použití bez parametrů:
// WHERE (user_id IS NULL) OR (SUM(`field1`) > SUM(`field2`))
$table->whereOr([
'user_id IS NULL',
'SUM(field1) > SUM(field2)',
]);
Použijeme parametry. Pokud neuvedeme operátor, Nette Database Explorer automaticky přidá vhodný:
// WHERE (`field1` IS NULL) OR (`field2` IN (3, 5)) OR (`amount` > 11)
$table->whereOr([
'field1' => null,
'field2' => [3, 5],
'amount >' => 11,
]);
V klíči lze uvést výraz obsahující zástupné otazníky a v hodnotě pak předáme parametry:
// WHERE (`id` > 12) OR (ROUND(`id`, 5) = 3)
$table->whereOr([
'id > ?' => 12,
'ROUND(id, ?) = ?' => [5, 3],
]);
order()
Příklady použití:
$table->order('field1'); // ORDER BY `field1`
$table->order('field1 DESC, field2'); // ORDER BY `field1` DESC, `field2`
$table->order('field = ? DESC', 123); // ORDER BY `field` = 123 DESC
select()
Příklady použití:
$table->select('field1'); // SELECT `field1`
$table->select('col, UPPER(col) AS abc'); // SELECT `col`, UPPER(`col`) AS abc
$table->select('SUBSTR(title, ?)', 3); // SELECT SUBSTR(`title`, 3)
limit()
Příklady použití:
$table->limit(1); // LIMIT 1
$table->limit(1, 10); // LIMIT 1 OFFSET 10
page()
Alternativní způsob pro nastavení limitu a offsetu:
$page = 5;
$itemsPerPage = 10;
$table->page($page, $itemsPerPage); // LIMIT 10 OFFSET 40
Získání čísla poslední stránky, předá se do proměnné $lastPage:
$table->page($page, $itemsPerPage, $lastPage);
group()
Příklady použití:
$table->group('field1'); // GROUP BY `field1`
$table->group('field1, field2'); // GROUP BY `field1`, `field2`
having()
Příklady použití:
$table->having('COUNT(items) >', 100); // HAVING COUNT(`items`) > 100
Výběry hodnotou z jiné tabulky
Často potřebujeme filtrovat výsledky pomocí podmínky, která zahrnuje jinou databázovou tabulku. Tento typ podmínek vyžaduje spojení tabulek, s Nette Database Explorer už je ale nikdy nemusíme psát ručně.
Řekněme, že chceme vybrat všechny knihy, které napsal autor jménem Jon. Musíme napsat pouze jméno
spojovacího klíče relace a název sloupce spojené tabulky. Spojovací klíč je odvozen od jména sloupce, který odkazuje na
tabulku, se kterou se chceme spojit. V našem příkladu (viz databázové schéma) je to sloupec author_id, ze
kterého stačí použít část – author. name je název sloupce v tabulce author.
Můžeme vytvořit podmínku také pro překladatele knihy, který je připojen sloupcem translator_id.
$books = $explorer->table('book');
$books->where('author.name LIKE ?', '%Jon%');
$books->where('translator.name', 'David Grudl');
Logika vytváření spojovacího klíče je dána implementací Conventions. Doporučujeme použití DiscoveredConventions, které analyzuje cizí klíče a umožňuje jednoduše pracovat se vztahy mezi tabulkami.
Vztah mezi knihou a autorem je 1:N. Obrácený vztah je také možný, nazýváme ho backjoin. Podívejme se na
následující příklad. Chceme vybrat všechny autory, kteří napsali více než tři knihy. Pro vytvoření obráceného
spojení použijeme : (dvojtečku). Dvojtečka znamená, že jde o vztah hasMany (a je to logické, dvě tečky jsou
více než jedna). Bohužel třída Selection není dostatečně chytrá a musíme mu pomoci s agregací výsledků a předat mu
část GROUP BY, také podmínka musí být zapsaná jako HAVING.
$authors = $explorer->table('author');
$authors->group('author.id')
->having('COUNT(:book.id) > 3');
Možná jste si všimli, že spojovací výraz odkazuje na book, ale není jasné, jestli spojujeme přes
author_id nebo translator_id. Ve výše uvedeném příkladu Selection spojuje přes sloupec
author_id, protože byla nalezena shoda se jménem zdrojové tabulky – tabulky author. Pokud by
neexistovala shoda a existovalo více možností, Nette vyhodí výjimku AmbiguousReferenceKeyException.
Abychom mohli spojovat přes translator_id, stačí přidat volitelný parametr do spojovacího výrazu.
$authors = $explorer->table('author');
$authors->group('author.id')
->having('COUNT(:book(translator).id) > 3');
Teď se podívejme na složitější příklad na skládání tabulek.
Chceme vybrat všechny autory, kteří napsali něco o PHP. Všechny knihy mají štítky, takže chceme vybrat všechny autory, kteří napsali knihu se štítkem ‚PHP‘.
$authors = $explorer->table('author');
$authors->where(':book:book_tags.tag.name', 'PHP')
->group('author.id')
->having('COUNT(:book:book_tags.tag.id) > 0');
Agregace výsledků
$table->count('*') |
Vrátí počet řádků |
$table->count("DISTINCT $column") |
Vrátí počet odlišných hodnot |
$table->min($column) |
Vrátí minimální hodnotu |
$table->max($column) |
Vrátí maximální hodnotu |
$table->sum($column) |
Vrátí součet všech hodnot |
$table->aggregation("GROUP_CONCAT($column)") |
Pro jakoukoliv jinou agregační funkci |
Metoda count() bez uvedeného parametru vybere všechny záznamy a vrátí velikost pole, což je
velmi neefektivní. Pokud potřebujete například spočítat počet řádků pro stránkování, vždy první argument
uveďte.
Escapování a uvozovky
Database Explorer umí chytře escapovat parametry a identifikátory. Pro správnou funkčnost je ale nutno dodržovat několik pravidel:
- klíčová slova, názvy funkcí, procedur apod. psát velkými písmeny
- názvy sloupečků a tabulek psát malými písmeny
- hodnoty dosazovat přes parametry
->where('name like ?', 'John'); // ŠPATNĚ! vygeneruje: `name` `like` ?
->where('name LIKE ?', 'John'); // SPRÁVNĚ
->where('KEY = ?', $value); // ŠPATNĚ! KEY je klíčové slovo
->where('key = ?', $value); // SPRÁVNĚ. vygeneruje: `key` = ?
->where('name = ' . $name); // ŠPATNĚ! sql injection!
->where('name = ?', $name); // SPRÁVNĚ
->select('DATE_FORMAT(created, "%d.%m.%Y")'); // ŠPATNĚ! hodnoty dosazujeme přes parametr
->select('DATE_FORMAT(created, ?)', '%d.%m.%Y'); // SPRÁVNĚ
Špatné použití může vést k bezpečnostním dírám v aplikaci.
Čtení dat
foreach ($table as $id => $row) |
Iteruje přes všechny řádky výsledku |
$row = $table->get($id) |
Vrátí jeden řádek s ID $id |
$row = $table->fetch() |
Vrátí další řádek výsledku |
$array = $table->fetchPairs($key, $value) |
Vrátí všechny výsledky jako asociativní pole |
$array = $table->fetchPairs($key) |
Vrátí všechny řádky jako asociativní pole |
count($table) |
Vrátí počet řádků výsledku |
Insert, Update & Delete
Metoda insert() přijímá pole nebo Traversable objekty (například ArrayHash se kterým pracují formuláře):
$row = $explorer->table('users')->insert([
'name' => $name,
'year' => $year,
]);
// INSERT INTO users (`name`, `year`) VALUES ('Jim', 1978)
Má-li tabulka definovaný primární klíč, vrací nový řádek jako objekt ActiveRow.
Vícenásobný insert:
$explorer->table('users')->insert([
[
'name' => 'Jim',
'year' => 1978,
], [
'name' => 'Jack',
'year' => 1987,
],
]);
// INSERT INTO users (`name`, `year`) VALUES ('Jim', 1978), ('Jack', 1987)
Jako parametry můžeme předávat i soubory nebo objekty DateTime:
$explorer->table('users')->insert([
'name' => $name,
'created' => new DateTime, // nebo $explorer::literal('NOW()')
'avatar' => fopen('image.gif', 'r'), // vloží soubor
]);
Úprava záznamů (vrací počet změněných řádků):
$count = $explorer->table('users')
->where('id', 10) // musí se volat před update()
->update([
'name' => 'Ned Stark'
]);
// UPDATE `users` SET `name`='Ned Stark' WHERE (`id` = 10)
Pro update můžeme využít operátorů += a -=:
$explorer->table('users')
->update([
'age+=' => 1, // všimněte si +=
]);
// UPDATE users SET `age` = `age` + 1
Mazání záznamů (vrací počet smazaných řádků):
$count = $explorer->table('users')
->where('id', 10)
->delete();
// DELETE FROM `users` WHERE (`id` = 10)
Vazby mezi tabulkami
Relace Has one
Relace has one je velmi běžná. Kniha má jednoho autora. Kniha má jednoho překladatele. Řádek, který
je ve vztahu has one získáme pomocí metody ref(). Ta přijímá dva argumenty: jméno cílové tabulky a název
spojovacího sloupce. Viz příklad:
$book = $explorer->table('book')->get(1);
$book->ref('author', 'author_id');
V příkladu výše vybíráme souvisejícího autora z tabulky author. Primární klíč tabulky
author je hledán podle sloupce book.author_id. Metoda ref() vrací instanci
ActiveRow nebo null, pokud hledaný záznam neexistuje. Vrácený řádek je instance
ActiveRow, takže s ním můžeme pracovat stejně jako se záznamem knihy.
$author = $book->ref('author', 'author_id');
$author->name;
$author->born;
// nebo přímo
$book->ref('author', 'author_id')->name;
$book->ref('author', 'author_id')->born;
Kniha má také jednoho překladatele, jeho jméno získáme snadno.
$book->ref('author', 'translator_id')->name
Tento přístup je funkční, ale pořád trochu zbytečně těžkopádný, nemyslíte? Databáze už obsahuje definice cizích klíčů, tak proč je nepoužít automaticky. Pojďme to vyzkoušet.
Pokud přistoupíme k členské proměnné, která neexistuje, ActiveRow se pokusí použít jméno této proměnné pro
relaci ‚has one‘. Čtení této proměnné je stejné jako volání metody ref() pouze s jedním parametrem.
Tomuto parametru budeme říkat klíč. Tento klíč bude použit pro vyhledání cizího klíče v tabulce. Předaný
klíč je porovnán se sloupci, a pokud odpovídá pravidlům, je cizí klíč na daném sloupci použit pro čtení dat
z příbuzné tabulky. Viz příklad:
$book->author->name;
// je stejné jako
$book->ref('author')->name;
Instance ActiveRow nemá žádný sloupec author. Všechny sloupce tabulky book jsou prohledány na
shodu s klíčem. Shoda v tomto případě znamená, že jméno sloupce musí obsahovat klíč. V příkladu výše
sloupec author_id obsahuje řetězec ‚author‘ a tedy odpovídá klíči ‚author‘. Pokud chceme přistoupit
k záznamu překladatele, obdobným způsobem použijeme klíč ‚translator‘, protože bude odpovídat sloupci
translator_id. Více o logice párování klíčů si můžete přečíst v části Joining expressions.
echo $book->title . ': ';
echo $book->author->name;
if ($book->translator) {
echo ' (translated by ' . $book->translator->name . ')';
}
Pokud chceme získat autora více knih, použijeme stejný přístup. Nette Database Explorer vybere z databáze záznamy autorů a překladatelů pro všechny knihy najednou.
$books = $explorer->table('book');
foreach ($books as $book) {
echo $book->title . ': ';
echo $book->author->name;
if ($book->translator) {
echo ' (translated by ' . $book->translator->name . ')';
}
}
Tento kód zavolá pouze tyto tři dotazy do databáze:
SELECT * FROM `book`;
SELECT * FROM `author` WHERE (`id` IN (1, 2, 3)); -- id ze sloupce author_id vybraných knih
SELECT * FROM `author` WHERE (`id` IN (2, 3)); -- id ze sloupce translator_id vybraných knih
Relace Has many
Relace ‚has many‘ je pouze obrácená ‚has one‘ relace. Autor napsal několik (many) knih. Autor přeložil
několik (many) knih. Tento typ relace je obtížnější, protože vztah je pojmenovaný (‚napsal‘, ‚přeložil‘).
ActiveRow má metodu related(), která vrací pole souvisejících záznamů. Záznamy jsou opět instance ActiveRow.
Viz příklad:
$author = $explorer->table('author')->get(11);
echo $author->name . ' napsal:';
foreach ($author->related('book.author_id') as $book) {
echo $book->title;
}
echo 'a přeložil:';
foreach ($author->related('book.translator_id') as $book) {
echo $book->title;
}
Metoda related() přijímá popis spojení jako dva argumenty, nebo jako jeden argument spojený tečkou. První
argument je cílová tabulka, druhý je sloupec.
$author->related('book.translator_id');
// je stejné jako
$author->related('book', 'translator_id');
Můžeme použít heuristiku Nette Database Explorer založenou na cizích klíčích a použít pouze klíč. Klíč
bude porovnán s cizími klíči, které odkazují do aktuální tabulky (tabulka author). Pokud je nalezena shoda,
Nette Database Explorer použije tento cizí klíč, v opačném případě vyhodí výjimku Nette\InvalidArgumentException nebo AmbiguousReferenceKeyException.
Více o logice párování klíčů si můžete přečíst v části Joining expressions.
Metodu related() může samozřejmě volat na všechny získané autory a Nette Database Explorer načte všechny
odpovídající knihy najednou.
$authors = $explorer->table('author');
foreach ($authors as $author) {
echo $author->name . ' napsal:';
foreach ($author->related('book') as $book) {
$book->title;
}
}
Příklad uvedený výše spustí pouze tyto dva dotazy do databáze:
SELECT * FROM `author`;
SELECT * FROM `book` WHERE (`author_id` IN (1, 2, 3)); -- id vybraných autorů
Ruční vytvoření Explorer
Pokud jsme si vytvořili databázové spojení pomocí aplikační konfigurace, nemusíme se o nic starat. Vytvořila se nám
totiž i služba typu Nette\Database\Explorer, kterou si můžeme předat pomocí DI.
Pokud ale používáme Nette Database Explorer samostatně, musíme instanci Nette\Database\Explorer
vytvořit ručně.
// $storage obsahuje implementaci Nette\Caching\Storage, např.:
$storage = new Nette\Caching\Storages\FileStorage($tempDir);
$connection = new Nette\Database\Connection($dsn, $user, $password);
$structure = new Nette\Database\Structure($connection, $storage);
$conventions = new Nette\Database\Conventions\DiscoveredConventions($structure);
$explorer = new Nette\Database\Explorer($connection, $structure, $conventions, $storage);